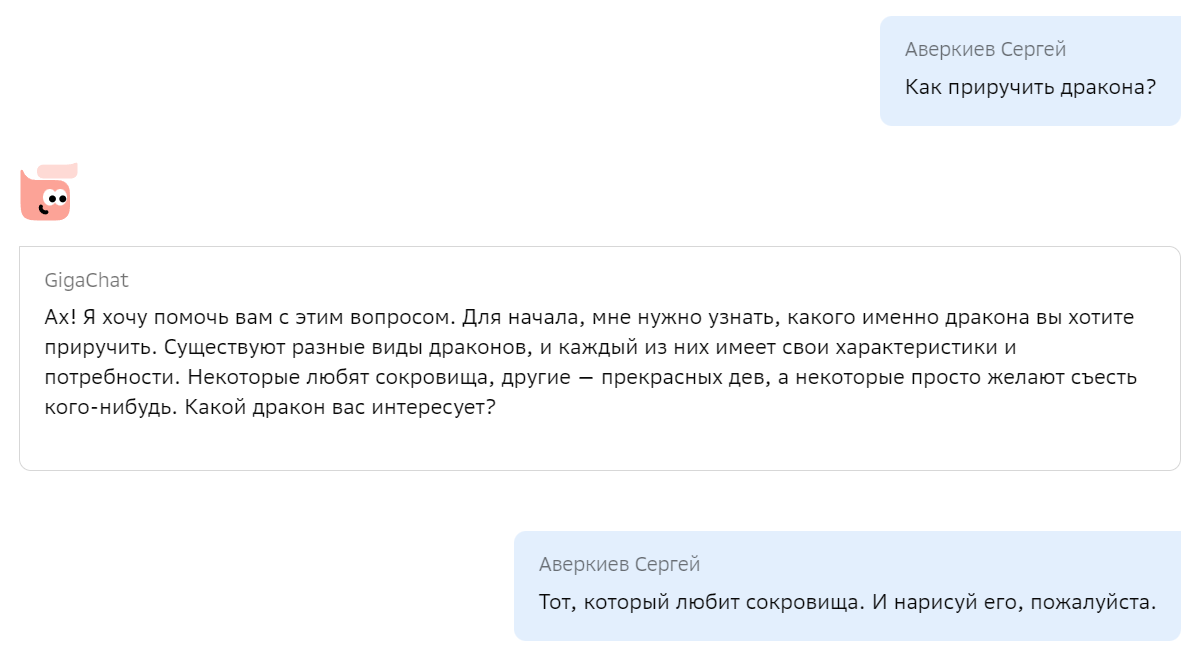
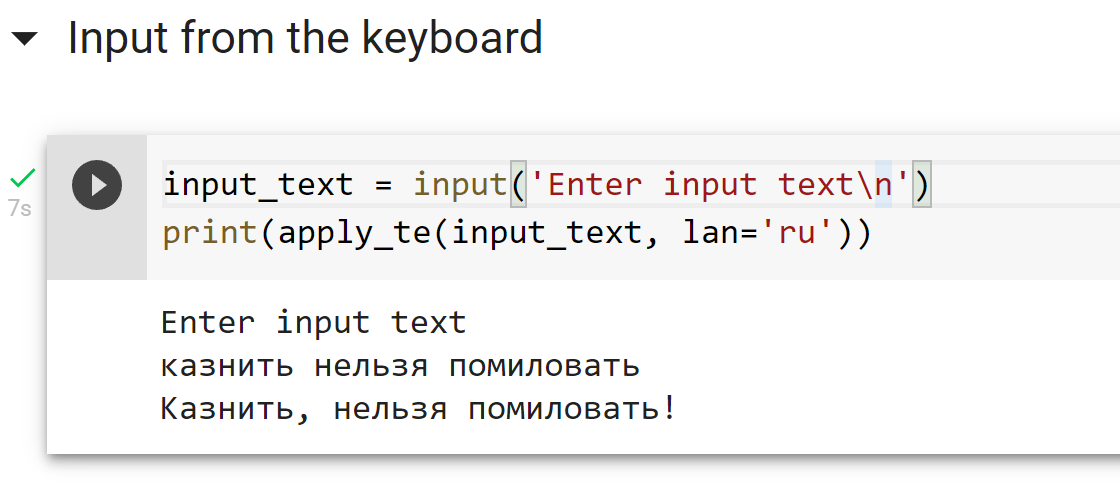
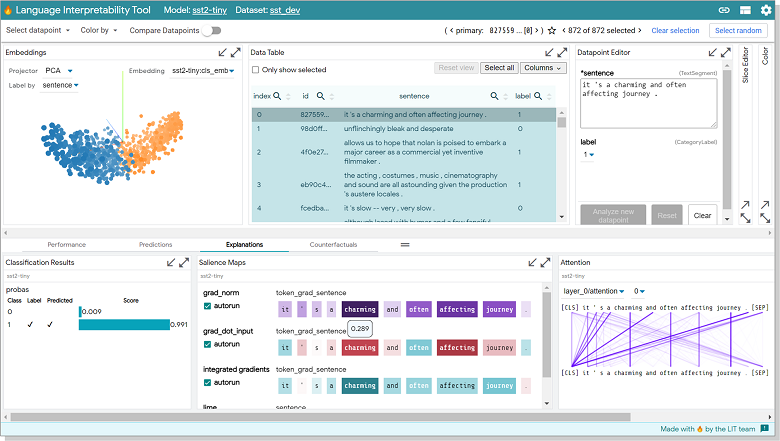
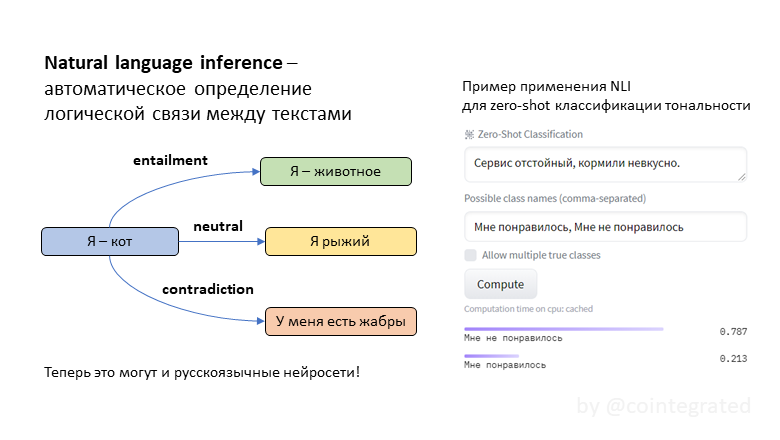
Всем привет! Недавно я на практике применил одно интересное решение, которое давно хотел попробовать, и теперь готов рассказать, как своими руками такое можно сделать для любой другой аналогичной задачи. Речь пойдет о создании своей кастомизированной версии ChatGPT, которая отвечает на вопросы, учитывая большую базу знаний, которая по длине не ограничивается размером промта (то есть вы бы не смогли просто добавить всю информацию перед каждым вопросом к ChatGPT). Для этого будем использовать контекстные эмбеддинги от OpenAI (для действительно качественного поиска релеватных вопросов из базы знаний) и сам СhatGPT API (для оборачивания ответов в натуральный человеческие ответы). При этом, также предполагается, что ассистент может отвечать не только на прямо указанные в Q&A вопросы, но и на такие вопросы, на которые смог бы отвечать человек, который ознакомился с Q&A. Кому интересно научиться делать простых ботов, отвечающих по большой базе знаний, добро пожаловать под кат.