Математику было достаточно просто изучить?
Я услышал множество хороших отзывов о книге Calculus Made Easy by Silvanus P. Thompson. Начал читать и правда, это была самая простая книжка на английском, которую я читал (советую попробовать почитать в оригинале), причем понял лучше, чем на родном языке.
Но зачем ее читать взрослым людям, знакомым с математикой не понаслышке?
В этом вопросе все просто: наверняка у многих уже есть дети или скоро будут, поэтому прививать любовь к знаниям и науке нужно с малых лет, иначе школа с их скупым языком испортит у ребенка все желание тянуться к прекрасному.
Но это не только для детей книга. Взрослым может посмотреть, а тому ли его учили в школе и не перепутал он ничего из-за долгих лет планирования бизнес-логики.
Особенно поможет людям, которые мечтали стать хардкорными "дата-сатанисами" и прочими гениями современности, но как-то все не складывалось. Для множества тестеров, эйчаров, проект менеджеров, кто нашел себя в айти, но хочет еще развиваться.
Перевод довольно вольный, я не профессиональный переводчик и даже не учился в MIT, но постарался предать максимально понятно и близко к смыслу текста. Приму ваши замечания к сведению. Перевел тестовый кусок, чтобы понять интересно ли вам такое, чтобы замотивироваться. Первый кусочек принадлежит кому-то, кто написал вводную книги, а второй оригинальному автору, что еще интереснее и забавнее. Ну что, полетели.


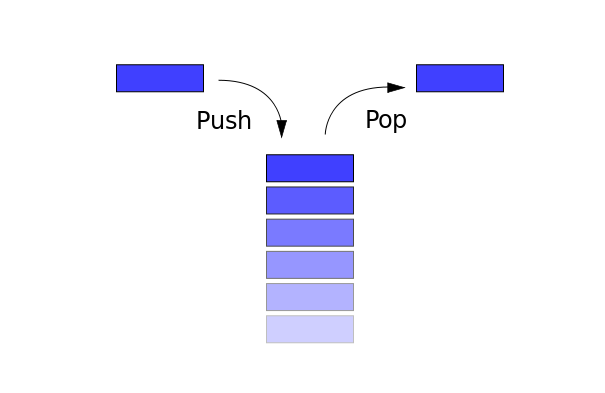
 методики FAANG — по этой причине практически во всех IT-собесах есть она: секция алгоритмов. Кто-то ей рад, кто-то не очень, но секция есть и уходить пока не планирует. Поэтому нужно закатать рукава и достойно встретить суровую реальность.
методики FAANG — по этой причине практически во всех IT-собесах есть она: секция алгоритмов. Кто-то ей рад, кто-то не очень, но секция есть и уходить пока не планирует. Поэтому нужно закатать рукава и достойно встретить суровую реальность.