
Привет, Хабр! В статье подробно рассмотрим область применения самого базового статистического критерия Стьюдента. Посмотрим, как он ведёт себя, когда мы не хотим отдавать качество подбора наших групп на волю случая.

Скромный пастух нулей и единиц…
Привет, Хабр! В статье подробно рассмотрим область применения самого базового статистического критерия Стьюдента. Посмотрим, как он ведёт себя, когда мы не хотим отдавать качество подбора наших групп на волю случая.

Привет, Хабр. Сегодняшняя статья будет интересна тем, кто хочет собрать простой OLAP‑куб для анализа данных, чтобы понять, как он устроен и работает. Экспериментировать будем с помощью TinyOLAP, одного из немногих OpenSource движков на Python.
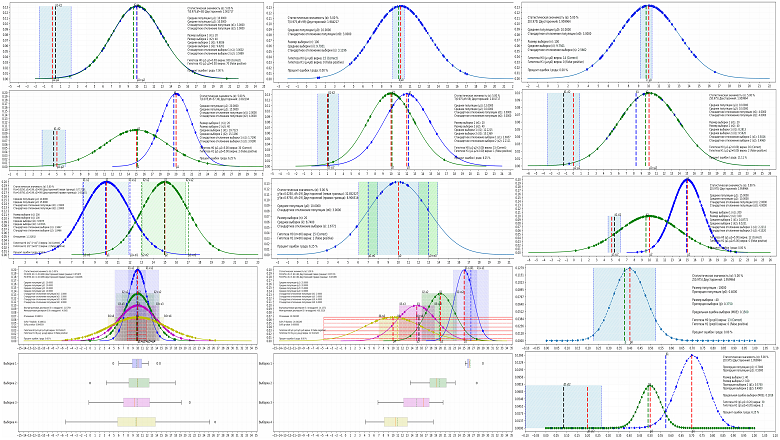
Одной из самых распространённых задач аналитики является формирование суждений о большой совокупности (например, о миллионах пользователей приложения), опираясь на данные лишь небольшой части этой совокупности - выборке. Можно ли сделать вывод о миллионной аудитории крупного мобильного приложения, собрав данные 100 пользователей? Или стоит собрать данные о 1000 пользователях? Какую вероятность ошибиться при анализе мы можем допустить: 5% или 1%? Относятся ли две выборки к одной совокупности, или между ними есть ощутимая значимая разница и они относятся к разным совокупностям? Точность прогноза и вероятность ошибки при ответе на эти и другие вопросы поддаются вполне конкретным расчётам и могут корректироваться в зависимости от потребностей продукта и бизнеса на этапе планирования и подготовки эксперимента. Рассмотрим подробнее, как параметры эксперимента и статистические критерии оказывают влияние на результаты анализа и выводы обо всей совокупности, а для этого смоделируем тысячу A/A, A/B и A/B/C/D тестов.
В этом посте:

Всем привет! Меня зовут Виктор, я DevOps‑инженер компании Nixys, которая помогает другим компаниям внедрять в их IT‑решения передовые практики DevOps, MLOps и DevSecOps.
Сегодня я приглашаю вас вместе со мной пройти путь «от незнания к best practices» в работе с Terraform. Этот материал подготовлен для серии наших одноименных видеороликов на YouTube, но мы решили дополнить его и предложить вам более детальное описание процесса в этой статье.
Не забывайте следить за нашими обновлениями на YouTube, Habr и подписывайтесь на наш Telegram‑канал DevOps FM — мы всегда рады новым друзьям. Начнём?

Работа с pandas.DataFrame может превратиться в неловкую кучу старого (не очень) доброго спагетти-кода. Я и мои коллеги часто используем эту библиотеку, и хотя мы стараемся придерживаться хороших практик программирования, иногда мы все равно мешаем друг другу, создавая запутанный код.
Я собрала несколько советов и подводных камней, которых следует избегать, чтобы сделать код на pandas чистым. Надеюсь, вам они тоже будут полезны. Также я буду ссылаться на классическую книгу Роберта Мартина «Чистый код: создание, анализ и рефакторинг».
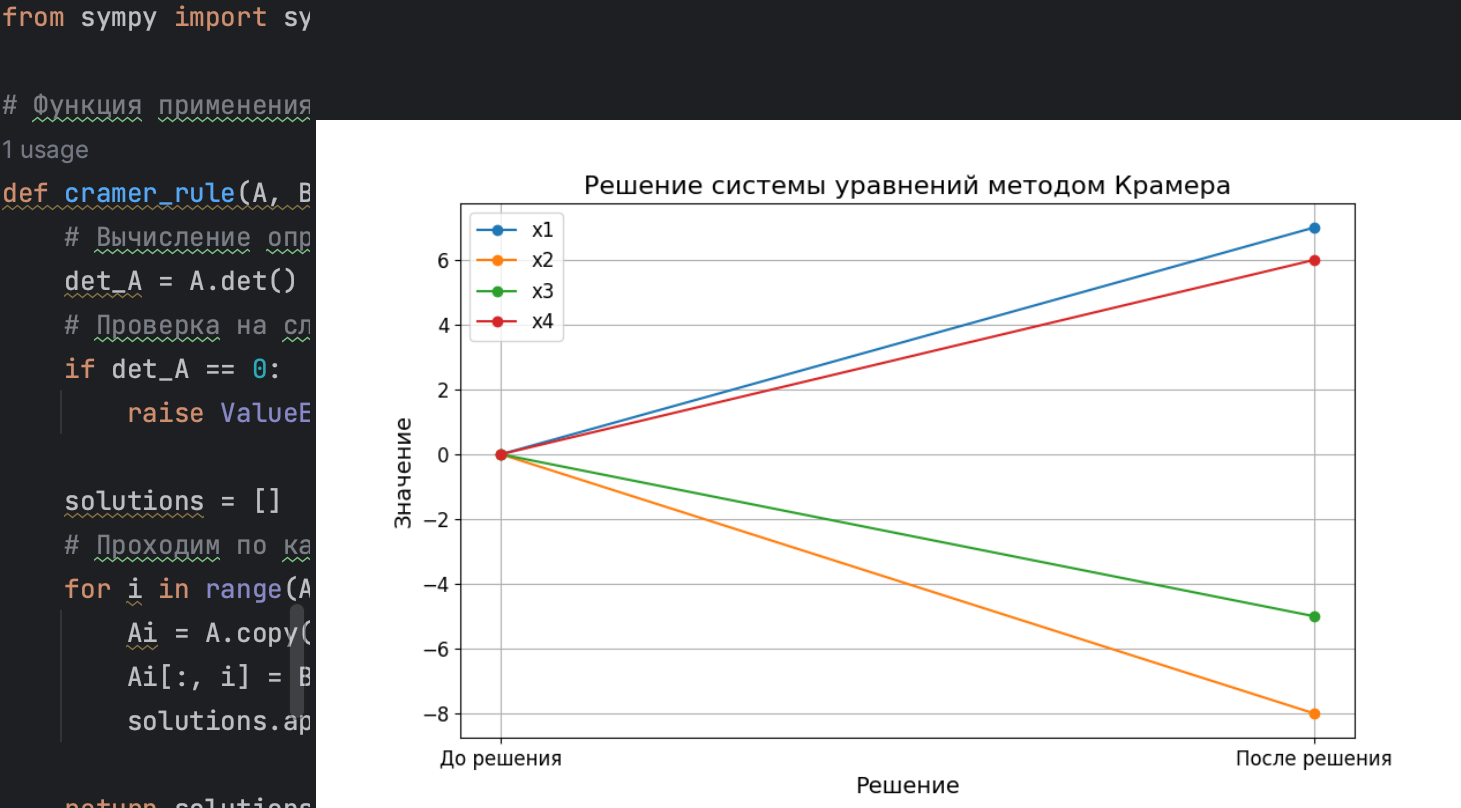
Как‑то я наткнулась на статью, где говорилось о SymPy, а именно о возможности решения систем уравнений с ее помощью. Если кратко, то это бесплатная библиотека для символьных вычислений на языке Python. В символьных вычислениях компьютер работает с уравнениями и выражениями как с последовательностью символов, тогда как в численных оперирует приближёнными числовыми значениями.
И поскольку линейные уравнения встречаются не только в математике, а также и в физике, и в ифнформатике, и во многих других областях, мне бы хотелось рассмотреть возможность их решения с Python.
Приятного прочтения )
Привет! Меня зовут Александр Ежков, я Backend-разработчик в AGIMA. Занимаюсь созданием и поддержкой внутренних сервисов для компании. А конкретно сейчас — нашей DWH-системой. Мы построили ее из Open-source продуктов. В этой статье расскажу, какие продукты мы используем, какие хитрости придумали для работы с ними как вся система работает вместе.
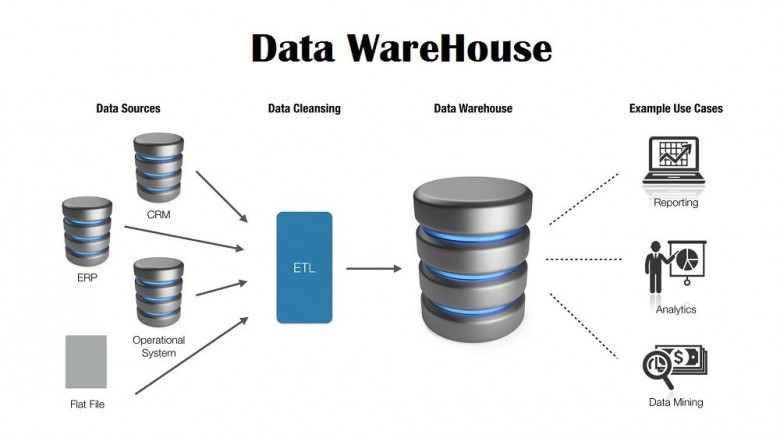
Хранилище данных — это информационная система, в которой хранятся исторические и коммутативные данные из одного или нескольких источников. Он предназначен для анализа, составления отчетов и интеграции данных транзакций из разных источников.
Рассмотрим сильные и слабые стороны самых популярных методологий.

Привет, Хабр. Я продолжаю рассказывать про неизвестные широкому кругу разработчиков CSS-фишки. Я отбираю их так, чтобы они были полезны в разного рода проектах. Неважно, верстаете ли вы сайт для малого бизнеса или создаёте супермодное React-приложение. Они поддерживаются большинством браузеров. Отдельно отмечу, что я не считаю IE11 современным браузером. По этой причине я не учитывал его.
Сегодня мы рассмотрим:
image-set();:focus-within при вёрстке кастомных чекбоксов;Больше не буду затягивать. Давайте посмотрим, что я вам подготовил.

Конечная цель проектов импортозамещения в ИТ — полный отказ от операционной системы Windows. Но, как говорится, гладко было на бумаге, да забыли про овраги. Может так оказаться, что быстро заменить какие-то клиентские корпоративные приложения, написанные под эту операционную систему, не получится. В этом случае вам может пригодиться возможность присоединения Windows-компьютеров к домену ALD Pro.
В этой статье я расскажу, как добиться максимальной функциональности от такого сценария развертывания, и презентую утилиту нашей собственной разработки aldpro-join. С ее помощью можно решить проблему настройки рабочих станций всего за пару кликов. Если это именно то, о чем вы хотели узнать, но не знали, кого спросить, — вы на правильном пути. Поехали!
Материал будет полезен даже в том случае, если в вашей инфраструктуре пока еще используется «ванильная» система FreeIPA.

Айтишный труд опасен: можно отравиться соевым латте, словить инфаркт от правок и подраться на корпоративе. Можем ли мы рассчитывать на помощь коллег в случае ЧП? Пока вы врубаете VPN, чтобы спросить совета у ChatGPT, ваш коллега отправится на тот свет.
В этой статье разобрали несчастные случаи, которые могут настигнуть вас в офисе. Рассказываем, что нужно сделать в таких ситуациях (и что делать ни в коем случае нельзя). Кстати, ВОЗ говорит, что на рабочем месте ежегодно умирает до 600 000 человек.

В Отусе я прошла курс ML Advanced и открыла для себя интересные темы, связанные с анализом временных рядов, а именно, их сегментацию и кластеризацию. Я решила позаимствовать полученные знания для своей дипломной университетской работы по ивент-анализу социальных явлений и событий и описать часть этого исследования в данной статье.
Шаг 1. Сбор данных
В качестве источника данных я взяла информационно-новостной ресурс Лента.ру, так как с него легко парсить данные, новости разнообразны и пополняются в большом объеме ежедневно. Для теста я спарсила новости за последний год (март 2023 – март 2024) с помощью питоновских BeautifulSoup и requests.
В коде происходит процедура сбора заголовка, даты и тематики новостей:
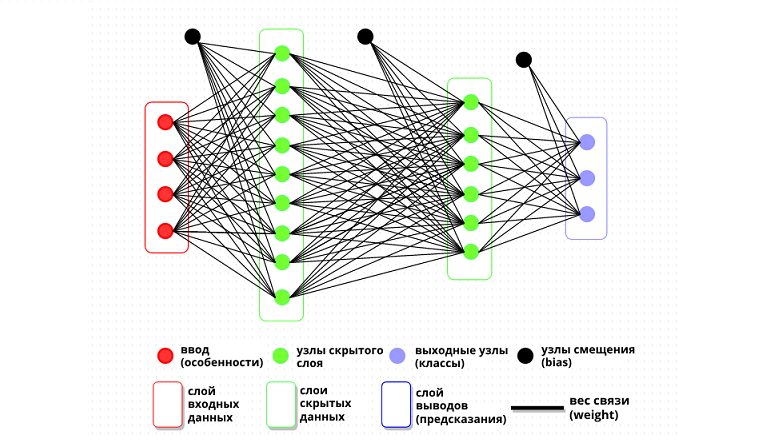
Это модное слово всё чаще используется в разговорной речи: обывателей плотнее окутывают угрозами бунта искусственного интеллекта и войны с роботами — с одной стороны, и рекламой нейросетевых продуктов — с другой. Отдельный котёл в аду — для тех, кто впаривает «курсы дата‑саентистов». А когда бедный юзернейм в поисках истины обращается к Гуглу своему любимому поисковику — то вместо простого ответа на простой вопрос, получает ещё больше вопросов — таких как тензорфлоу, сигмоида и, не дай Бог, линейная алгебра.

В этой статье мы рассмотрим, как настроить пайплайн CI/CD в GitHub: подготовим репозиторий, зальём туда приложение, создадим файлы конфигурации GitHub Actions, в которых опишем, как собирать наше приложение и деплоить его в кластер Kubernetes, развёрнутый под управлением Deckhouse Kubernetes Platform. Деплоить будем с помощью Open Source CLI-утилиты werf. Она помогает организовать полный цикл доставки приложений в Kubernetes и рассматривает Git как единый источник истины для состояния развёрнутого приложения. Статья рассчитана на тех, кто только начинает свой путь в мире облаков и кластеризации.


Линейный дискриминантный анализ (Linear Discriminant Analysis или LDA) — алгоритм классификации и понижения размерности, позволяющий производить разделение классов наилучшим образом. Основная идея LDA заключается в предположении о многомерном нормальном распределении признаков внутри классов и поиске их линейного преобразования, которое максимизирует межклассовую дисперсию и минимизирует внутриклассовую. Другими словами, объекты разных классов должны иметь нормальное распределение и располагаться как можно дальше друг от друга, а одного класса — как можно ближе.

Наивный байесовский классификатор (Naive Bayes classifier) — вероятностный классификатор на основе формулы Байеса со строгим (наивным) предположением о независимости признаков между собой при заданном классе, что сильно упрощает задачу классификации из-за оценки одномерных вероятностных плотностей вместо одной многомерной.
Помимо теории и реализации с нуля на Python, в данной статье также будет приведён небольшой пример использования наивного Байеса в контексте фильтрации спама со всеми подробными расчётами вручную.