Начало здесь: Конференция HOPE X. «Взлом лифта: от подвала до пентхауза». Часть 1. «Лифтовое оборудованиe»
Дивиант Оллам: можно сказать, что в многих отношениях лифтовая индустрия застряла в прошлом.

Говард Пейн: на этом слайде показана лифтовая кабина в одном казино. Я встречался с архитектором этого казино, который разрабатывал решения для всего здания, включая лифты. Я отчётливо помню, как он рассказывал мне о выборе компонентов системы безопасности лифтов и сказал, что никто не сможет её взломать, потому что они использовали антикражные трубчатые замки.
Дивиант Оллам: то есть он считал, что трубчатые замки являются новейшей и величайшей разработкой в сфере безопасности.
Дивиант Оллам: можно сказать, что в многих отношениях лифтовая индустрия застряла в прошлом.
Говард Пейн: на этом слайде показана лифтовая кабина в одном казино. Я встречался с архитектором этого казино, который разрабатывал решения для всего здания, включая лифты. Я отчётливо помню, как он рассказывал мне о выборе компонентов системы безопасности лифтов и сказал, что никто не сможет её взломать, потому что они использовали антикражные трубчатые замки.
Дивиант Оллам: то есть он считал, что трубчатые замки являются новейшей и величайшей разработкой в сфере безопасности.




 Хочу признаться: я обожаю визуальные новеллы. Кто не в курсе — это такие то ли интерактивные книжки, то ли игры-в-которых-надо-в-основном-читать-текст, то ли радиоспектакли-с-картинками, преимущественно японские. Последние лет 5, наверное, художественную литературу в другом формате толком не вопринимаю: у визуальных новелл по сравнению с бумажными книгами, аудио-книгами и даже сериалами — в разы большее погружение, да и сюжет регулярно куда интереснее.
Хочу признаться: я обожаю визуальные новеллы. Кто не в курсе — это такие то ли интерактивные книжки, то ли игры-в-которых-надо-в-основном-читать-текст, то ли радиоспектакли-с-картинками, преимущественно японские. Последние лет 5, наверное, художественную литературу в другом формате толком не вопринимаю: у визуальных новелл по сравнению с бумажными книгами, аудио-книгами и даже сериалами — в разы большее погружение, да и сюжет регулярно куда интереснее.
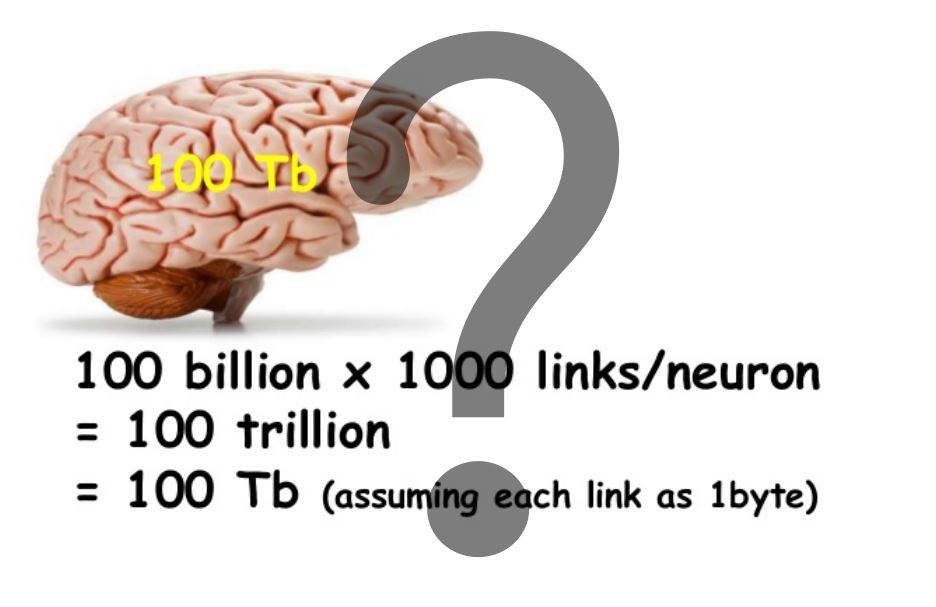 Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.
Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.

 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.