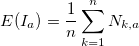Пару недель назад, наша команда
выпустила свежий релиз
FlyElephant — платформа для ученых, которая предоставляет готовую вычислительную инфраструктуру для проведения расчетов, помогает находить партнеров и совместно работать над проектами, а также управлять всеми данными из одного места.
В качестве вычислительного ресурса сейчас используется облако Azure, а пользователи могут запускать вычислительные задачи, написанные с помощью С++ (с поддержкой OpenMP), R, Python, Octave, Scilab, Java, Julia, OpenFOAM, GROMACS, Blender на серверах с количеством ядер от 1 до 32 и оперативной памятью до 448 ГБ.
Сегодня мы хотим поделиться
видео-туториалсами запуска задач во FlyElephant. Под катом вы найдете видео, как запускать вычислительные задачи, написанные с помощью С++, R, Python, Octave и рендерить изображения с помощью Blender, а также промо-код для получения бесплатных дополнительных часов работы ваших задач.


 Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.
Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.








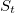 . Рассчитаем логарифмические отношения:
. Рассчитаем логарифмические отношения: 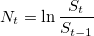
 на
на 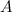 смежных периодов длиной
смежных периодов длиной 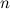 . Отметим каждый период как
. Отметим каждый период как 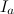 , где
, где 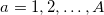 . Определим для каждого
. Определим для каждого