В этой статье я постарался систематизировать всю имеющуюся на текущий момент информацию о том, как можно переместить капитал в том или ином виде через российскую границу.

Артур @select_artur
Пользователь
Postgresso 28
8 мин

Привет всем уже в 21-м году. Надеемся, он будет добрей к нам, чем прошлый. Жизнь продолжается. И мы продолжаем знакомить вас с самыми интересными новостями PostgreSQL. Для разнообразия начну с конференций: этот жанр больше всего пострадал.
Конференции
Организаторы конференций выбирают разные стратегии в условиях карантина. Самый простой — отменить, но лучше чем-то компенсировать.
Nordic PGDay 2021
Отменена. Рассчитывают на Хельсинки в марте 2022. Виртуального варианта не будет, но собираются сфокусироваться на PostgreSQL-треке FOSDEM 2021 в феврале. На сайте написано 2022, но имеется в виду, судя по всему FOSDEM 2021, о котором ниже.
А вот подход Highload++. Бескомпромиссный — никакого онлайна:
Highload++ 2020 (2021)
Конференцию HighLoad++ не стали переносить в онлайн — решили, что она для этого слишком масштабная. Но даты передвинули с 9-10 ноября 2020 г. на 20-21 мая 2021 года. Должна пройти в Москве в «Крокус Экспо 3».
А вот полная противоположность:
FOSDEM 2021
Никакого Брюсселя, в 2021 только онлайн. Не только бесплатно, но и регистрации даже не требуется. Среди участников этой огромной конференции немало докладчиков, известных среди российских постгресистов: Олег Бартунов, Павел Борисов, Алексей Кондратов, Анастасия Лубенникова, Никита Глухов (Postgres Professional), Николай Самохвалов (Postgres.ai), Пётр Зайцев (Percona), Андрей Бородин (Yandex), Олег Иванов (Samsung AI Center, он автор плагина AQO в Postgres Pro Enterprise).
Расписание можно попробовать изучить здесь. Поток PostgreSQL здесь.
PGConf.Online 2021
eBPF: современные возможности интроспекции в Linux, или Ядро больше не черный ящик
18 мин
У всех есть любимые книжки про магию. У кого-то это Толкин, у кого-то — Пратчетт, у кого-то, как у меня, Макс Фрай. Сегодня я расскажу вам о моей любимой IT-магии — о BPF и современной инфраструктуре вокруг него.
BPF сейчас на пике популярности. Технология развивается семимильными шагами, проникает в самые неожиданные места и становится всё доступнее и доступнее для обычного пользователя. Почти на каждой популярной конференции сегодня можно услышать доклад на эту тему, и GopherCon Russia не исключение: я представляю вам текстовую версию моего доклада.
В этой статье не будет уникальных открытий. Я просто постараюсь показать, что такое BPF, на что он способен и как может помочь лично вам. Также мы рассмотрим особенности, связанные с Go.
Я бы очень хотел, чтобы после прочтения моей статьи у вас зажглись глаза так, как зажигаются глаза у ребёнка, впервые прочитавшего книгу о Гарри Поттере, чтобы вы пришли домой или на работу и попробовали новую «игрушку» в деле.
Книга «BPF для мониторинга Linux»
15 мин
 Привет, Хаброжители! Виртуальная машина BPF — один из важнейших компонентов ядра Linux. Её грамотное применение позволит системным инженерам находить сбои и решать даже самые сложные проблемы. Вы научитесь создавать программы, отслеживающие и модифицирующие поведение ядра, сможете безопасно внедрять код для наблюдения событий в ядре и многое другое. Дэвид Калавера и Лоренцо Фонтана помогут вам раскрыть возможности BPF. Расширьте свои знания об оптимизации производительности, сетях, безопасности. — Используйте BPF для отслеживания и модификации поведения ядра Linux. — Внедряйте код для безопасного мониторинга событий в ядре — без необходимости перекомпилировать ядро или перезагружать систему. — Пользуйтесь удобными примерами кода на C, Go или Python. — Управляйте ситуацией, владея жизненным циклом программы BPF.
Привет, Хаброжители! Виртуальная машина BPF — один из важнейших компонентов ядра Linux. Её грамотное применение позволит системным инженерам находить сбои и решать даже самые сложные проблемы. Вы научитесь создавать программы, отслеживающие и модифицирующие поведение ядра, сможете безопасно внедрять код для наблюдения событий в ядре и многое другое. Дэвид Калавера и Лоренцо Фонтана помогут вам раскрыть возможности BPF. Расширьте свои знания об оптимизации производительности, сетях, безопасности. — Используйте BPF для отслеживания и модификации поведения ядра Linux. — Внедряйте код для безопасного мониторинга событий в ядре — без необходимости перекомпилировать ядро или перезагружать систему. — Пользуйтесь удобными примерами кода на C, Go или Python. — Управляйте ситуацией, владея жизненным циклом программы BPF. Serverless и полтора программиста
4 мин

В повседневной продуктовой разработке, запертой в корпоративных технологических ограничениях, редко выпадает случай шагнуть за грань добра и зла в самое пекло хипстерских технологий. Но, когда ты сам несешь все риски и каждый день разработки вынимает деньги из твоего собственного кармана очень хочется срезать путь. В один из таких моментов я решил шагнуть в такой темный серверлес, о котором раньше думать было как-то стыдно. Под впечатлением от того, что получилось, я даже хотел написать статью «Конец гегемонии программистов», но спустя полгода эксплуатации и развития проекта понял, что ну не совсем еще конец и остались еще места в этом самом serverless-бэкенде, где надо использовать знания и опыт.
Подборка статей о машинном обучении: кейсы, гайды и исследования за январь 2020
5 мин
Исследовательская работа в области машинного обучения постепенно покидает пределы университетских лабораторий и из научной дисциплины становится прикладной. Тем не менее, все еще сложно находить актуальные статьи, которые написаны на понятном языке и без миллиарда сносок.
Этот пост содержит список англоязычных материалов за январь, которые написаны без лишнего академизма. В них вы найдете примеры кода и ссылки на непустые репозитории. Упомянутые технологии лежат в открытом доступе и не требуют сверхмощного железа для тестирования.
Этот пост содержит список англоязычных материалов за январь, которые написаны без лишнего академизма. В них вы найдете примеры кода и ссылки на непустые репозитории. Упомянутые технологии лежат в открытом доступе и не требуют сверхмощного железа для тестирования.
Книга «C++. Практика многопоточного программирования»
17 мин
 Привет, Хаброжители! Язык С++ выбирают, когда надо создать по-настоящему молниеносные приложения. А качественная конкурентная обработка сделает их еще быстрее. Новые возможности С++17 позволяют использовать всю мощь многопоточного программирования, чтобы с легкостью решать задачи графической обработки, машинного обучения и др. Энтони Уильямс, эксперт конкурентной обработки, рассматривает примеры и описывает практические задачи, а также делится секретами, которые пригодятся всем, в том числе и самым опытным разработчикам.
Привет, Хаброжители! Язык С++ выбирают, когда надо создать по-настоящему молниеносные приложения. А качественная конкурентная обработка сделает их еще быстрее. Новые возможности С++17 позволяют использовать всю мощь многопоточного программирования, чтобы с легкостью решать задачи графической обработки, машинного обучения и др. Энтони Уильямс, эксперт конкурентной обработки, рассматривает примеры и описывает практические задачи, а также делится секретами, которые пригодятся всем, в том числе и самым опытным разработчикам. В книге • Полный обзор возможностей С++17. • Запуск и управление потоками. • Синхронизация конкурентных операций. • Разработка конкурентного кода. • Отладка многопоточных приложений. Книга подойдет для разработчиков среднего уровня, пользующихся C и C++. Опыт конкурентного программирования не требуется.
Continuous integration в Яндексе. Часть 2
11 мин
В предыдущей статье мы рассказали про перенос разработки в единый репозиторий с trunk-based подходом к разработке, с едиными системами сборки, тестирования, деплоя и мониторинга, про то, какие задачи должна решать система непрерывной интеграции для эффективной работы в таких условиях.
Сегодня мы расскажем читателям Хабра про устройство системы непрерывной интеграции.

Система непрерывной интеграции должна работать надежно и быстро. Система должна быстро реагировать на поступающие события и не должна вносить дополнительных задержек в процесс доставки результатов запуска тестов до пользователя. Результаты сборки и тестирования нужно доставлять до пользователя в режиме реального времени.
DDIA book (книга с кабанчиком) — сделай level up в понимании баз данных
4 мин
Несколько месяцев назад на одной из ретроспектив мы решили попробовать совместное чтение.
Наш формат:
Что дает:
Одна из недавних книг, которую мы читали — Designing Data-Intensive Applications. Да-да, та самая книга с кабанчиком. И эта книга настолько всем понравилась, что я решил сделать здесь обзор, чтобы большее количество людей ее прочитали.
Карта в исходном качестве
Наш формат:
- Выбираем книгу.
- Определяем часть, которую необходимо прочитать за неделю. Выбираем небольшой объем.
- В пятницу обсуждаем прочитанное.
- Читаем в нерабочее время, обсуждаем в рабочее.
- После окончания книги совместно выбираем следующую.
Что дает:
- Мотивация на чтение и дочитывание.
- Развитие скиллов (в том числе на будущее).
- Выравнивание майндсета и терминологии в команде.
- Рост доверия.
- Лишний повод пообщаться.
Одна из недавних книг, которую мы читали — Designing Data-Intensive Applications. Да-да, та самая книга с кабанчиком. И эта книга настолько всем понравилась, что я решил сделать здесь обзор, чтобы большее количество людей ее прочитали.
Карта в исходном качестве
{kind=link}
Что читают инженеры GridGain. Книги для тех, кто интересуется In-Memory Computing
3 мин
Не так давно у нас в корпоративном чате развернулась баталия по поводу бумажных книг и книг вообще. Оказалось, что, несмотря на популярность блогов и обучающих видео, любителей полистать хорошую книгу на читалке, или даже в бумаге, у нас достаточно много. Тем более, к некоторым книгам хочется иногда возвращаться, чтобы уложить всё в голове или поискать решение конкретной задачи.

Мы даже составили небольшой список книг, которые нам очень нравятся. Ну и еще это подсказка для собеседований по нашим свеженьким вакансиям, конечно. Не в смысле запомнить пару названий, а в смысле прочитать, разумеется.
Мы даже составили небольшой список книг, которые нам очень нравятся. Ну и еще это подсказка для собеседований по нашим свеженьким вакансиям, конечно. Не в смысле запомнить пару названий, а в смысле прочитать, разумеется.
350+ полезных ресурсов, книг и инструментов для работы с Docker
14 мин
Перевод
Мы уже ни раз приводили полезные руководства и подборки источников для разработчиков. На этот раз мы решили продолжить тему контейнеров, которую мы затрагивали ранее, и рассказать о подборке тематических ресурсов на GitHub.

Бесплатные книги
3 мин
Несколько книг по разным темам, которые находятся в открытом доступе.
Основы программирования
Основы программирования
Индексы в PostgreSQL — 9
18 мин
В прошлых статьях мы рассмотрели механизм индексирования PostgreSQL, интерфейс методов доступа и следующие методы: хеш-индексы, B-деревья, GiST, SP-GiST, GIN и RUM. Тема этой статьи — BRIN-индексы.
BRIN
Общая идея
В отличие от индексов, с которыми мы уже познакомились, идея BRIN не в том, чтобы быстро найти нужные строки, а в том, чтобы избежать просмотра заведомо ненужных. Это всегда неточный индекс: он вообще не содержит TID-ов табличных строк.
Упрощенно говоря, BRIN хорошо работает для тех столбцов, значения в которых коррелируют с их физическим расположением в таблице. Иными словами, если запрос без предложения ORDER BY выдает значения столбца практически в порядке возрастания или убывания (и при этом по столбцу нет индексов).
Метод доступа создавался в рамках европейского проекта по сверхбольшим аналитическим базам данных Axle с прицелом на таблицы размером в единицы и десятки терабайт. Важное свойство BRIN, позволяющее создавать индексы на таких таблицах — небольшой размер и минимальные накладные расходы на поддержание.
Работает это следующим образом. Таблица разбивается на зоны (range) размером в несколько страниц (или блоков, что то же самое) — отсюда и название: Block Range Index, BRIN. Для каждой зоны в индексе сохраняется сводная информация о данных в этой зоне. Как правило, это минимальное и максимальное значения, но бывает и иначе, как мы увидим дальше. Если при выполнении запроса, содержащего условие на столбец, искомые значения не попадают в диапазон, то всю зону можно смело пропускать; если же попадают — все строки во всех блоках зоны придется просмотреть и выбрать среди них подходящие.
Не будет ошибкой рассматривать BRIN не как индекс в обычном понимании, а как ускоритель последовательного сканирования таблицы. Можно посмотреть на него и как на альтернативу секционированию, если каждую зону считать отдельной «виртуальной» секцией.
Теперь рассмотрим устройство индекса более подробно.
Индексы в PostgreSQL — 8
11 мин
Мы уже рассмотрели механизм индексирования PostgreSQL, интерфейс методов доступа и все основные методы доступа, как то: хеш-индексы, B-деревья, GiST, SP-GiST и GIN. А в этой части посмотрим на превращение джина в ром.
RUM
Хоть авторы и утверждают, что джин — могущественный дух, но тема напитков все-таки победила: GIN следующего поколения назвали RUM.
Этот метод доступа развивает идею, заложенную в GIN, и позволяет выполнять полнотекстовый поиск еще быстрее. Это единственный метод в этой серии статей, который не входит в стандартную поставку PostgreSQL и является сторонним расширением. Есть несколько вариантов его установки:
- Взять пакет yum или apt из репозитория PGDG. Например, если вы ставили PostgreSQL из пакета postgresql-10, то поставьте еще postgresql-10-rum.
- Самостоятельно собрать и установить из исходных кодов на github (инструкция там же).
- Пользоваться в составе Postgres Pro Enterprise (или хотя бы читать оттуда документацию).
Ограничения GIN
Какие ограничения индекса GIN позволяет преодолеть RUM?
Во-первых, тип данных tsvector, помимо самих лексем, содержит информацию об их позициях внутри документа. В GIN-индексе, как мы видели в прошлый раз, эта информация не сохраняются. Из-за этого операции фразового поиска, появившиеся в версии 9.6, обслуживается GIN-индексом неэффективно и вынуждены обращаться к исходным данным для перепроверки.
Во-вторых, поисковые системы обычно возвращают результаты в порядке релевантности (что бы это ни означало). Для этого можно пользоваться функциями ранжирования ts_rank и ts_rank_cd, но их приходится вычислять для каждой строки результата, что, конечно, медленно.
Метод доступа RUM в первом приближении можно рассматривать как GIN, в который добавлена позиционная информация, и который поддерживает выдачу результата в нужном порядке (аналогично тому, как GiST умеет выдавать ближайших соседей). Пойдем по порядку.
Как это сделано: префиксный поиск
5 мин
Мы живем во времена, когда кажется, что все просто и все есть. Нужно сделать масштабируемый проект — используем MongoDB, нужна очередь — вот RabbitMQ, нужно поднять функционал поиска — раз плюнуть: ставим Sphinx, Solr, ElasticSearch (нужное подчеркнуть).
Но здесь лишь доля правды: — при определенном везении можно поставить нужный сервер и все зашевелится. Загвоздка с поиском состоит в том, что пользователи уже порядком привыкли к высокой планке, которую задают «большие ребята», а тот поиск, что поднимется у вас «из коробки», будет явно недотягивать. И если очередь или базу данных вы можете добить железом прежде, чем будете оптимизировать, то поиск железом не добьешь.
Существую толстые книжки про настройки полнотекстового поиска, однако их мало кто читает. Сегодня я хотел бы на пальцах поговорить о том, что нужно учесть, когда вы делаете префиксный поиск с выводом результатов по мере набора слова или фразы.
Мы посмотрим, как с помощью нашего проекта http://indexisto.com сделан поиск на сайте http://maximonline.ru и сравним его с тем, что есть на других сайтах.
Для начала несколько примеров. Возьмем запрос «Битва за Лос Анджелес» и представим, что его напишут неправильно «Лос Анжелес биттва». Как видно, пользователь не знает точно, как пишется имя города, и забыл, как звучит название фильма, а также у него дрогнула рука в конце на слове «битва».
Выберем достойные проекты рунета, в которых есть префиксный поиск, и попробуем поискать там наш запрос:
Но здесь лишь доля правды: — при определенном везении можно поставить нужный сервер и все зашевелится. Загвоздка с поиском состоит в том, что пользователи уже порядком привыкли к высокой планке, которую задают «большие ребята», а тот поиск, что поднимется у вас «из коробки», будет явно недотягивать. И если очередь или базу данных вы можете добить железом прежде, чем будете оптимизировать, то поиск железом не добьешь.
Существую толстые книжки про настройки полнотекстового поиска, однако их мало кто читает. Сегодня я хотел бы на пальцах поговорить о том, что нужно учесть, когда вы делаете префиксный поиск с выводом результатов по мере набора слова или фразы.
Мы посмотрим, как с помощью нашего проекта http://indexisto.com сделан поиск на сайте http://maximonline.ru и сравним его с тем, что есть на других сайтах.
Для начала несколько примеров. Возьмем запрос «Битва за Лос Анджелес» и представим, что его напишут неправильно «Лос Анжелес биттва». Как видно, пользователь не знает точно, как пишется имя города, и забыл, как звучит название фильма, а также у него дрогнула рука в конце на слове «битва».
Выберем достойные проекты рунета, в которых есть префиксный поиск, и попробуем поискать там наш запрос:
| Проект | Правильный запрос | Неправильный запрос |
|---|---|---|
| afisha.ru |
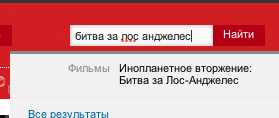 все ОК |
 Не найдено |
| ivi.ru |
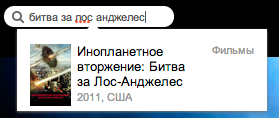 все ОК |
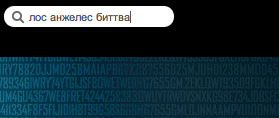 Не найдено |
| vk.com |
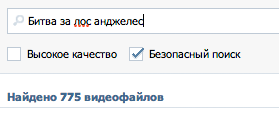 все ОК |
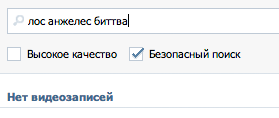 Не найдено |
| maximonline.ru |
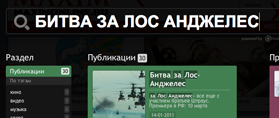 все ОК |
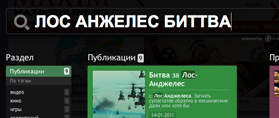 все ОК |
Smart плинтус 1.0
3 мин

Озаботила меня одна проблема – темный коридор по пути из спальни на кухню. Ну, знаете, люблю ночью на кухню ходить, но в потемках некомфортно, а т.к. коридор относительно ширины достаточно длинный, то велика вероятность отклонения от маршрута при ориентировании по встроенным в голову гироскопам. Ошибка накапливается, да еще ноги разной длины, ходил с вытянутыми руками и попадал в дверной проем не с первого раза.
Да, конечно есть всякие ночники, датчики движения, умные дома, но у меня есть лучше, у меня есть пластиковый плинтус с кабельным каналом.
Поэтому возникла идея запихать туда светодиодную ленту и посмотреть, как она там себя будет чувствовать и получилось, знаете ли, довольно круто, такая подсветочка, как в космических кораблях.
Хочется взять и расстрелять, или ликбез о том, почему не стоит использовать make install
5 мин
| К написанию сей заметки меня сподвигло то, что я устал делать развёрнутые замечания на эту тему в комментариях к статьям, где в качестве части инструкции по сборке и настройке чего-либо для конкретного дистра предлагают выполнить make install. |
 Суть сводится к тому, что эту команду в виде «make install» или «sudo make install» использовать в современных дистрибутивах нельзя.
Суть сводится к тому, что эту команду в виде «make install» или «sudo make install» использовать в современных дистрибутивах нельзя. Но ведь авторы программ в руководствах по установке пишут, что нужно использовать эту команду, возможно, скажете вы. Да, пишут. Но это лишь означает, что они не знают, какой у вас дистрибутив, и дистрибутив ли это вообще, может, вы вступили в секту и об
Регулярные выражения изнутри
5 мин
Регулярные выражения (РВ) — это очень удобная форма записи так называемых регулярных или автоматных языков. Поэтому РВ используются в качестве входного языка во многих системах, обрабатывающих цепочки. Рассмотрим примеры таких систем:
В данной статье мы сначала ознакомимся с конечными автоматами и их видами (ДКА и НКА), и далее рассмотрим пример построения минимального ДКА по регулярному выражению.
- Команда grep операционной системы Unix или аналогичные команды для поиска цепочек, которые можно встретить в Web-броузерах или системах форматирования текста. В таких системах РВ используются для описания шаблонов, которые пользователь ищет в файле. Различные поисковые системы преобразуют РВ либо в детерминированный конечный автомат (ДКА), либо недетерминированный конечный автомат (НКА) и применяют этот автомат к файлу, в котором производится поиск.
- Генераторы лексических анализаторов. Лексические анализаторы являются компонентом компилятора, они разбивают исходную программу на логические единицы (лексемы), которые могут состоять из одного или нескольких символов и имеют определенный смысл. Генератор лексических анализаторов получает формальные описания лексем, являющиеся по существу РВ, и создает ДКА, который распознает, какая из лексем появляется на его входе.
- РВ в языках программирования.
В данной статье мы сначала ознакомимся с конечными автоматами и их видами (ДКА и НКА), и далее рассмотрим пример построения минимального ДКА по регулярному выражению.
Как работает реляционная БД
51 мин
Туториал
Перевод
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.На самом деле, мало кто действительно понимает, как работают реляционные БД. А многие разработчики очень не любят, когда они чего-то не понимают. Если реляционные БД используют порядка 40 лет, значит тому есть причина. РБД — штука очень интересная, поскольку в ее основе лежат полезные и широко используемые понятия. Если вы хотели бы разобраться в том, как работают РБД, то эта статья для вас.
Первичный ключ – GUID или автоинкремент?
7 мин
Зачастую, когда разработчики сталкиваются с созданием модели данных, тип первичного ключа выбирается «по привычке», и чаще всего это автоинкрементное целочисленное поле. Но в реальности это не всегда является оптимальным решением, так как для некоторых ситуаций более предпочтительным может оказаться GUID. На практике возможны и другие, более редкие, типы ключа, но в данной статье мы их рассматривать не будем.