Наткнулся в сети на хорошую инфографику от Digital Surgeons, включающую в себя разного рода статистику о пользователях Facebook и Twitter (пол, возраст, образование, частоту появления в сети, откуда и т.п.). Картинка большая, поэтому, кому интересно, прошу под кат.

Александр Семёнов @semenoffalex
Пользователь
Поддержка OAuth 2.0 платформой ВКонтакте
2 мин
Вчера во ВКонтакте появилась поддержка открытого стандарта авторизации OAuth 2.0. Теперь интегрировать сайты и клиентские приложения с социальной сетью стало значительно проще.

Алгоритм для выявления сообществ в больших сетях
2 мин
В последнее время предпринимаются многочисленные попытки разработать эффективный алгоритм для выявления сообществ в социальных сетях из миллионов узлов, которые невозможно визуализировать или анализировать на уровне отдельных узлов.
Бельгийские разработчики представили новый алгоритм, который превосходит все существующие аналоги по вычислительной скорости. Вследствие этого его можно применять на базах беспрецедентного размера: анализ типичной сети из 2 млн нодов занимает 2 минуты. Он получил название Лувенский метод (Louvain Method), поскольку создан в то время, когда все разработчики трудились в Лувене (Бельгия).
Бельгийские разработчики представили новый алгоритм, который превосходит все существующие аналоги по вычислительной скорости. Вследствие этого его можно применять на базах беспрецедентного размера: анализ типичной сети из 2 млн нодов занимает 2 минуты. Он получил название Лувенский метод (Louvain Method), поскольку создан в то время, когда все разработчики трудились в Лувене (Бельгия).
Асинхронный web-mining c помощью node.js
6 мин
Хотелось бы поделится опытом решения задачи web-mining'а: сбор некоторой информации с определенного списка ресурсов. Сразу хотелось бы отметить, что это не является попыткой создать свой «поисковик» — для этого используются совершенно другие подходы. Цель web-mining’а – вытащить часть информации. Например, если ресурс поддерживает микроформаты в виде «визиток» и т.п.
Секрет анализа трафика
3 мин
 Логично, что эффективное продвижение включает не только выбор каналов привлечения пользователей, но и анализ трафика с дальнейшей настройкой каждого канала. Цель настройки — повысить отдачу от вложенных ресурсов, повысить конверсию.
Логично, что эффективное продвижение включает не только выбор каналов привлечения пользователей, но и анализ трафика с дальнейшей настройкой каждого канала. Цель настройки — повысить отдачу от вложенных ресурсов, повысить конверсию. Социальные сети. Модели информационного влияния, управления и противоборства
1 мин
Хочу порекомендовать одну интересную книгу про социальные сети. Книга имеет название «Социальные сети. Модели информационного влияния, управления и противоборства». Я не видел на русском языке книгу про социальные сети (не считая «Программируем коллективный разум»), может быть есть и другие. Эта книга затрагивает интересные и скрытые моменты, также в ней упоминается Хабр.

Небольшое введение в содержание:
1. Моделирование социальных сетей
2. Стохастические модели социальных сетей
3. Модели информационного управления и информационного противоборства в социальных сетях
4. Имитационное моделирование информационного влияния и управления в социальных сетях
скачать
купить
Небольшое введение в содержание:
1. Моделирование социальных сетей
2. Стохастические модели социальных сетей
3. Модели информационного управления и информационного противоборства в социальных сетях
4. Имитационное моделирование информационного влияния и управления в социальных сетях
скачать
купить
Используем Adobe Illustrator для создания макета страницы
4 мин
Перевод
Данное руководство создано для тех, кто уже умеет пользоваться Adobe Illustrator, но пока не знает всех тонкостей работы с ним и хочет познакомиться поближе.
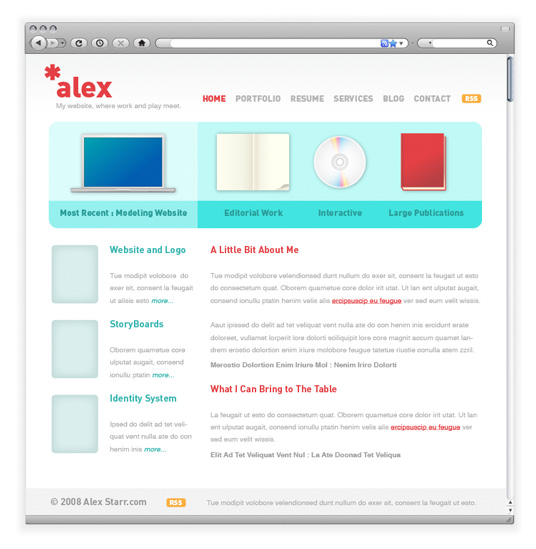
Товарищ CurlyBrace уже сверстал представленный здесь макет, спасибо ему!
Для начала посмотрите на то, что мы будем стараться сделать:
Товарищ CurlyBrace уже сверстал представленный здесь макет, спасибо ему!
Для начала посмотрите на то, что мы будем стараться сделать:

Как правильно оформить статью?
5 мин
Если вы ведете блог, то, возможно, вам знакомо чувство, когда взлелеянную, родившуюся в тяжелом труде статью никто не читает. И вы не можете понять причины. Кажется, и тема выбрана правильно. И стиль подобран адекватно. И слова использованы именно те, которые нужно! Статья написана интересно, и, бесспорно, должна быть полезной значительной части вашей ключевой аудитории…

Вы готовы воспринять это и адекватно отнестись, если сами чувствуете, где совершили ошибку, а где откровенно схалтурили. Знаете, что статья не дотягивает до уровня ваших привычных публикаций. Но если все сделано вроде бы правильно — можно попасть даже в глубокую депрессию из-за непонимания причин такого провала. Я промолчу о том, что мотивация к дальнейшему ведению блога испаряется пропорционально количеству таких «незамеченных» публикаций.
Вы готовы воспринять это и адекватно отнестись, если сами чувствуете, где совершили ошибку, а где откровенно схалтурили. Знаете, что статья не дотягивает до уровня ваших привычных публикаций. Но если все сделано вроде бы правильно — можно попасть даже в глубокую депрессию из-за непонимания причин такого провала. Я промолчу о том, что мотивация к дальнейшему ведению блога испаряется пропорционально количеству таких «незамеченных» публикаций.
Писатели и читатели — анализ структуры комментариев ЖЖ ТОП-500, часть 1
5 мин
Начало
Я продолжаю серию публикаций-исследований на тему структурного анализа русскоязычного сегмента Живого Журнала. Первая публикация была посвящена некоторому анализу аудиторий 10-ти топовых блоггеров. Во время ее подготовки был собран граф связей русского ЖЖ, охватывающий более 2-х млн. блогов и 58 млн. связей между ними. К этому графу я еще вернусь в следующих сериях (пока я еще не осмыслил его), а сегодня о другом. А именно, о том кто, как часто и кого комментирует в самом бурлящем разборками и дискуссиями уголке ЖЖ — в журналах из ТОП-500.
Взяв за основу состояние ЖЖ-рейтинга на начало апреля и отщипнув от него 500 верхних позиций я запустил сбор данных по следующей методике. У каждого блога из списка запрашивались 25 последних публикаций (доступно через штатные средства ЖЖ). Из каждой публикации вытаскивался список комментаторов (имя, id-комментария, место комментария в дереве) если, конечно, комментарии к записи открыты для посторонних.
Штатные средства ЖЖ такого не позволяют, попытки сделать финт ушами и ободрать RSS-выдачу поиска по блогам от Яндекса натыкались на очень странное и несколько нелогичное поведение этой выдачи (это не претензия, это просто факт), поэтому информацию о структуре комментариев пришлось извлекать из страниц журналов. Но это оказалось к лучшему :) Кстати, если что: DDos на ЖЖ — это не я :)
В итоге, после нескольких дней сбора информации (первоначальная версия краулера была не безглючной, ЖЖ притормаживал — в это время на него был очередной ДДоС) получились вот такие исходные данные:
487 журналов, имеющих хотя бы один откомментированный пост;
10546 постов, имеющих хотя бы один комментарий;
809563 комментариев (без учета анонимных), из них 115326 (14,2%) — ответы владельцев журналов;
114412 комментаторов, из них 3884 (3,4%) залогинены с помощью внешних сервисов (twitter, facebook и т.д.)
Далее в программе:
1. Статистика различных характеристик журналов из TOP-500
2. Некоторые неявные, но любопытные рейтинги
3. Поиск ответа «как стать популярным блоггером» с помощью кластерного и корреляционного анализа (это, правда, будет во второй части исследования)
Твить позже, мыль раньше и не забудь про субботу
3 мин
Перевод

Твить больше и обрати внимание на выходные. Такой совет дает Ден Заррелла (Dan Zarrella), исследователь социальных медиа, у которого 33000 собственных фоловеров. Заррелла работает в компании HubSpot, где обрабатывает данные о сотнях миллионов твитов, блог-постов и почтовых рассылок. Эти данные используют маркетологи, стоит обратить на них внимание и новостийщикам.
Кто кого читает в ЖЖ — анализ пересечения аудиторий топовых блоггеров
6 мин
Начало
 Тема исследования связей в социальных сетях становится все более актуальной по разным причинам: попытка ответить на вопрос о степени связности участников сетей; скорости и путях распространения информации; об эффективности целевой рекламы, в конце концов. Да и сам процесс исследования и поиска неявных связей затягивает!
Тема исследования связей в социальных сетях становится все более актуальной по разным причинам: попытка ответить на вопрос о степени связности участников сетей; скорости и путях распространения информации; об эффективности целевой рекламы, в конце концов. Да и сам процесс исследования и поиска неявных связей затягивает!Для своих исследований в этом направлении я выбрал самый «кипящий» кусок рунета, а именно – русский сегмент Живого Журнала. Туманно сформулированный вопрос звучал примерно таким образом: можно ли выделить блоггерские «группировки» исходя из структуры связей между пользователями сервиса ЖЖ, т.е. располагая лишь информацией о «френдах».
Выдвинув в качестве рабочей гипотезы идею о том, что подобную информацию можно извлечь из анализа аудиторий популярных журналов я столкнулся с задачей получения достоверных данных об этих аудиториях. Базовые средства сервиса livejournal не дают возможность получить полный список читателей блога мультитысячника. Поэтому, первым шагом, пришлось собрать структуру связей русского ЖЖ на домашнем компьютере.
Забегая вперед скажу: социальный граф русского ЖЖ в моем исследовании имеет 2,08 млн. вершин и 58,05 млн. дуг. Интересно? Тогда под катом довольно много букв, цифр и картинок.
Дешёвое и сердитое средство для просмотра и анализа логов ISA 2006
3 мин
Доброе время суток, хабралюди.
В этой заметке я опишу один из вариантов просмотра логов ISA 2006. Основное его достоинство в том, что он не требует платного софта.
В этой заметке я опишу один из вариантов просмотра логов ISA 2006. Основное его достоинство в том, что он не требует платного софта.
Два года с кравлерами (web-mining)
4 мин
Disclaimer: этот топик, возможно, отчасти самореклама, «вода» и бред, но, скорее всего, это просто классификация информации и опыта, накопленного за два года работы в области скрейпинга, для себя и тех кому интересно.
За кармой не гонюсь, ее хватает.
Под катом — небольшой пост про современный рынок кравлеров/парсеров, с классификацией и особенностями.
За кармой не гонюсь, ее хватает.
Под катом — небольшой пост про современный рынок кравлеров/парсеров, с классификацией и особенностями.
Анализ социального графа
8 мин

Количество американских патентных заявок связанных с социальными сетями последние 5 лет росло на 250% каждый год (ссылка). Так, например, одна корпорация подала патентную заявку на метод ценообразования который учитывает положение покупателя в социальном графе (обсуждение на Slashdot). Другая корпорация недавно воплотила максимально упрощенный вариант этой схемы, продавая свои новые телефоны влиятельным узлам социального графа за $0, а остальным за $530.
Анализ социальных сетей (Social Network Analysis) существовал задолго до Интернета, но в последнее время набирает обороты.
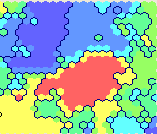
Мне было интересно посмотреть, как эффективно алгоритм, выделяющий кластеры в графах, сработает для некоторых групп в Twitter, которые представляют для меня интерес.
23 января в Запорожье пройдет #UKRTWEET — первый всеукраинский баркэмп посвященный Twitter. Граф выше показывает, кто из его участников, с кем разговаривает и кого упоминает.
Заметка ниже посвящена анализу этого графа. Весь код используемых здесь скриптов лежит на github. Изложение, в какой-то мере, вдохновлено недавно упомянутой на Хабре книгой Тоби Сегаран «Программируем коллективный разум», код примеров которой доступен на сайте автора.
Также о data mining в Twitter я говорил 16 января на первой в этом году донецкой встрече "Кофе и код". Поэтому здесь параллельно проведу анализ группы людей из Донецка, которые пишут в Twitter. Кстати, в этом году донецкие встречи будут регулярными — каждую третью субботу месяца (следующая 20 февраля). Следите за группой.
Теперь ВКонтакте API не только для Flash
1 мин
Сегодня в настройках приложений появился IFrame. Это открывает разработчикам возможность создавать приложения для ВКонтакте без использования Flash.
Как пишет администрация:
Вы можете создать любое интегрированное приложение, загружаемое с Вашего сервера с помощью встроенного на страницу ВКонтакте элемента IFrame. Такие приложения могут отображать информацию с помощью любых технологий, поддерживаемых браузером пользователя: HTML, Javasсript, AJAX, Flash и др.
Подробнее, о том как это работает: vkontakte.ru/pages.php?id=9279356
Как пишет администрация:
Вы можете создать любое интегрированное приложение, загружаемое с Вашего сервера с помощью встроенного на страницу ВКонтакте элемента IFrame. Такие приложения могут отображать информацию с помощью любых технологий, поддерживаемых браузером пользователя: HTML, Javasсript, AJAX, Flash и др.
Подробнее, о том как это работает: vkontakte.ru/pages.php?id=9279356
Тоби Сегаран «Программируем коллективный разум»
3 мин
 Знаете, люблю я книжки про всякие интересные алгоритмы, и вот недавно попалась еще одна такая книжка.
Знаете, люблю я книжки про всякие интересные алгоритмы, и вот недавно попалась еще одна такая книжка. Книга «Программируем коллективный разум» в основном посвящена алгоритмам классификации и кластеризации, хотя есть главы, посвященные другим темам вроде создания собственного поисковика, генетическим алгоритмам и генетическому программированию. Почти все описанные алгоритмы применяются в духе Web 2.0, используя анализ поведения пользователей на разных сайтах, которые предоставляют свой API. Но что особенно приятно удивило, так это то, что все примеры написаны на языке Python.
Вот какие алгоритмы описываются в книге:
- Коллаборативная фильтрация. Или, говоря человечески языком, алгоритмы, которые могут рекомендовать вам какие-то покупки, сайты или музыку в зависимости от оценок, которые вы поставили другим подобным вещам. По таким алгоритмам работает навязывание покупок в интернет-магазинах или подбор музыки на last.fm. В конце главы приводится пример, который будет рекомендовать вам ссылки из сервиса del.icio.us.
- Алгоритмы группировки (кластеризации). Создаваемый пример анализирует RSS-каналы блогов и пытается их автоматически разделить на группы в виде дерева в зависимости от частоты слов, которые попадаются в блоге. Заодно Сегаран рассказывает как можно сделать так, чтобы названия блогов расположились на плоскости кучками в зависимости от их близости в плане рассматриваемых тем.
- Отдельная глава посвящена построению поисковиков – созданию паука и, самое главное, рассматриваются алгоритмы ранжирования ссылок, в том числе и с учетом ссылок страниц друг на друга, создавая, таким образом, аналог Google PageRank. Еще интересно, что в этой же главе есть пример, где для выдачи наиболее релевантных ссылок используется нейронная сеть, которая обучается по мере того как пользователь щелкает на понравившиеся ему ссылки.
Команда MIT за 9 часов выиграла соревнования DARPA
1 мин
Команде «MIT RED BALLOON TEAM» потребовалось меньше 9 часов, чтобы выиграть главный приз в $40000 в соревновании DARPA. Они первые сообщили точные координаты всех 10-ти красных шаров, запущенных по всей территории США, используя вирусную кампанию. Так, всякому сообщившему о местоположении шара полагался приз в $2000. При этом приз поменьше получал человек, который привел друга с правильными данными. Это позволило привлечь к поиску большое количество людей.
Соревнования были организованы DARPA в честь 40-летия ARPANET для изучения
скорости распространения информации в социальных сетях.
Предыдущий пост про это соревнование
Карта с координатами шаров
Соревнования были организованы DARPA в честь 40-летия ARPANET для изучения
скорости распространения информации в социальных сетях.
Предыдущий пост про это соревнование
Карта с координатами шаров
DARPA запускает шары для тестирования возможностей социальных сетей
1 мин
DARPA Network Challenge объявила конкурс по определению точных координат объектов с помощью социальных сетей с призовым фондом в $40000. Конкурс продлится до 14 декабря, то есть неделю.
В субботу в 19:00 MSK планируется запустить 10 красных шаров-метеозондов (2.5 м в диаметре) по всей территории США и примерно через 12 часов все шары будут спущены обратно.
Поскольку никто не сможет определить координаты всех 10 шаров по всей территории США,
то участникам предлагается воспользоваться возможностями социальных сетей.
Приз в $40000 получит первый, кто определит широту и долготу всех 10-ти шаров, а если
никто не успеет до 14 декабря, то приз вручат тому, кто прислал точные координаты
хотя бы 5 шаров.
Основная цель — понять, как интернет и социальные сети могут помочь людям организовать
сотрудничество друг с другом для решения реальных проблем и задач.

В субботу в 19:00 MSK планируется запустить 10 красных шаров-метеозондов (2.5 м в диаметре) по всей территории США и примерно через 12 часов все шары будут спущены обратно.
Поскольку никто не сможет определить координаты всех 10 шаров по всей территории США,
то участникам предлагается воспользоваться возможностями социальных сетей.
Приз в $40000 получит первый, кто определит широту и долготу всех 10-ти шаров, а если
никто не успеет до 14 декабря, то приз вручат тому, кто прислал точные координаты
хотя бы 5 шаров.
Основная цель — понять, как интернет и социальные сети могут помочь людям организовать
сотрудничество друг с другом для решения реальных проблем и задач.