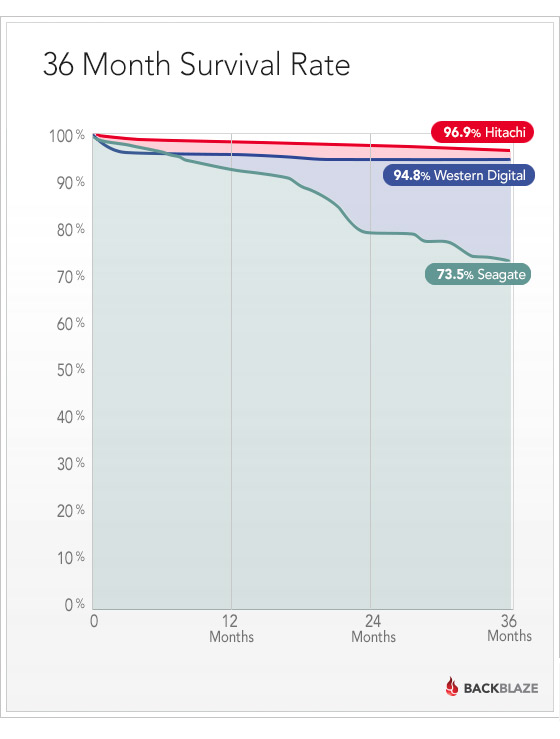
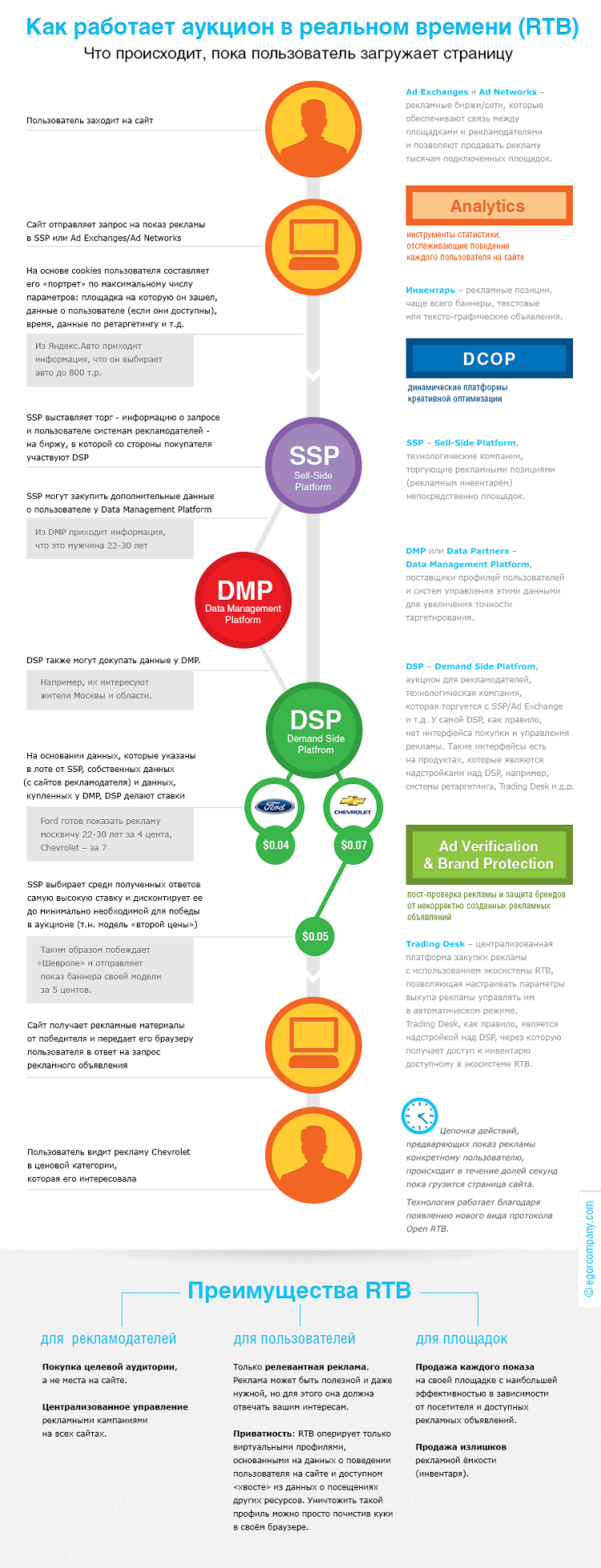
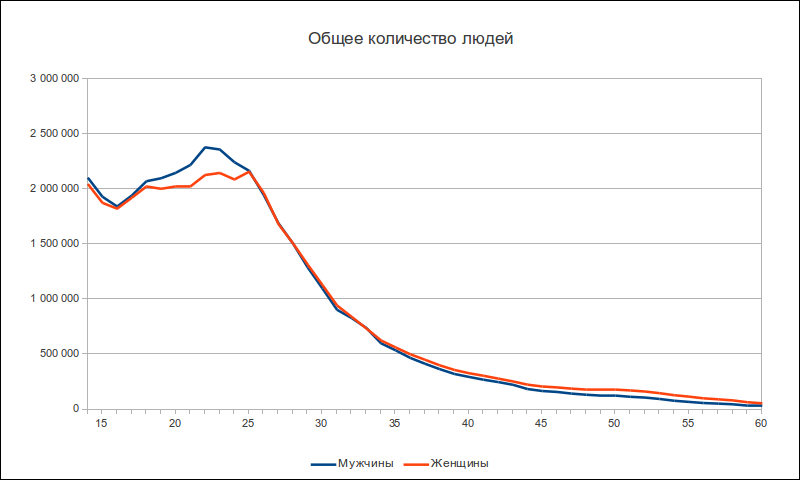
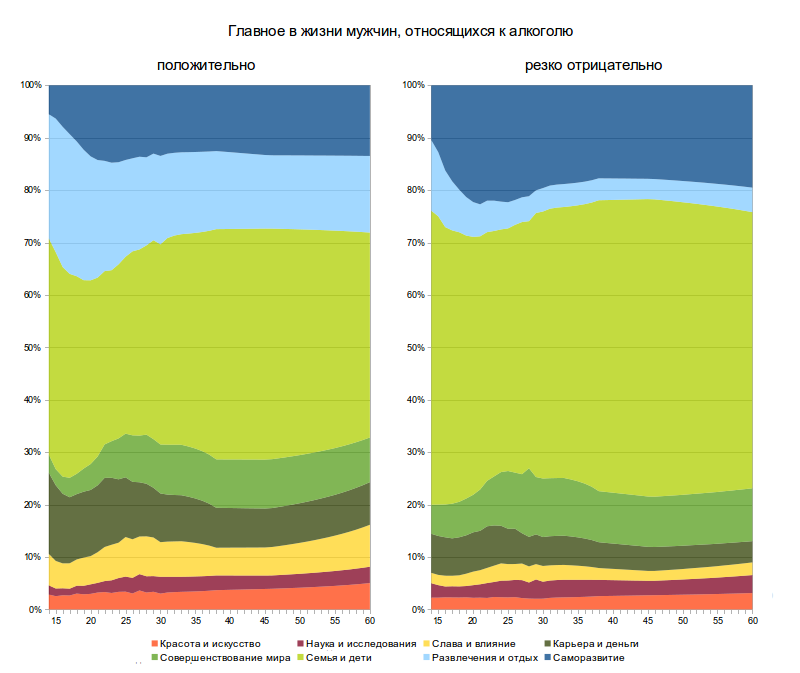
Я работаю в команде семантического веба в Яндексе. Мы занимаемся тем, что создаем продукты на основе семантической разметки, делаем свои расширения и участвуем в развитии стандарта Schema.org.
Мир семантической разметки устроен не вполне просто и на первый взгляд даже не всегда логично. Для того чтобы облегчить жизнь тем, кто хочет в нём разобраться, мы решили написать рассказ о том, какой бывает разметка, что дает и как ее внедрить.
Под микроразметкой (или семантической разметкой) мы подразумеваем разметку страницы с дополнительными тегами и атрибутами в тегах, которые указывают поисковым роботам на то, о чем написано на странице.
Микроразметка состоит из словаря и синтаксиса.
Мир семантической разметки устроен не вполне просто и на первый взгляд даже не всегда логично. Для того чтобы облегчить жизнь тем, кто хочет в нём разобраться, мы решили написать рассказ о том, какой бывает разметка, что дает и как ее внедрить.
Под микроразметкой (или семантической разметкой) мы подразумеваем разметку страницы с дополнительными тегами и атрибутами в тегах, которые указывают поисковым роботам на то, о чем написано на странице.
Микроразметка состоит из словаря и синтаксиса.
")