Начну с того, что я не антипрививочник ни разу, скорее наоборот. Но вакцина вакцине рознь, особенно сейчас и от известного вируса. Итак, что же мы имеем на сегодня?
Гамалеевский Спутник V. Нашумевшая и очень современная вакцина, впереди только генная терапия в чистом виде. Неудивительно, что именно сюда вложили столько сил, времени и средств. Она же пока еще единственно возможная в нашей стране. Ее очевидные плюсы: максимальный иммунный ответ (помимо антител имеем клеточный иммунитет) при минимальных побочных эффектах. Но есть нюанс, про который почему-то если и говорят, то очень-очень мало и конечно же не в СМИ, а в специализированных медицинских пабликах. Сейчас объясню, о чем речь.
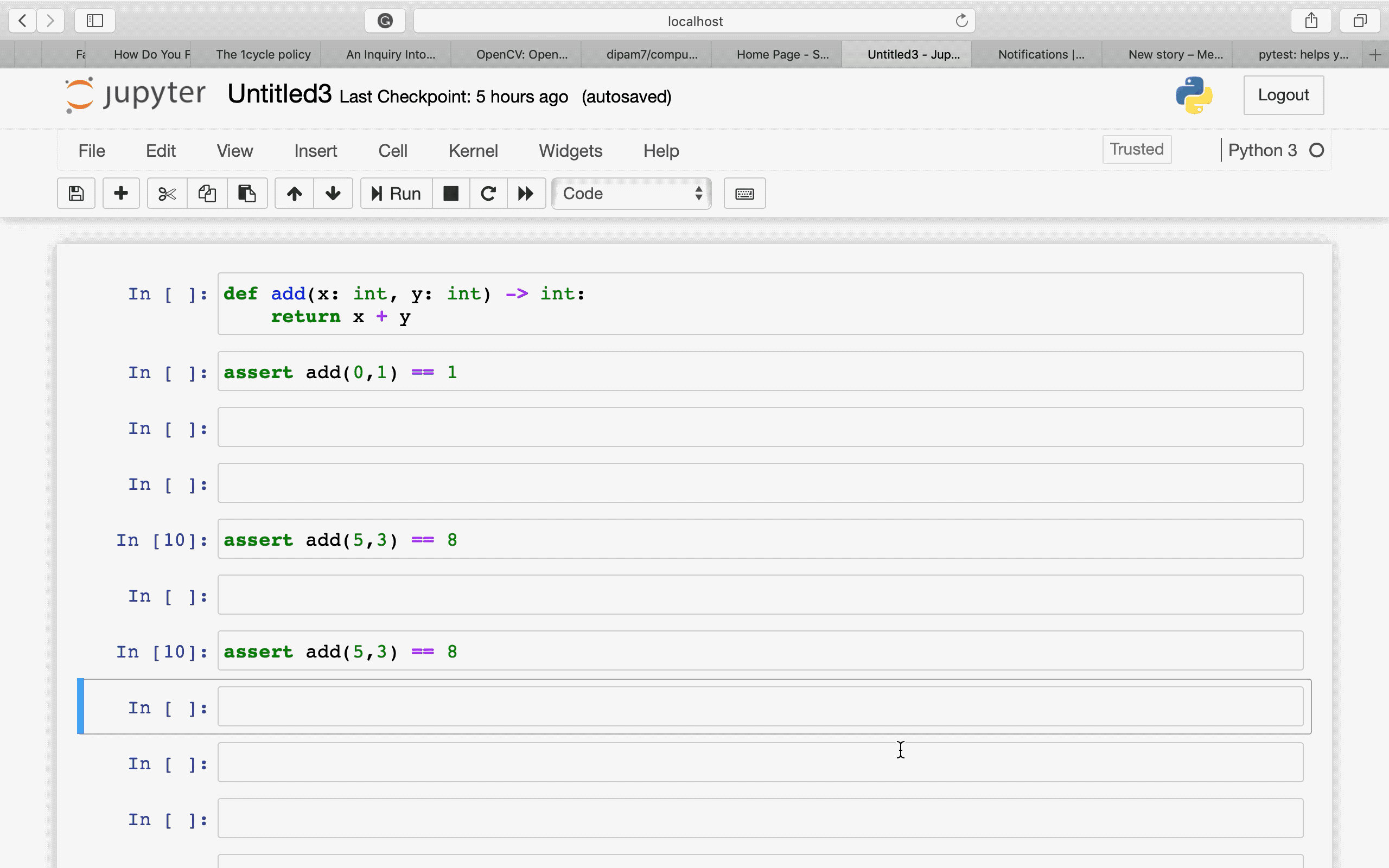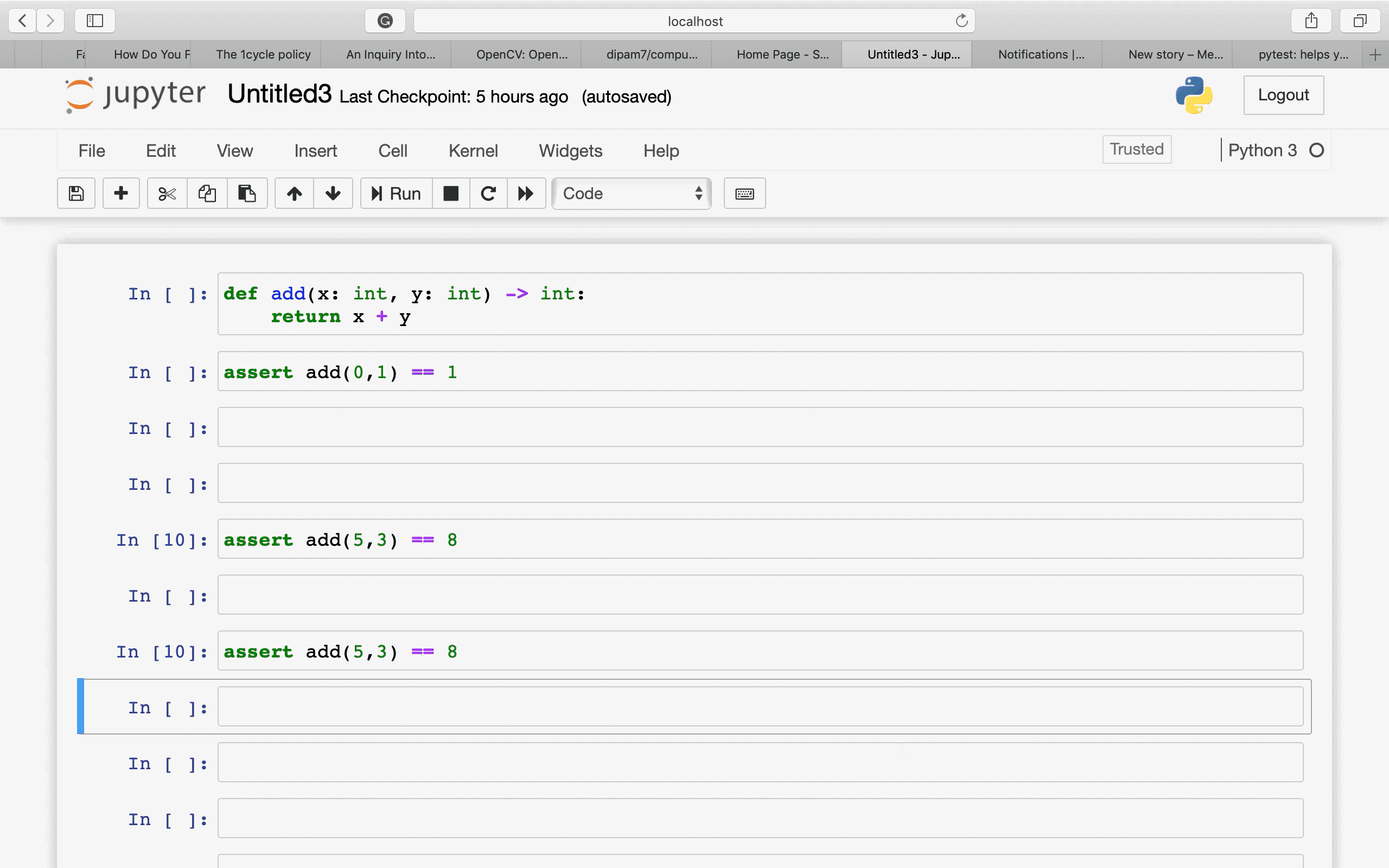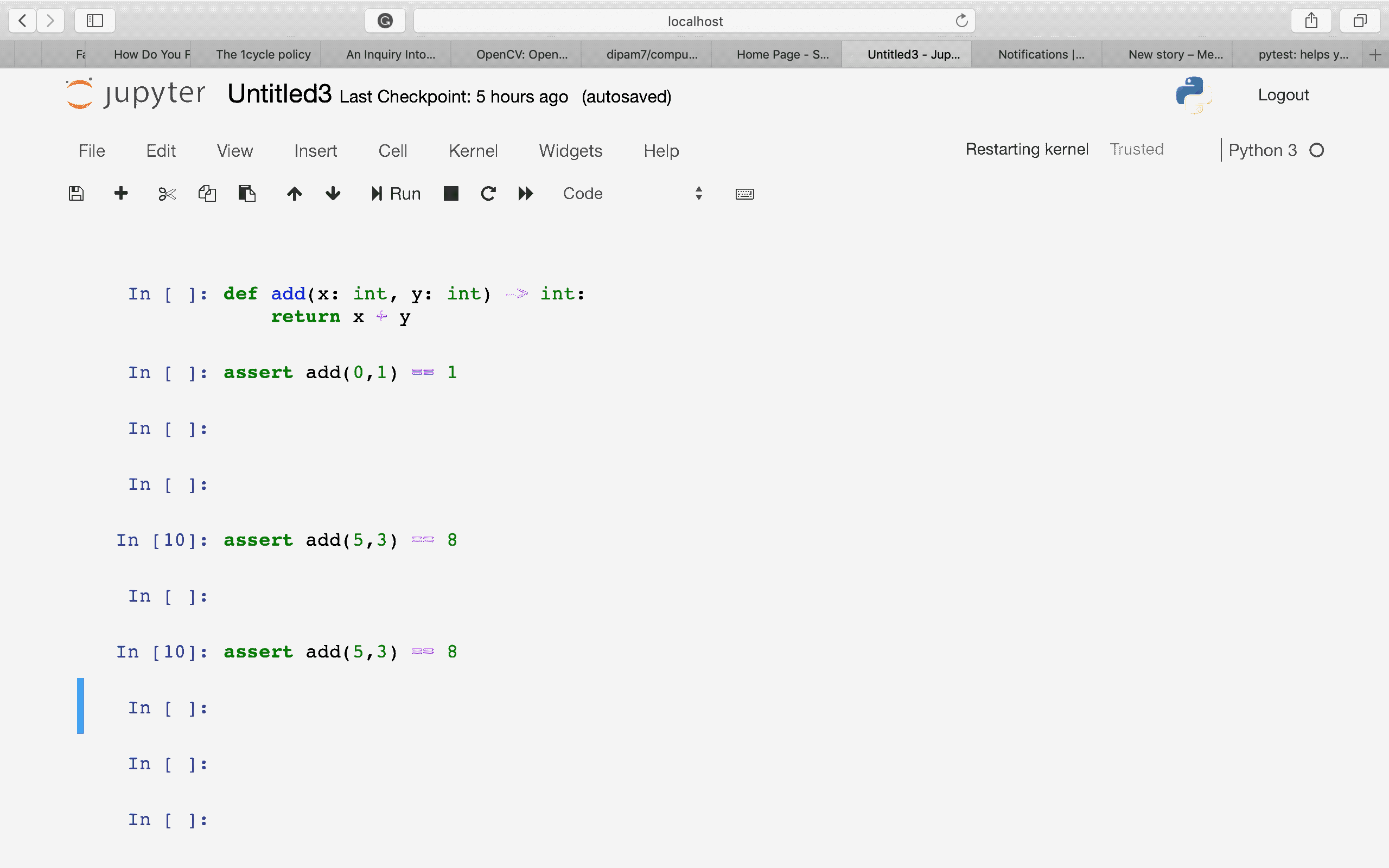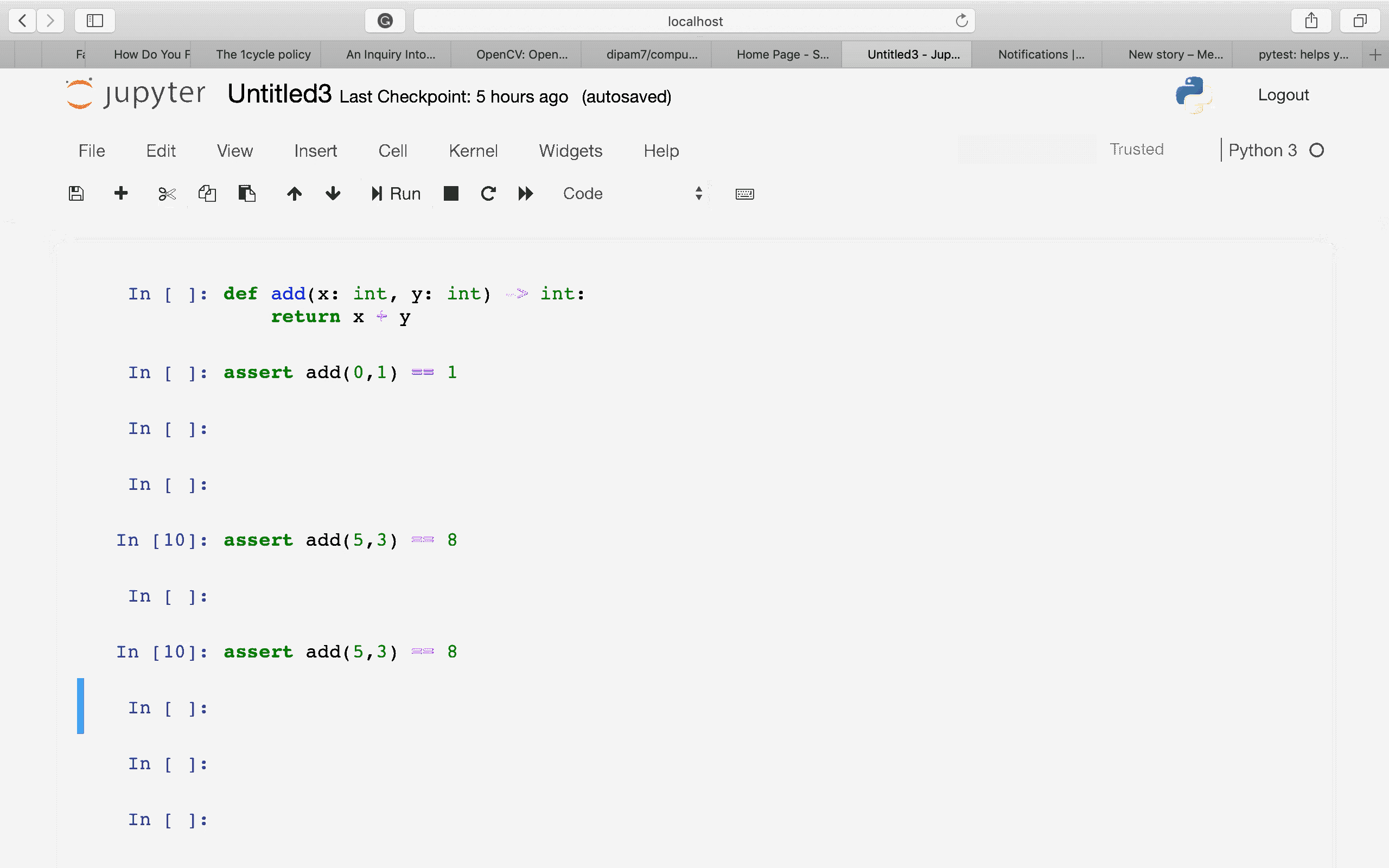
Данная вакцина представляет собой генетически модифицированный аденовирус, вернее два обезвреженных аденовируса (5-го и 26-го серотипов), которые вводятся в организм с промежутком в 3 недели. В геном каждого встроен ген спайк-белка ("шипа") коронавируса. По сути, это «машины», задачами которых является доставка важного «пассажира» по назначению. А дальше все идёт так, как заложено природой: аденовирус доставляет ген коронавируса в клетки, распаковывается там и начинает производить белки как «пассажира», так и свои. Кусочки этих белков выставляет заражённая клетка, обучая тем самым т-лимфоциты. После разрушения «клетки-фабрики», вирусные белки (именно белки, а не готовые заражать новые клетки вирионы, как при болезни) попадают в кровь, тем самым стимулируя производство антител. Заболеть невозможно, иммунитет формируется, и вроде бы все здорово. Но побочным эффектом этой вакцины является развитие иммунного ответа на сами аденовирусные компоненты вектора. В результате повторного введения, «машина с пассажиром» просто не успеет доехать до клетки, а будет сразу уничтожена антителами, которые образуются в результате предыдущего «знакомства». Получается, что Спутник V можно использовать только один раз. И это чревато даже не столько тем, что вакциной больше нельзя будет воспользоваться по назначению - напряженность иммунитета к коронавирусу все равно никому не известна, а случаи повторных заражений вроде бы есть, но мало. Пугает пожизненное ограничение на любую потенциально возможную аденовекторную генную терапию, в том числе и на лечение онкологии, которая может понадобиться в будущем. Все это сейчас активно развивается, а после такого «масштабного тестирования», дело пойдёт ещё быстрее. Но опять же, терапия эта может пригодиться, а может быть и нет, а иммунитет к вирусу нужен уже сегодня. Поэтому, здесь каждый выбирает для себя, что ему важнее. Вакцина получилась вполне нормальная, для пожилых - самое то. А вот на месте молодых (у них ведь есть все шансы в будущем воспользоваться генной терапией), я бы призадумалась.
Слышала про разработку версии «Спутник-Лайт», для тех, кто бережёт (фигуру) иммунитет. Это будет однокомпонентная вакцина, сделаная на основании только одного серотипа. Этот вариант приятнее, но его выпуск планируется не раньше декабря 2021 года.