
Как сейчас проходят собеседования на golang разработчика? Что спрашивают?

Пользователь
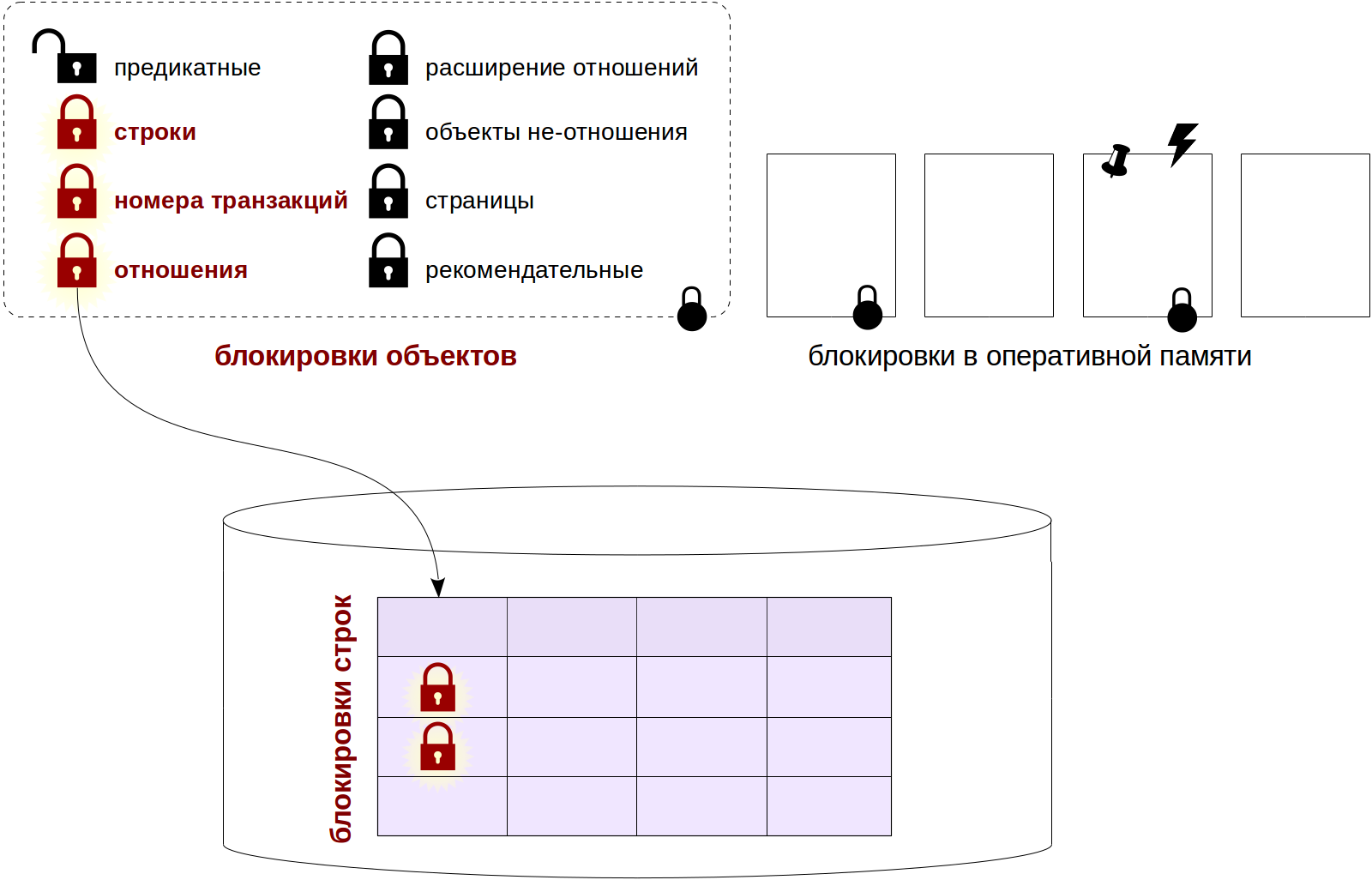
Расшифровка доклада/tutorial "Управление высокодоступными PostgreSQL кластерами с помощью Patroni". А.Клюкин, А.Кукушкин
Patroni — это Python-приложение для создания высокодоступных PostgreSQL кластеров на основе потоковой репликации. Оно используется такими компаниями как Red Hat, IBM Compose, Zalando и многими другими. С его помощью можно преобразовать систему из ведущего и ведомых узлов (primary — replica) в высокодоступный кластер с поддержкой автоматического контролируемого (switchover) и аварийного (failover) переключения. Patroni позволяет легко добавлять новые реплики в существующий кластер, поддерживает динамическое изменение конфигурации PostgreSQL одновременно на всех узлах кластера и множество других возможностей, таких как синхронная репликация, настраиваемые действия при переключении узлов, REST API, возможность запуска пользовательских команд для создания реплики вместо pg_basebackup, взаимодействие с Kubernetes и т.д.
Слушатели мастер-класса подробно узнают, как работает Patroni, получат практические навыки настройки высокодоступных кластеров на его основе, познакомятся с различными дополнительными возможностями и поучаствуют в диагностике проблем. Будут рассмотрены следующие темы:


Мой уход из Яндекса, как не потерять мотивацию за полгода подготовки в FAANG и реджект в Google.

Всем привет. Меня зовут Нещадин Иван, и я расскажу про оптимизацию одного из микросервисов Авито на Go. История построена вокруг различных инструментов, которые доступны в языке, и пойдёт от простых примеров к более сложным.



EXPLAIN [ANALYZE].Предлагаю ознакомиться с расшифровкой доклада начала 2016 года Андрея Сальникова "Типовые ошибки в приложениях, которые ведут к bloat в postgresql"
В данном докладе я разберу основные ошибки в приложениях, которые возникают на этапе проектирования и написания кода приложения. И возьму только те ошибки, которые ведут к bloat в Postgresql. Как правило, это начало конца производительности вашей системы в целом, хотя изначально никаких предпосылок к этому не было видно.

Привет всем! Меня зовут Сергей Камардин, я программист команды Почты Mail.Ru.
Это статья о том, как мы разработали высоконагруженный WebSocket-сервер на Go.
Если тема WebSocket вам близка, но Go — не совсем, надеюсь, статья все равно покажется вам интересной с точки зрения идей и приемов оптимизации.
postgres=# select amname from pg_am;
amname
--------
btree
hash
gist
gin
spgist
brin
(6 rows)


Вы уже используете прогрессивную загрузку? А как насчёт технологий Tree Shaking и разбиения кода в React и Angular? Вы настроили сжатие Brotli или Zopfli, OCSP stapling и HPACK-сжатие? А как у вас обстоят дела с оптимизацией ресурсов и клиентской части, со вложенностью CSS? Не говоря уже о IPv6, HTTP/2 и сервис-воркерах.

Мы решили описать простой и проверенный путь для тех, кто хочет внедрить аналитическую СУБД ClickHouse своими силами или просто испробовать ClickHouse на собственных данных. Именно этот путь прошли мы сами в новостном агрегаторе СМИ2 и добились впечатляющих результатов.
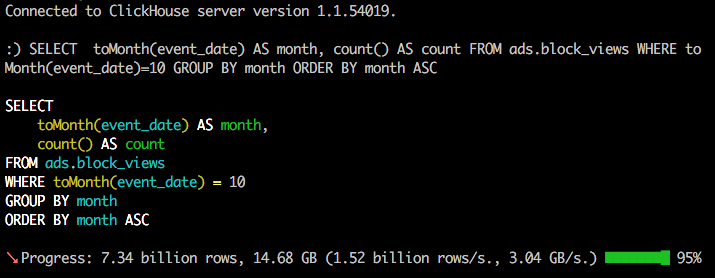
В предисловии статьи — небольшой рассказ о наших попытках внедрить Druid и InfluxDB. Почему после успешного запуска ClickHouse мы смогли отказаться от использования InfiniDB и Cassandra.



 В 2008 году в списке рассылки pgsql-hackers началось обсуждение расширения по сбору статистики по запросам. Начиная с версии 8.4 расширение pg_stat_statements входит в состав постгреса и позволяет получать различную статистику о запросах, которые обрабатывает сервер.
В 2008 году в списке рассылки pgsql-hackers началось обсуждение расширения по сбору статистики по запросам. Начиная с версии 8.4 расширение pg_stat_statements входит в состав постгреса и позволяет получать различную статистику о запросах, которые обрабатывает сервер.
Обычно это расширение используется администраторами баз данных в качестве источника данных для отчетов (эти данные на самом деле являются суммой показателей с момента сброса счетчиков). Но на основе этой статистики можно сделать мониторинг запросов — посмотреть на статистику во времени. Это оказывается крайне полезно для поиска причин различных проблем и в целом для понимания, что происходит на сервере БД.
Я расскажу, какие метрики по запросам собирает наш агент, как мы их группируем, визуализируем, так же расскажу о некоторых граблях, по которым мы прошли.