
Здравствуйте, уважаемое сообщество! Думаю, многим знакома такая структура данных как суффиксное дерево. На Хабре уже было описание как его построить и зачем. Если вкратце, то оно нужно тогда, когда надо много раз искать какие-то произвольные образцы Xi в заранее заданном тексте A, а строится такое дерево мучительно с помощью алгоритма Укконена (есть и другие варианты, но они предполагают еще большее количество страданий). Общее наблюдение при работе с алгоритмами таково, что деревья — это, конечно, хорошо, но на практике их лучше избегать из за серьезных оверхэдов по памяти и не очень оптимального (с точки зрения эффективности оперирования данными компьютером) расположения. Кроме того, именно в таком дереве есть еще более существенная неприятность, а именно алфавитнозависимость структуры. Для решения этих проблем был придуман суффиксный массив. О том как его строить и как использовать и пойдет в этой статье.
Материал статьи предполагает знание понятий суффикса и префикса строки, а также знание того, как работает бинарный поиск. Надо также представлять, что такое стабильная сортировка и поразрядная сортировка, а также понимание, что имеется ввиду под стабильной сортировкой подсчетом. Для некоторых частей нам понадобится знание задачи о минимуме на отрезке — Range Minimum Query (RMQ). Ну, в общем, вас предупредили: никто не говорил, что будет просто.
Материал статьи предполагает знание понятий суффикса и префикса строки, а также знание того, как работает бинарный поиск. Надо также представлять, что такое стабильная сортировка и поразрядная сортировка, а также понимание, что имеется ввиду под стабильной сортировкой подсчетом. Для некоторых частей нам понадобится знание задачи о минимуме на отрезке — Range Minimum Query (RMQ). Ну, в общем, вас предупредили: никто не говорил, что будет просто.
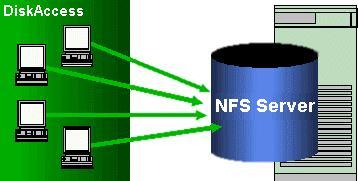 В ходе разворачивания стенда для экспериментов из нескольких идентичных серверов захотелось иметь возможность запускать нужные версии приложения без ручной работы по обновлению кода на куче хостов. Было решено запускать нужные программы с NFS-шары. Приложения были internal use only, одноразовые, причём написанные под конкретную задачу. Шара монтировалась в каталог /opt при загрузке и приложения оттуда запускались с помощью скрипта rc.local. Поскольку речь шла про экспериментальный стенд с очень частым изменением кода, играть в честного разработчика (пакеты, репозиторий, обновления, init.d скрипты) было лениво. Всё происходило под Debian Squeeze.
В ходе разворачивания стенда для экспериментов из нескольких идентичных серверов захотелось иметь возможность запускать нужные версии приложения без ручной работы по обновлению кода на куче хостов. Было решено запускать нужные программы с NFS-шары. Приложения были internal use only, одноразовые, причём написанные под конкретную задачу. Шара монтировалась в каталог /opt при загрузке и приложения оттуда запускались с помощью скрипта rc.local. Поскольку речь шла про экспериментальный стенд с очень частым изменением кода, играть в честного разработчика (пакеты, репозиторий, обновления, init.d скрипты) было лениво. Всё происходило под Debian Squeeze.
 В мире все примерно распределяется в соответствии с принципом Паретто. Меньшая часть — богатые, большая часть — бедные (читающий, ты входишь в золотой миллиард). Тоже касается и материалов о программировании. Порой очень сложно найти хоть что-нибудь не начального уровня.
В мире все примерно распределяется в соответствии с принципом Паретто. Меньшая часть — богатые, большая часть — бедные (читающий, ты входишь в золотой миллиард). Тоже касается и материалов о программировании. Порой очень сложно найти хоть что-нибудь не начального уровня.{kind=link}