До смешного простой код, который может сэкономить вам кучу времени в будущем. И как фанат автоматизации, который старается избегать любой однообразной и рутинной работы, я от таких решений просто в восторге.

Александр Еськов @Sistemaalexread-only
Специалист
Пароли в открытом доступе: ищем с помощью машинного обучения
Средний
18 мин
Туториал

Я больше 10 лет работаю в IT и знаю, что сложнее всего предотвратить риски, связанные с человеческим фактором.
Мы разрабатываем самые надежные способы защиты. Но всего один оставленный в открытом доступе пароль сведет все усилия к нулю. А чего только не отыщешь в тикетах Jira, правда?
Привет, меня зовут Александр Рахманный, я разработчик в команде информационной безопасности в Lamoda Tech. В этой статье поделюсь опытом, как мы ищем в корпоративных ресурсах чувствительные данные — пароли, токены и строки подключения — используя самописный ML-плагин. Рассказывать о реализации буду по шагам и с подробностями, чтобы вы могли создать такой инструмент у себя, даже если ML для вас — незнакомая технология.
Посмотрите, как Google отслеживает ваше местоположение. С Python, Jupyter, Pandas, Geopandas и Matplotlib
8 мин
Перевод
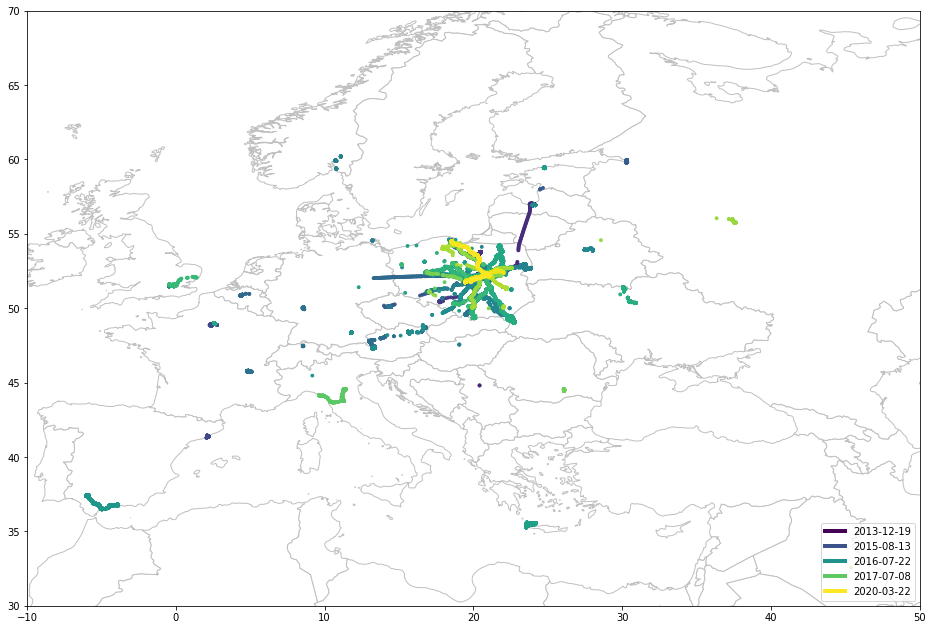
В отделе продаж можно услышать аббревиатуру ABC: Always Be Closing, что означает заключение сделки с покупателем. Последнее десятилетие породило еще одну аббревиатуру ABCD: Always Be Collecting Data.
Мы используем Google для почты, карт, фотографий, хранилищ, видео и многого другого. Мы используем Twitter, чтобы читать поток сознания одного президента. Мы используем Facebook для обмена сообщениями и… ну, почти все. Но наши родители пользуются им. Мы используем TikTok… Понятия не имею, зачем.
На самом деле, оказывается, что большинство из вышеперечисленного бесполезно… Ничего подобного, суть в том, что мы их используем. Мы их используем, и они бесплатны. В экономике XXI века, если вы не платите за товар, вы являетесь товаром.
Итак, короче говоря, я хотел выяснить, насколько корпорация Alphabet, владелец Google, обо мне знает. Крошечная доля, я посмотрел на историю геолокации. Я никогда не отключал службы определения местоположения, потому что ценил комфорт выше конфиденциальности. Плохая идея.
Как натренировать и использовать модель машинного обучения из Google таблиц с помощью BigQuery ML
6 мин

Электронные таблицы используются везде. Это один из самых удобных инструментов для повышения производительности. С их помощью можно быстро упорядочить, рассчитать и представить данные. Google Таблицы – это приложение для работы с электронными таблицами в составе сервиса Google Workspace, с которым активно работают более 2 миллиардов пользователей.
Машинное обучение также стало важным бизнес-инструментом. Когда появилась недорогая возможность высокоточного прогнозирования на основе данных, рынок стал развиваться по новому пути. По оценкам, каждый год доля машинного обучения в бизнесе будет увеличиваться более чем на 40 %.
Это наталкивает на мысль о том, что машинное обучение было бы разумно применять для анализа данных в таблицах. И это так! Тем более теперь для этого есть все средства. О них мы и поговорим в этой статье.
Учимся квантовому программированию с помощью примеров. Доклад Яндекса
12 мин
Сегодня любой желающий может воспользоваться методами квантового программирования, написать простой код на Python и запустить его на реальном квантовом вычислителе. Ришат Ибрагимов rishat_ibrahimov разобрал основы квантовых вычислений на примерах с кодом, показал, как запускать программы на локальном симуляторе и удаленном квантовом компьютере.
— Всем привет, меня зовут Ришат. Я почти три года работаю над качеством поиска Яндекса. Но поговорить сегодня хочу не о работе, а о том, чем я занимаюсь в свободное время. Занимаюсь я квантовой информатикой, а на самом деле — самыми разными моделями вычислений, в том числе квантовыми.
— Всем привет, меня зовут Ришат. Я почти три года работаю над качеством поиска Яндекса. Но поговорить сегодня хочу не о работе, а о том, чем я занимаюсь в свободное время. Занимаюсь я квантовой информатикой, а на самом деле — самыми разными моделями вычислений, в том числе квантовыми.
Физика и экономика. Гносеологическая разница и ее проявление в IT
21 мин
В мир IT я пришел из теоретической физики. Занимался, в основном, экономическими задачами. Занимался – это: анализ, ТЗ, постановка, проектирование, программирование. Естественно, я все время сопоставлял физический и экономический подходы к познанию законов природы и экономики соответственно. По этой теме созрела некая точка зрения. О ней и будет речь.
Кому на бюджете жить хорошо?
31 мин

ВСТУПЛЕНИЕ
В каком году — рассчитывай,
В какой земле — угадывай,
На столбовой дороженьке
Сошлись семь мужиков:
Семь временнообязанных,
Подтянутой губернии,
Уезда Терпигорева,
Пустопорожней волости,
Из смежных деревень:
Заплатова, Дырявина,
Разутова, Знобишина.
Горелова, Неелова —
Неурожайка тож,
Сошлися — и заспорили:
Кому живется весело,
Вольготно на Руси?
Н.НекрасовПару месяцев назад на одном IT мероприятии мне довелось лицезреть в работе Pandas. Парень, который с ним работал не делал ничего особенно удивительного. Но простые сложения значений, вычисления средних, группировки проиводились так виртуозно, что, даже при всей своей предвзятости к Питону, я был очарован. Манипуляции выполнялись на довольно приличных датасетах по данным капитального ремонта за период кажется с 2004 по 2019 год. Сотни тысяч строк, но все работало очень быстро.
В общем когда мне еще через пару месяцев пришлось кое-что анализировать, я решил попробовать сделать это с помощью Pandas. Провозился пару дней с тем, что с помощью Excel я бы смог сделать за день. Тем не менее мне удалось.
С апреля мы все сидим на карантине. Сидел я и думал, что бы мне такое сделать, чтобы не очень сложное и чтобы стильно и модно было. К тому времени я уже видел кучу всякой инфографики про коронавирус, про пожары в лесу, про выборы. Делать то, что уже делали не хотелось, да и браться сразу за сложное не решался, сомневаясь, что смогу закончить. Тут мне попалась какая-то статья про уже отшумевшее явление "barchart race" или по-русски "гонки столбчатых диаграмм". Вы можете подумать, что эта статья будет про barchart race. Да, но только отчасти. Barchart race будет только в конце, а статья скорее о том, как не обладая, какими-то выдающимися способностями и знаниями в области матана и прочей черной магии, можно сделать анализ больших данных и представить результат в доступной для широких масс форме. Итак, поехали.
Абелевскую премию по математике разделили двое пионеров в областях вероятностей и динамики
5 мин
Перевод
Хилель Фарстенберг, 84 лет, и Григорий Маргулис, 74 лет, профессора на пенсии, разделили математический эквивалент нобелевской премии

Хилель Фарстенберг
Двое математиков, продемонстрировавших, как недооценённое ответвление области исследований можно применить для решения важных задач, разделили между собой абелевскую премию этого года — математический эквивалент нобелевской премии.
Её получили Хилель Фарстенберг, 84 лет, из Еврейского университета в Иерусалиме, и Григорий Маргулис, 74 лет, советский и американский математик из Йельского университета. Оба – профессора на пенсии.
Премия, вручаемая Норвежской академией наук и литературы, была назначена «за новаторский подход использования методов из теории вероятностей и динамики в теории групп, теории чисел и комбинаторике».
Макросы для питониста. Доклад Яндекса
8 мин
Как можно расширить синтаксис Python и добавить в него необходимые возможности? Прошлым летом на PyCon я постарался разобрать эту тему. Из доклада можно узнать, как устроены библиотеки pytest, macropy, patterns и как они добиваются таких интересных результатов. В конце есть пример кодогенерации с помощью макросов в HyLang — Lisp-образного языка, бегущего поверх Python.
— Привет, ребята. Хочу в первую очередь поблагодарить организаторов PyCon. Я разработчик в Яндексе. Доклад будет совсем не про работу, а про экспериментальные вещи. Возможно, кого-то из вас они наведут на мысль, что в Python можно делать клевые штуки, о которых вы раньше даже не догадывались, не мыслили в эту сторону.
— Привет, ребята. Хочу в первую очередь поблагодарить организаторов PyCon. Я разработчик в Яндексе. Доклад будет совсем не про работу, а про экспериментальные вещи. Возможно, кого-то из вас они наведут на мысль, что в Python можно делать клевые штуки, о которых вы раньше даже не догадывались, не мыслили в эту сторону.
Что происходило с транспортом за последние две недели
15 мин

Автобусы помогут добраться до тех городов, куда не пройдут самолёты и поезда. Картинка от Safronov
По стране был объявлен «режим нового года», ну, то есть неделя выходных с работающими аптеками, магазинами и транспортом. Потом он плавно перешёл в режим чего-то непонятного, а потом в режим самоизоляции.
Основные статусы:
- Сначала были просто перекрыты многие внешние рейсы, осталось только сообщение между столицами. А с 00:00 27 марта приостановлено всё международное пассажирское авиасообщение, кроме чартерных рейсов для эвакуации жителей России из других стран. Наземные границы тоже закрылись. Есть информация о возможном существенном снижении пассажирских перевозок самолётами. Есть данные о продолжении полётов Аэрофлота. Есть данные и о том, что они начинают ставить борта на длительное хранение.
- Иностранцев не принимают в России до 1 мая.
- Населённость поездов уменьшилась, РЖД отменила 20 поездов и ещё с десяток пустила реже. Это малая доля в сравнении с масштабом пассажироперевозок, но это было уже около недели назад.
- Победа прекратила авиаперевозки с 1 апреля до конца мая.
- Появились схемы и инструкции: PDF, где в Приложении 2 закрепляется схема лечения лопинавиром и ритонавиром. Вот обновлённые рекомендации Минздрава, где схемы рассматриваются подробнее.
- Карелия — первый регион, остановивший общественный транспорт (возможно, потому что туда ломанулись люди на выходные отдыхать).
- Власти попросили BlaBlaCar приостановить все поездки. Это важно, потому что машины обеспечивают связность с теми мелкими населёнными пунктами, где нет автобусов-поездов-самолётов.
Расчеты по банковским картам в торговле — создание открытого датасета и инфографики в Google Data Studio
3 мин
Recovery Mode
Это моя первая публикация на Хабре. Я интересуюсь и отчасти практикую дата-журналистику и хотел бы поделится с вами инфографикой, иллюстрирующую расчеты по банковским картам в торговле. А также расшарить открытый датасет в Data.World, и рассказать о создании этого проекта.
Итак, итоговая инфографика:
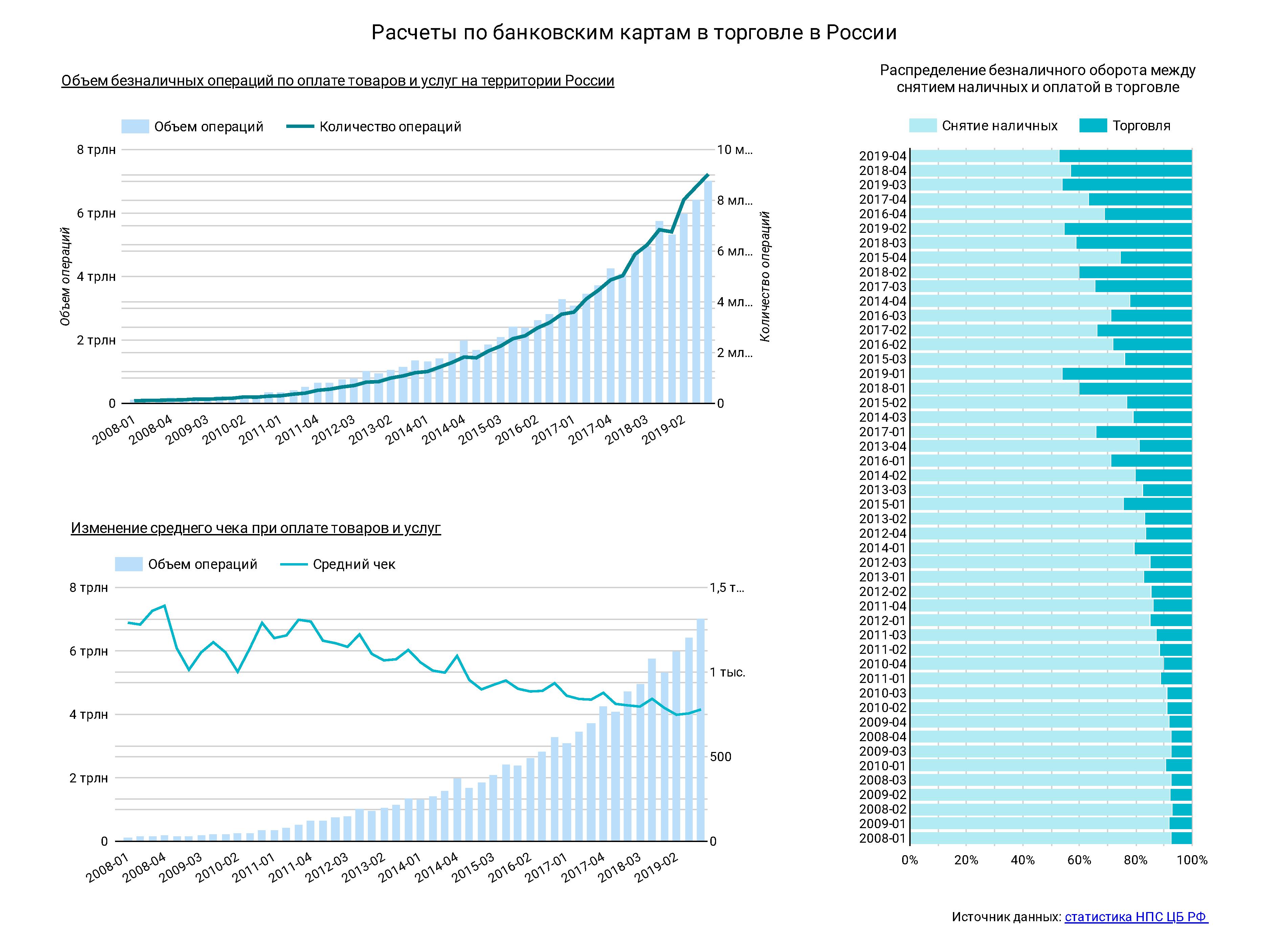
→ Ссылка на тот же отчет в гораздо более интересном интерактивном виде
→ Ссылка на открытый датасет (требуется регистрация на Data.World).
Итак, итоговая инфографика:
→ Ссылка на тот же отчет в гораздо более интересном интерактивном виде
→ Ссылка на открытый датасет (требуется регистрация на Data.World).
Кстати, к сожалению, не удалось встроить отчет в публикацию на Хабре ни через iframe, ни через тег oembed.
Распространение сферического коня в вакууме по территории РФ
5 мин
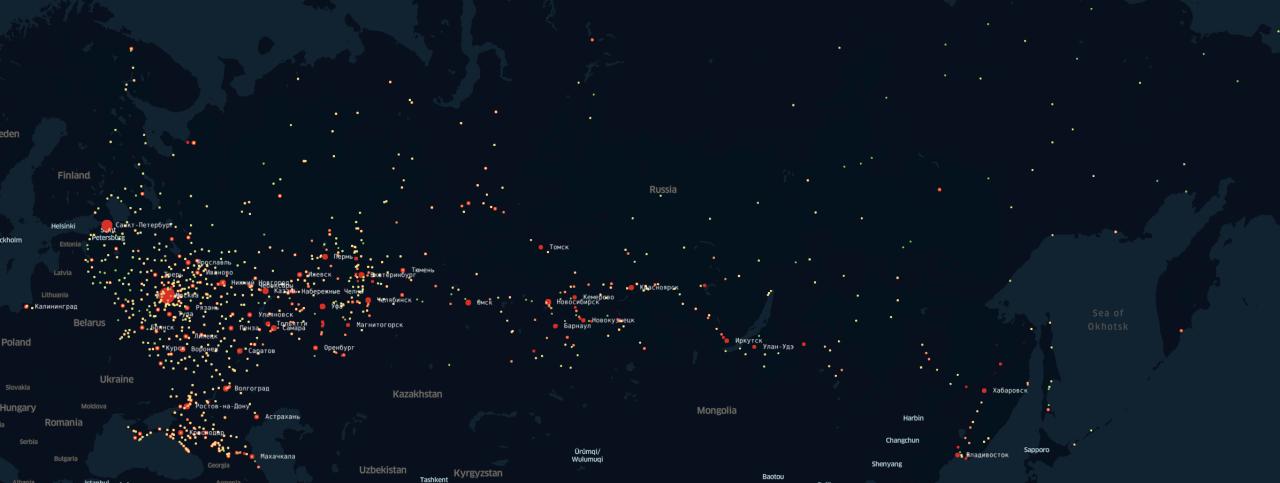
Привет от ODS. Мы откликнулись на идею tutu.ru поработать с их датасетом пассажиропотока РФ. И если в посте Milfgard огромная таблица выводов и научпоп, то мы хотим рассказать что под капотом.
Что, опять очередной пост про COVID-19? Да, но нет. Нам это было интересно именно с точки зрения математических методов и работы с интересным набором данных. Прежде, чем вы увидите под катом красивые картинки и графики, я обязан сказать несколько вещей:
- любое моделирование — это очень сложный процесс, внутри которого невероятное количество ЕСЛИ и ПРЕДПОЛОЖИМ. Мы о них расскажем.
- те, кто работал над этой статьей — не эпидемиологи или вирусологи. Мы просто группа любителей теории графов, практикующих методы моделирования сложных систем. Забавно, но именно в биоинформатике сейчас происходит наиболее существенный прогресс этой узкой области математики. Поэтому мы понимаем язык биологов, хоть и не умеем правильно обосновывать эпидемиологические модели и делать медицинские заключения.
- наша симуляция всего лишь распространение сферического коня в вакууме по территории РФ. Не стоит относиться к этому серьезно, но стоит задуматься об общей картине. Она определенно интересная.
- эта статья не существовала бы без датасета tutu.ru, за что им огромное спасибо.
- мы хотим пригласить других заинтересованных исследователей в ODS.ai и под инициативой ML for Social Good (канал #ml4sg в ODS) вместе улучшать эту модель, чтобы получить опыт и возможность применять ее в будущем. Все интересные задачи, которые мы еще не решили, будут помечены в статье как TODO.
Под катом — результаты нашего марш-броска на датасет.
Теория цвета, контраст
9 мин
Многие говорят, что цвет — это чисто субъективная вещь и в ней нет каких то правил или принципов. На самом же деле, как и в любой науке, здесь есть место и теории. Цвет помогает дополнить тот смысл и идею, которые вы хотите вложить в свою работу, и правильное его использование помогает сделать ваш продукт более заметным и профессионально выглядящим.
Многие исследователи занимались вопросами цвета, и одним из самых заметных, несомненно, был Иоханнес Иттен, автор книги «Искусство цвета». В своей работе автор рассматривает множество аспектов колористики: психологическое воздействие цвета, «вес» каждого оттенка, сочетание цвета и формы и многое другое.
Многие исследователи занимались вопросами цвета, и одним из самых заметных, несомненно, был Иоханнес Иттен, автор книги «Искусство цвета». В своей работе автор рассматривает множество аспектов колористики: психологическое воздействие цвета, «вес» каждого оттенка, сочетание цвета и формы и многое другое.
Ранжирование округов Москвы по стоимости аренды с Python
10 мин
Сейчас программирование все глубже и глубже проникает во все сферы жизни. А возможно это стало благодаря очень популярному сейчас python’у. Если еще лет 5 назад для анализа данных приходилось использовать целый пакет различных инструментов: C# для выгрузки (или ручки), Excel, MatLab, SQL, и постоянно “прыгать” туда сюда вычищая, сверяя и выверяя данные. То сейчас python, благодаря огромному количеству прекрасных библиотек и модулей, в первом приближении благополучно заменяет все эти инструменты, а в связке с SQL так вообще “горы свернуть можно”.
Итак, к чему я. Увлеклась я изучением такого популярного python’а. А лучший способ изучить что-либо, как вы знаете, — практика. А еще я интересуюсь недвижимостью. И попалась мне на глаза интересная задачка о недвижимости в Москве: проранжировать округа Москвы по усредненной стоимости аренды средней однушки? Батюшки, я подумала, да тут вам и геолокация, и выгрузка с сайта, и анализ данных — прекрасная практическая задача.
Воодушевившись замечательными статьями тут на Хабре (в конце статьи добавлю ссылки), приступим!
Итак, к чему я. Увлеклась я изучением такого популярного python’а. А лучший способ изучить что-либо, как вы знаете, — практика. А еще я интересуюсь недвижимостью. И попалась мне на глаза интересная задачка о недвижимости в Москве: проранжировать округа Москвы по усредненной стоимости аренды средней однушки? Батюшки, я подумала, да тут вам и геолокация, и выгрузка с сайта, и анализ данных — прекрасная практическая задача.
Воодушевившись замечательными статьями тут на Хабре (в конце статьи добавлю ссылки), приступим!
7 лет хайпа нейросетей в графиках и вдохновляющие перспективы Deep Learning 2020-х
14 мин
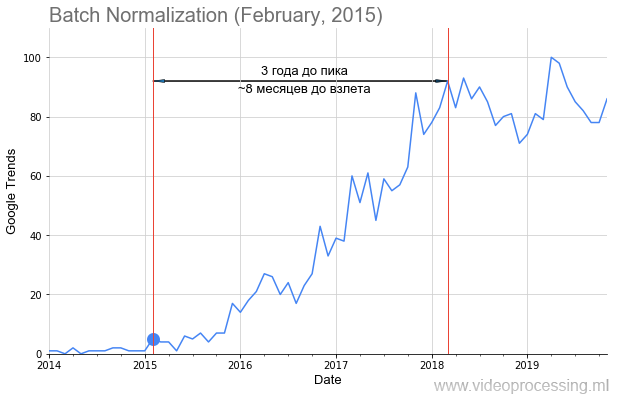
Новый год все ближе, скоро закончатся 2010-е годы, подарившие миру нашумевший ренессанс нейросетей. Мне не давала покоя

Понятно, что можно примерно посчитать количество статей по разным областям. Метод не идеальный, нужно учитывать подобласти, но в целом можно пробовать. Дарю идею, по Google Scholar (BatchNorm) это вполне реально! Можно считать новые датасеты, можно новые курсы. Ваш же покорный слуга, перебрав несколько вариантов, остановился на Google Trends (BatchNorm).
Мы с коллегами взяли запросы основных технологий ML/DL, например, Batch Normalization, как на картинке выше, точкой добавили дату публикации статьи и получили вполне себе график взлета популярности темы. Но не у всех тем
Кому интересно, что получилось — добро пожаловать под кат!
Большое интервью про Big Data: зачем за нами следят в соцсетях и кто продает наши данные?
24 мин
Disclaimer. Специалист по Big Data, Артур Хачуян, рассказал, как соцсети могут читать наши сообщения, как наш телефон нас подслушивает, и кому все это нужно. Эта статья — расшифровка большого интервью. Есть люди, которые экономят время и любят текст, есть те, кто не может на работе или в дороге смотреть видео, но с радостью читает Хабр, есть слабослышащие, для которых звуковая дорожка недоступна или сложна для восприятия. Мы решили для всех них и вас расшифровать отличный контент. Кто всё же предпочитает видео — ссылка в конце.

Каждый день мы что-то пишем, разыскиваем и выкладываем в интернете, и каждый день кто-то следит за нами по ту сторону экрана. Специальные программы сканируют фото, лайки и тексты, чтобы продать наши данные рекламным компаниям или полиции. Можно назвать это паранойей или научной фантастикой, но телефон, круг общения, переписка или ориентация — больше не секрет.
Курс «Основы эффективной работы с технологиями Wolfram»: более 13 часов видеолекций, теория и задачи
10 мин
Туториал

Все документы курса можно скачать здесь.
Этот курс я прочел пару лет назад для довольно обширной аудитории. Он содержит очень много информации о том, как устроена система Mathematica, Wolfram Cloud и язык Wolfram Language.
Однако, конечно, время не стоит на месте и за последнее время появилось очень много нового: от продвинутых возможностей работы с нейросетями до всевозможных веб-операций; теперь есть Wolfram Engine, который можно поставить на свой сервер и обращаться к нему, как к Python; можно строить всяческие географические визуализации или химические; есть огромные хранилища всевозможных данных, в том числе по машинному обучению; можно подключаться ко всевозможным базам данных; решать сложнейшие математические задачи и пр.
Все возможности технологий Wolfram трудно перечислить за пару абзацев или несколько минут.
Все это сподвигло меня сделать новый курс, на который сейчас идет регистрация.Уверен, открыв для себя возможности языка Wolfram Language, вы станете его использовать все чаще и чаще, решая свои задачи быстро и эффективно в самых разных областых: от науки до автоматизации дизайна или парсинга сайтов, от нейросетей до обработки иллюстраций, от визуализации молекул до построения мощных интерактивов.
Алексей Савватеев: Модели интернета и социальных сетей
8 мин
«Единственный смысл существование экономики — это воодушевление математиков на новые подвиги.»

В 2013 году Алексей Савватеев прочитал несколько лекций по моделям соцсетей и интернета. Я нашел эту тему очень любопытной и незаслуженно забытой. Попробуем разобраться в вопросе. А ещё мне интересно узнать, как изменилась ситуация с тех пор и какие полезные публикации есть в этой области.
И в интернете, и в биологии соцсети проявляют свойства, которые по отдельности описываются моделями, но все вместе — ставят в тупик современную математику. Савватеев утверждает, что «тот, кто с этим разберется получит Нобелевскую премию». Будущее будет зависеть от способности работать с сетями.
Ниже приводится скомпилированная выжимка из трёх видеозаписей лекций, само видео есть в конце. (Пост выглядит как набор слайдов с цитатами лектора, связать всё в единый и прилизанный текст у меня не хватает способностей к русскому языку и математике, но тема очень важная, поэтому хочу опубликовать.)
В 2013 году Алексей Савватеев прочитал несколько лекций по моделям соцсетей и интернета. Я нашел эту тему очень любопытной и незаслуженно забытой. Попробуем разобраться в вопросе. А ещё мне интересно узнать, как изменилась ситуация с тех пор и какие полезные публикации есть в этой области.
И в интернете, и в биологии соцсети проявляют свойства, которые по отдельности описываются моделями, но все вместе — ставят в тупик современную математику. Савватеев утверждает, что «тот, кто с этим разберется получит Нобелевскую премию». Будущее будет зависеть от способности работать с сетями.
Ниже приводится скомпилированная выжимка из трёх видеозаписей лекций, само видео есть в конце. (Пост выглядит как набор слайдов с цитатами лектора, связать всё в единый и прилизанный текст у меня не хватает способностей к русскому языку и математике, но тема очень важная, поэтому хочу опубликовать.)
Дискретная производная или Коротко о том, как суммировать ряды
3 мин
Вступление
Бывало когда-нибудь такое, что вы хотите просуммировать какой-то бесконечный ряд, но не можете подобрать частичную сумму ряда? Вы все ещё не пользовались дискретной производной? Тогда мы идём к вам!
Определение
Дискретной производной последовательности назовем такую последовательность , что для любых натуральных выполняется:
Рассмотрим примеры:
Ну, суть вы поняли. Чем-то напоминает производную функции, правда? Мы поняли как вычислять дискретные производные «простейших» последовательностей. Кхм, но что делать с суммой, разностью, произведением и частным последовательностей? У «обычной» производной есть некоторые правила дифференцирования. Давайте-ка придумаем для дискретной!
Новые подходы к построению СКУД при использовании WEB-технологий
4 мин
Развитие технологий оказало значительное влияние на архитектуру систем контроля доступа. Проследив путь ее развития, можно предсказать, что же ждет нас в ближайшем будущем.
Давным-давно компьютерные сети еще были большой редкостью. И тогдашние СКУД строились следующим образом: мастер — контроллер обслуживал ограниченное количество контроллеров, а компьютер выступал в роли терминала для его программирования и отображения информации. Логику работы определял мастер-контроллер, управляющий вторичными контроллерами.
Вторичные контроллеры не могли обмениваться информацией напрямую друг с другом, обмен происходил через мастер-контроллер. Такая модель накладывала значительные ограничения на развитие систем контроля доступа.
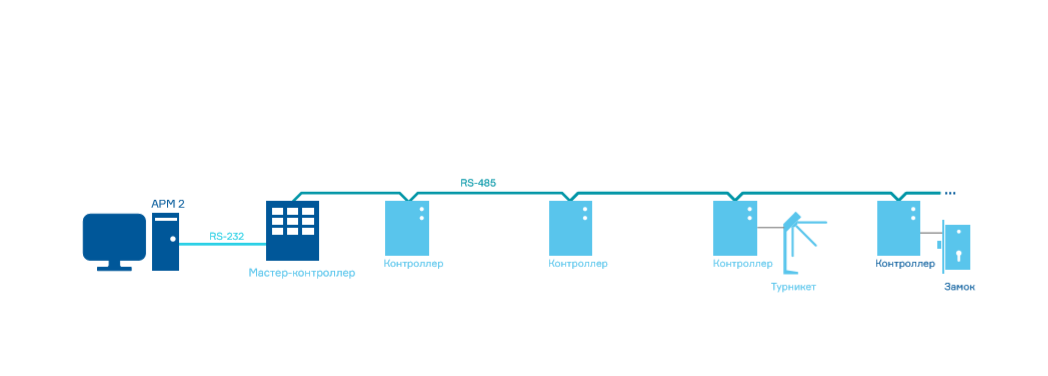
Прошлое
Давным-давно компьютерные сети еще были большой редкостью. И тогдашние СКУД строились следующим образом: мастер — контроллер обслуживал ограниченное количество контроллеров, а компьютер выступал в роли терминала для его программирования и отображения информации. Логику работы определял мастер-контроллер, управляющий вторичными контроллерами.
Вторичные контроллеры не могли обмениваться информацией напрямую друг с другом, обмен происходил через мастер-контроллер. Такая модель накладывала значительные ограничения на развитие систем контроля доступа.