Не всегда можно записать аудио в идеальной тишине
Довольно давно мы сделали у себя в целом простой нетребовательный денойз, а выложить модели как-то руки всё не доходили. Решили наконец-то исправить данное недоразумение.

Machine Learning / Data Science
Не всегда можно записать аудио в идеальной тишине
Довольно давно мы сделали у себя в целом простой нетребовательный денойз, а выложить модели как-то руки всё не доходили. Решили наконец-то исправить данное недоразумение.


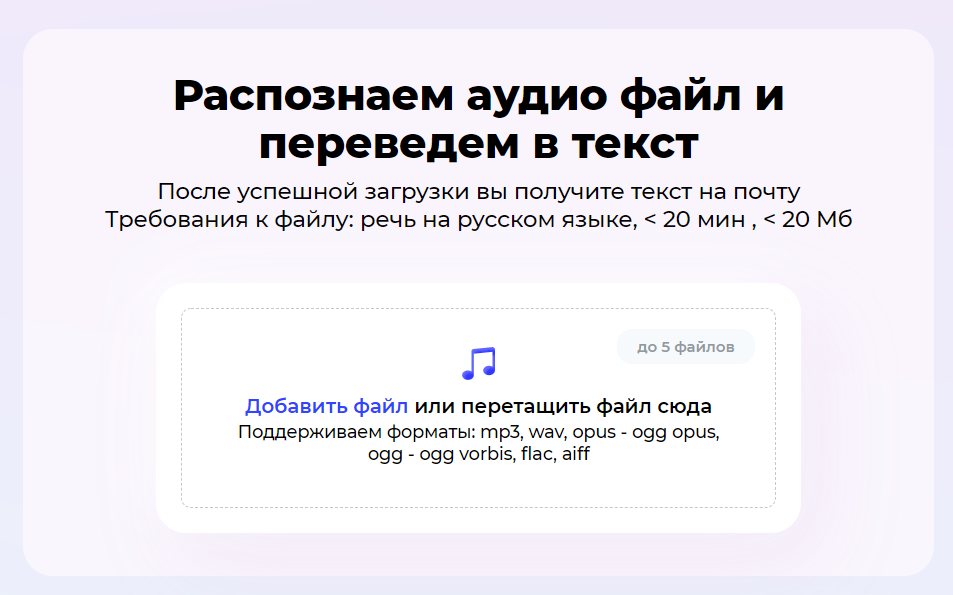
Сейчас для всех желающих доступны два наших сервиса для распознавания речи:
Сервис написан нашими собственными силами, работает на нашем собственном движке распознавания речи, без проксирования во внешние сервисы и с минимально возможным количеством зависимостей. В случае нарушения связности возможен оперативный перевод хостинга в другие регионы.
Мы провели и продолжаем работу над ошибками и внесли ряд улучшений для пользователей, о которых мы бы хотели рассказать.

Если вам зачем-то понадобилась полная адресная база России, то самый простой и дешевый способ ее заполучить — это скачать на сайте налоговой. Да, вот так вот просто все. Ну почти.
Да, это полная официальная адресная база России, просто в открытом доступе, никто ничего не спрашивает, просто раздают. Сделали на наши налоги, и честно всем, как скамейку в парке, отдают в пользование. Прекрасно? Да!
"В чем же подвох?", — спросите вы, прищурившись.
Кратко: формат ужасен, документация очень плоха и должного единообразия данных не наблюдается, чем успешно пользуются коммерческие компании, перепродающие бесплатные данные (иногда пылесосят имейлы). Но такую несправедливость можно исправить.
При решении задач, связанных с распознаванием (Speech-To-Text) и генерацией (Text-To-Speech) речи важно, чтобы транскрипт соответствовал тому, что произнёс говорящий — то есть реально устной речи. Это означает, что прежде чем письменная речь станет нашим транскриптом, её нужно нормализовать.
Другими словами, текст нужно провести через несколько этапов:
1984 год -> тысяча девятьсот восемьдесят четвёртый год;2 мин. ненависти -> две минуты ненависти; Orwell -> Оруэлл и т.д.
В этой статье я коротко расскажу о том, как развивалась нормализация в датасете русской речи Open_STT, какие инструменты использовались и о нашем подходе к задаче.
Как вишенка на торте, мы решили выложить наш нормализатор на базе seq2seq в открытый доступ: ссылка на github. Он максимально прост в использовании и вызывается одним методом:
norm = Normalizer()
result = norm.norm_text('С 9 до 11 котики кушали whiskas')>>> 'С девяти до одиннадцати котики кушали уискас'

После релиза нашей первой модели, расставляющей знаки препинания и большие буквы, было много пожеланий доработать её, чтобы она могла обрабатывать тексты целиком, а не отдельные предложения. Это коллективное пожелание и было осуществлено в нашей новой версии модели.
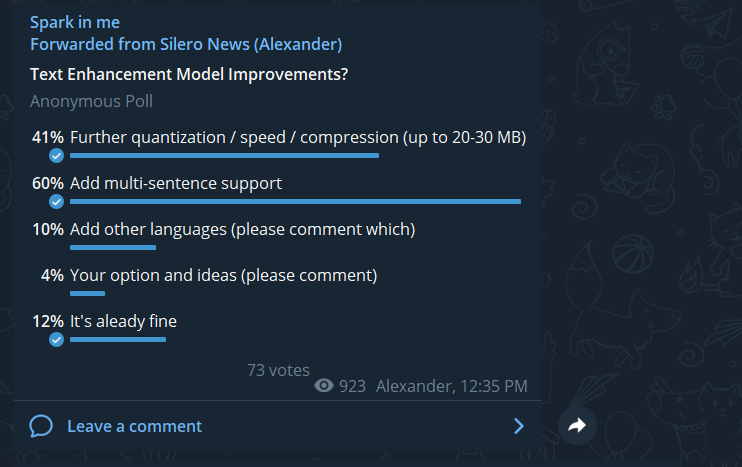
В целом, архитектура и датасеты остались прежними. Что изменилось:

Очень часто при работе мы обращаем внимание на то, что все люди знают, что такое распознавание речи, но не знают, что такое Voice Activity Detector (VAD) или детектор речи. А ведь именно VAD на самом деле самый важный алгоритм при работе с речью людей в естественной среде обитания.
Как ни странно, если поискать поддерживаемые и высококачественные решения данной задачи в публичном доступе — найдутся буквально пара проектов достаточного уровня. Но вот незадача — академические решения тяжелы (и иногда работают запретительно долго) и зачастую принимают только целые аудио на вход (нельзя использовать потоково). Решение от Google (WebRTC) очень быстрое но плохо отличает речь от шума (но его можно использовать потоково). А некоторые коммерческие решения "привязаны" к личному кабинету и шлют какую-то телеметрию.
Мы решили исправить это недоразумение и сделать уникальный VAD мирового уровня (судите сами по метрикам), который работает на 1 ядре процессора с задержкой в 1 миллисекунду на кусочках аудио от 30 миллисекунд. В этой статье мы расскажем вам, что такое VAD, покажем на примерах как использовать его и наглядно потестировать на своем голосе.

Задачи автоматического перевода слов в фонемы, автоматической простановки ударения, и автоматической простановки буквы ё сейчас решаются довольно успешно даже на уровне открытых решений (например: 1, 2, 3).
Тем не менее, практически ни одно открытое решение не позволяет разрешать неопределённости, возникающие при обработке слов-омографов. И оказывается, что эта на первый взгляд незначительная деталь очень сильно влияет на восприятие результатов алгоритмов (будь то G2P или автоматические ударения). В статье предлагаются некоторые способы решения проблемы омографов, а также указывается основная причина того, что эта задача до сих пор не решена публично.
Представляем вам перевод статьи по ссылке и оригинальный докеризированный код. Данное решение позволяет попасть примерно в топ-100 на приватном лидерборде на втором этапе конкурса среди общего числа участников в районе нескольких тысяч, используя только одну модель на одном фолде без ансамблей и без дополнительного пост-процессинга. С учетом нестабильности целевой метрики на соревновании, я полагаю, что добавление нескольких описанных ниже фишек в принципе может также сильно улучшить и этот результат, если вы захотите использовать подобное решение для своих задач.
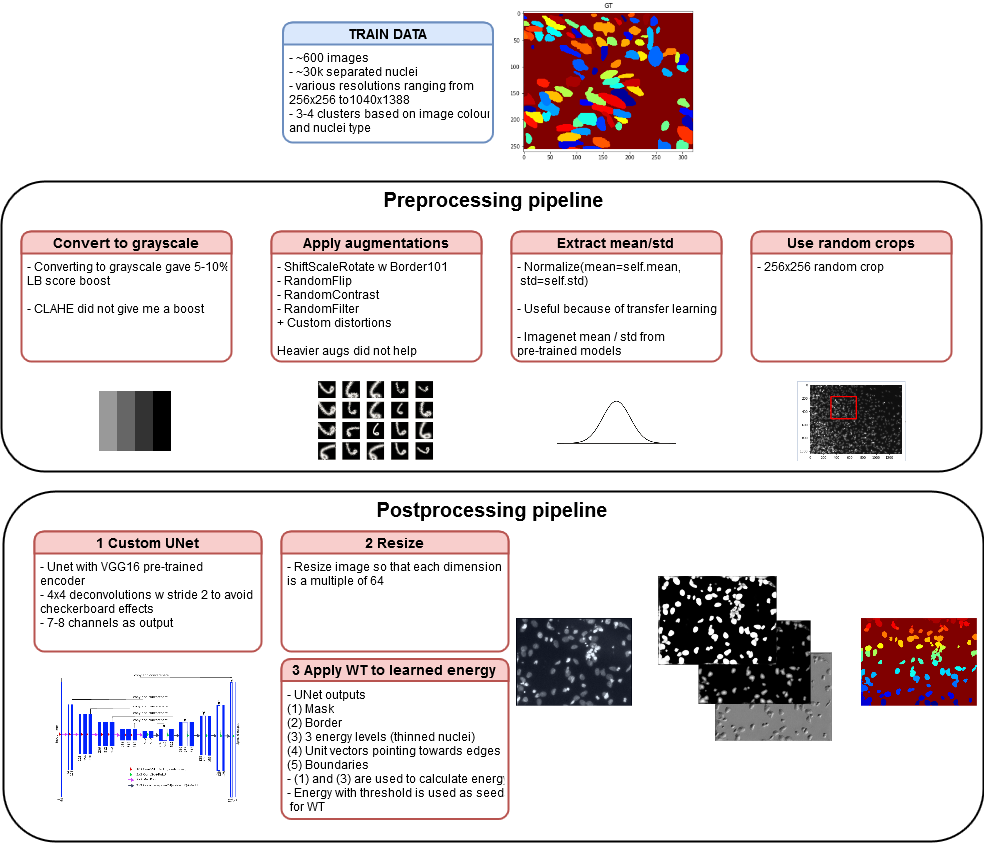
описание пайплайна решения