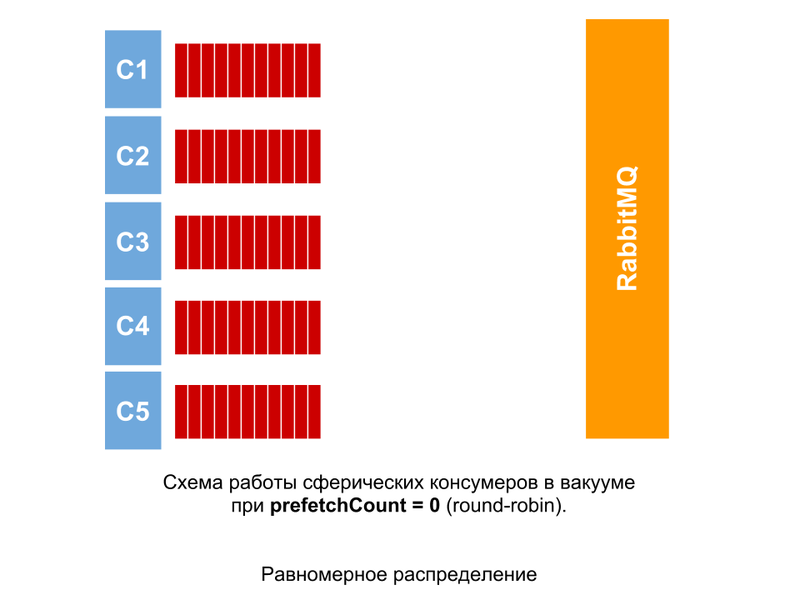
Развивая любой продукт, будь то видеосервис или лента, истории или статьи, хочется уметь измерять условное «счастье» пользователя. Понимать, делаем мы своими изменениями лучше или хуже, корректировать направление развития продукта, опираясь не на интуицию и собственные ощущения, а на метрики и цифры, в которые можно верить.
В этой статье я расскажу, как нам удалось запустить продуктовую статистику и аналитику на сервисе с 97-миллионной месячной аудиторией, получив при этом чрезвычайно высокую производительность аналитических запросов. Речь пойдёт о ClickHouse, используемых движках и особенностях запросов. Я опишу подход к агрегации данных, который позволяет нам за доли секунды получать сложные метрики, и расскажу о преобразовании и тестировании данных.
Сейчас у нас около 6 миллиардов продуктовых событий в сутки, в ближайшее время дойдём до 20–25 миллиардов. А дальше — не такими быстрыми темпами поднимемся до 40–50 миллиардов к концу года, когда опишем все интересующие нас продуктовые события.
1 rows in set. Elapsed: 0.287 sec. Processed 59.85 billion rows, 59.85 GB (208.16 billion rows/s., 208.16 GB/s.)
Подробности под катом.