Начало
Я продолжаю серию публикаций-исследований на тему структурного анализа русскоязычного сегмента
Живого Журнала. Первая
публикация была посвящена некоторому анализу аудиторий 10-ти топовых блоггеров. Во время ее подготовки был собран граф связей русского ЖЖ, охватывающий
более 2-х млн. блогов и 58 млн. связей между ними. К этому графу я еще вернусь в следующих сериях (пока я еще не осмыслил его), а сегодня о другом. А именно, о том
кто, как часто и кого комментирует в самом бурлящем разборками и дискуссиями уголке ЖЖ — в журналах из ТОП-500.
Взяв за основу состояние ЖЖ-рейтинга на начало апреля и отщипнув от него
500 верхних позиций я запустил сбор данных по следующей методике. У каждого блога из списка запрашивались
25 последних публикаций (доступно через штатные средства ЖЖ). Из каждой публикации вытаскивался список комментаторов (имя, id-комментария, место комментария в дереве) если, конечно, комментарии к записи открыты для посторонних.
Штатные средства ЖЖ такого не позволяют, попытки сделать финт ушами и ободрать RSS-выдачу поиска по блогам от Яндекса натыкались на очень странное и несколько нелогичное поведение этой выдачи (это не претензия, это просто факт), поэтому информацию о структуре комментариев пришлось извлекать из страниц журналов. Но это оказалось к лучшему :) Кстати, если что: DDos на ЖЖ — это не я :)
В итоге, после нескольких дней сбора информации (первоначальная версия краулера была не безглючной, ЖЖ притормаживал — в это время на него был очередной ДДоС) получились вот такие исходные данные:
487 журналов, имеющих хотя бы один откомментированный пост;
10546 постов, имеющих хотя бы один комментарий;
809563 комментариев (без учета анонимных), из них
115326 (14,2%) — ответы владельцев журналов;
114412 комментаторов, из них
3884 (3,4%) залогинены с помощью внешних сервисов (twitter, facebook и т.д.)
Далее в программе:
1. Статистика различных характеристик журналов из TOP-500
2. Некоторые неявные, но любопытные рейтинги
3. Поиск ответа «как стать популярным блоггером» с помощью кластерного и корреляционного анализа (это, правда, будет во второй части исследования)


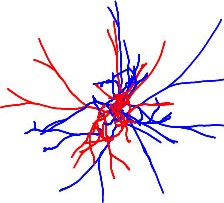




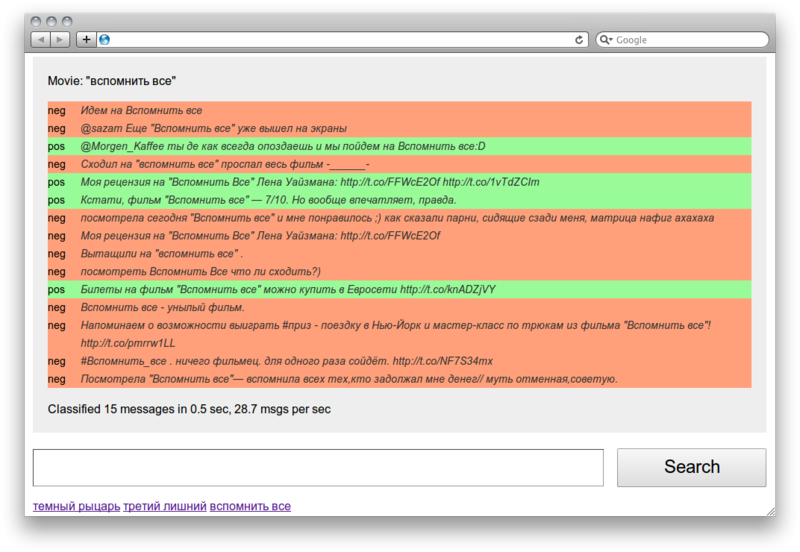
 Листая страницы хаба «Алгоритмы», наткнулся на
Листая страницы хаба «Алгоритмы», наткнулся на 





{kind=link}
{kind=link}