
1. Введение
Всем нам известна проблема курицы и яйца: работодатели не хотят брать на работу выпускников без опыта работы, но где же в таком случае выпускникам получить опыт работы? В микроэлектронике эта проблема стоит особо остро ввиду требуемого огромного количества специфического опыта. Наши ВУЗы с советских времен знамениты широчайшей теоретической подготовкой, которая должна помочь выпускнику в любой сложной ситуации в жизни. Однако, современная индустрия требует практического опыта. Добавим сюда еще отсутствие мотивации, приводящее к тому, что по специальности работает процентов 15% выпускников, и получим жесточайший кадровый голод в отрасли, которая очень требовательна к качеству кадров. А ведь если бы каждый студент мог "поморгать лампочкой" со своего собственного кристалла ситуация могла бы развиваться совсем иначе.
Рисунок 1. КДПВ
Что же мешает таким грандам подготовки кадров отечественной микроэлектроники, как, например, МИФИ и МИЭТ, поступать аналогично своим зарубежным коллегам (например, MIT или UZH), а именно — давать возможность студентами-дипломникам выпускать свои собственные кристаллы? Можно, конечно, предположить, что выпуск собственного кристалла занятие крайне долгое, сложное и дорогое, а потому для института — дорого, а для студента — непосильно. Однако, это не так. Давайте же взглянем на одну из доступных технологий на отечественном рынке микроэлектроники, знакомство с которой позволит студенту стать значительно более привлекательным в плане будущего трудоустройства, а предложение которой для студента — позволит университету значительно поднять свой рейтинг в глазах абитуриентов и работодателей.
 Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.
Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.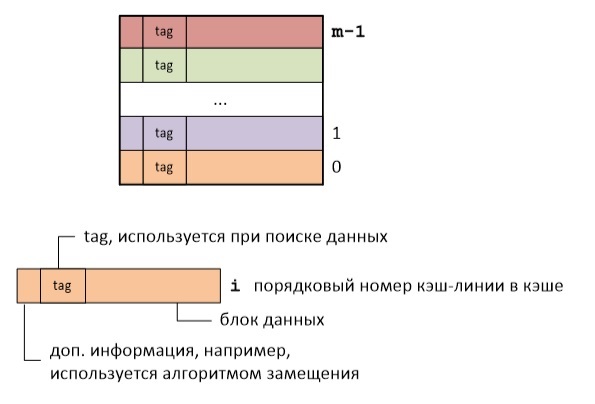

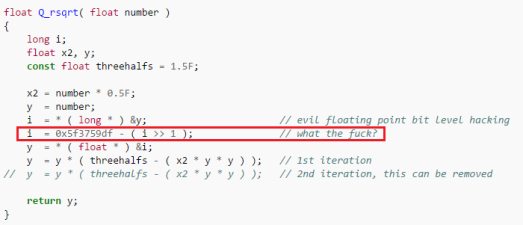
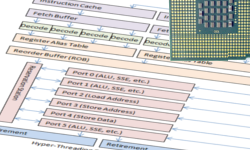 Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.
Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.