Оглавление (на данный момент)
Часть 1. Описание, операции, применения.
Часть 2. Ценная информация в дереве и множественные операции с ней.
Часть 3. Декартово дерево по неявному ключу.
To be continued...
Декартово дерево (cartesian tree, treap) — красивая и легко реализующаяся структура данных, которая с минимальными усилиями позволит вам производить многие скоростные операции над массивами ваших данных. Что характерно, на Хабрахабре единственное его упоминание я нашел в
обзорном посте многоуважаемого
winger, но тогда продолжение тому циклу так и не последовало. Обидно, кстати.
Я постараюсь покрыть все, что мне известно по теме — несмотря на то, что известно мне сравнительно не так уж много, материала вполне хватит поста на два, а то и на три. Все алгоритмы иллюстрируются исходниками на C# (а так как я любитель функционального программирования, то где-нибудь в послесловии речь зайдет и о F# — но это читать не обязательно :). Итак, приступим.
Введение
В качестве введения рекомендую прочесть
пост про двоичные деревья поиска того же
winger, поскольку без понимания того, что такое дерево, дерево поиска, а так же без знания
оценок сложности алгоритма многое из материала данной статьи останется для вас китайской грамотой. Обидно, правда?
Следующий пункт нашей обязательной программы —
куча (heap). Думаю, также многим известная структура данных, однако краткий обзор я все же приведу.
Представьте себе двоичное дерево с какими-то данными (ключами) в вершинах. И для каждой вершины мы в обязательном порядке требуем следующее: ее ключ строго больше, чем ключи ее непосредственных сыновей. Вот небольшой пример корректной кучи:
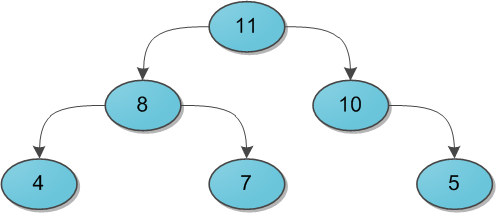
На заметку сразу скажу, что совершенно не обязательно думать про кучу исключительно как структуру, у которой родитель больше, чем его потомки. Никто не запрещает взять противоположный вариант и считать, что родитель меньше потомков — главное, выберите что-то одно для всего дерева. Для нужд этой статьи гораздо удобнее будет использовать вариант со знаком «больше».
Сейчас за кадром остается вопрос, каким образом в кучу можно добавлять и удалять из нее элементы. Во-первых, эти алгоритмы требуют отдельного места на осмотр, а во-вторых, нам они все равно не понадобятся.









 Разработки Синезис не ограничиваются одной лишь видеоаналитикой. Мы занимаемся и аудиоаналитикой. Вот о ней-то мы и хотели сегодня вам рассказать. Из этой статьи вы узнаете о наиболее известных аудиоаналитических системах, а также алгоритмах и их специфике. В конце материала – традиционно – список источников и полезных ссылок, в том числе аудиобиблиотек.
Разработки Синезис не ограничиваются одной лишь видеоаналитикой. Мы занимаемся и аудиоаналитикой. Вот о ней-то мы и хотели сегодня вам рассказать. Из этой статьи вы узнаете о наиболее известных аудиоаналитических системах, а также алгоритмах и их специфике. В конце материала – традиционно – список источников и полезных ссылок, в том числе аудиобиблиотек.
