Перестал запускаться Nexus, чтобы отдебажить что произошло - потребовалось немного телепатии. Надеюсь, некоторым помогут мои изыскания.
Нечеткий поиск (fuzzy search) в реляционных базах данных
4 min
Для поиска нужной информации на веб-сайтах и в мобильных приложениях часто используется поиск по словам или фразам, которые пользователь свободно вводит с клавиатуры (а не выбирает например из списка). Естественно, что пользователь может допускать ошибки и опечатки. В этом случае полнотекстовый поиск, полнотекстовые индексы, которые реализованы в большинстве баз данных не дают ожидаемого результата и практически бесполезны. Такой функционал все чаще реализуют на основе elasticsearch.
Решения с использованием elasticsearch имеют один существенный недостаток — очень большая вероятность рассогласования основной базы данных, например PostgreSQL, MySQL, mongodb и elasticsearch, в которой хранятся индексы для поиска.
Решения с использованием elasticsearch имеют один существенный недостаток — очень большая вероятность рассогласования основной базы данных, например PostgreSQL, MySQL, mongodb и elasticsearch, в которой хранятся индексы для поиска.
OrientDB — простой пример работы с графами для начинающих
3 min
OrientDB — взгляд человека, который привык работать с реляционными базами данных.
Напомню, что OrientDB — графовая, документно-ориентированная база данных, реализованная на Java.

Решил написать статью, для новичков, т.к в начале сложнее всего, а на рус. вводых статей с доходчивыми примерами практически нет.
Напомню, что OrientDB — графовая, документно-ориентированная база данных, реализованная на Java.
Решил написать статью, для новичков, т.к в начале сложнее всего, а на рус. вводых статей с доходчивыми примерами практически нет.
Не пора ли реляционным базам данных на свалку истории?
10 min
Здравствуйте, меня зовут Дмитрий Карловский и я… антиконформист, то есть человек, который не держится за свои привычки и всегда готов их поменять, если в том есть необходимость. Например, как и многие разработчики, я начинал изучение баз данных с реляционных. Хотя реляционная алгебра и довольно красива в своей простоте, я постоянно ловил себя на мысли, что пытаюсь впихнуть круглую фигуру в квадратное отверстие и получалось как-то не герметично.

Нет, я не буду рассказывать вам про MongoDB или ещё какую неполноценную «убийцу SQL». Статей на тему «SQL vs NoSQL» сравнивающих на самом деле реляционные субд с документными и так полно:
Но у большинства из них есть фатальный недостаток — авторы просто не в курсе, что моделей данных в СУБД есть куда больше, чем два упомянутых: от узкоспециализированных «словарей», то универсальных «графов». А популярные «реляционные» и «документные» находятся лишь где-то по середине между универсальностью и специализированностью.
Давайте сравним типичных представителей упомянутых типов СУБД (от большего к меньшему).
Нет, я не буду рассказывать вам про MongoDB или ещё какую неполноценную «убийцу SQL». Статей на тему «SQL vs NoSQL» сравнивающих на самом деле реляционные субд с документными и так полно:
- MongoDB или как разлюбить SQL
- Реляционные базы данных обречены?
- NoSQL базы данных: понимаем суть
- Почему нужно 1000 раз подумать, прежде чем использовать noSQL
- SQL — гибок или почему я боюсь NoSQL
- NoSQL и Big Data – обман трудящихся?
- Чем поможет архитектору «NoSQL» и… поможет ли?
- Сравнение производительности MongoDB vs PostgreSQL. Часть I: No index
- Сравнение производительности MongoDB vs PostgreSQL. Часть II: Index
- Разбираем ACID по буквам в NoSQL
- Почему вы никогда не должны использовать MongoDB
- Почему мы выбрали MongoDB
- Недостатки RDBMS или RDBMS vs NoSQL
- Почему вы никогда не должны говорить «никогда»
- Еж с ужом в одной корзине, а также немного об отсутствии схемы
- Почему реляционные СУБД отлично подходят для стартапов: Пример из истории разработки мессенджера Kato
- Прощай, MongoDB, здравствуй, PostgreSQL
Но у большинства из них есть фатальный недостаток — авторы просто не в курсе, что моделей данных в СУБД есть куда больше, чем два упомянутых: от узкоспециализированных «словарей», то универсальных «графов». А популярные «реляционные» и «документные» находятся лишь где-то по середине между универсальностью и специализированностью.
Давайте сравним типичных представителей упомянутых типов СУБД (от большего к меньшему).
- Популярность: Oracle, MongoDB, Redis, HBase, OrientDB.
- Функциональность: OrientDB, Oracle, MongoDB, HBase, Redis.
- Скорость: очень сильно зависит от задачи, данных и реализации приложения. Я пересмотрел кучу бенчмарков, везде всё по разному.
Кластеризация и классификация больших Текстовых данных с помощью машинного обучения на Java. Статья #2 — Алгоритмы
18 min

Привет, Хабр! Сегодня будет продолжение темы Кластеризация и классификация больших Текстовых данных с помощью машинного обучения на Java. Данная статья является продолжением первой статьи.
Статья будет содержать Теорию, и реализацию алгоритмов который я применял.
Свой сервис отложенного постинга и почти без кода
7 min
Tutorial
Если вы владеете Telegram-каналом (или несколькими), раскрученным аккаунтом в Instagram или любой другой социальной сети, то уже наверняка задавались вопросом: А как мне планировать посты заранее? Существует очень много разных сервисов, которые решают эту задачу. Но по тем или иным причинам они могут не подходить: где-то цена большая, где-то функционал беден, а где-то вообще страшно оставлять логин-пароль от своего раскрученного аккаунта. Сегодня я расскажу и покажу как на основе нашей платформы для разработки бизнес приложений с открытым кодом Orienteer сделать свой собственный сервис буквально за 60 минут! Заинтересовал? Проваливаемся под кат.
Инструменты Node.js разработчика. Какие ODM нам нужны
6 min
ODM - Object Document Mapper - используется преимущественно для доступа к документоориенриирвоанным базам данных, к которым относятся MongoDB, CouchDB, ArangoDB, OrientDB (последние две базы данных гибридные) и некоторые другие.
Прежде чем перейти к рассмотрению вопроса, озвученного в названии сообщения, приведу статистику скачивания пакетов из публичного регистра npm.
Кластеризация и классификация больших Текстовых данных с помощью машинного обучения на Java. Статья #1 — Теория
19 min

Данная статья будет состоять из 3 частей (Теория/Методы и алгоритмы для решение задач/Разработка и реализация на Java) для описания полной картины. Первая статья будет включать только теорию, чтобы подготовить умы читателей.
Цель статьи:
- Частичная или полная автоматизация задачи кластеризации и классификации больших данных, а именно текстовых данных.
- Применение алгоритмов машинного обучение “без учителя” (кластеризация) и “с учителем” (классификация).
- Анализ текущих решений задач.
Задачки, которые будут рассматриваться в целом:
- Разработка и применение алгоритмов и методов обработки естественного языка.
- Разработка и применение методов кластеризации для определения кластерных групп входных документов.
- Применение методов классификации для определения предмета каждых кластерных групп.
- Разработка веб-интерфейса на основе Java Vaadin
Гипотезы, которые я вывел из задачки и при обучении теории:
- Классификация кластерных групп определяет абстрактные и более ценные скрытые знания, игнорируя шумы, чем классификация отдельных объектов.
- Точность кластеризации прямо пропорциональна количеству кластерных групп и обратно пропорциональна количеству объектов в одной кластерной группе.
Забегая вперед, кому интересен сам алгоритм, вот обзор.
Алгоритм программного обеспечение для машинного обучения состоит из 3 основных частей:
- Обработка естественного языка.
- токенизация;
- лемматизация;
- стоп-листинг;
- частота слов;
- Методы кластеризации.
TF-IDF ;
SVD;
нахождение кластерных групп;
- Методы классификации – Aylien API.
Итак, начнем теорию.
Свой BaaS c моделированием предметной области, скриптами и многим другим за полчаса
4 min
Сегодня расскажем и покажем как за полчаса поднять свой Backend as a Service (BaaS) с весьма интересными возможностями.

BaaS — это веб-приложение, которое работает в облаке и предоставляет все необходимое для бизнес/мобильных приложений и сайтов (front-end). BaaS как минимум позволяет:
BaaS — это веб-приложение, которое работает в облаке и предоставляет все необходимое для бизнес/мобильных приложений и сайтов (front-end). BaaS как минимум позволяет:
- Управлять пользователями и ролями
- Моделировать предметную область
- Получать доступ к данным через REST
- Управлять самими данными (база данных)
Пилим каталог товаров не притрагиваясь к реляционной алгебре
7 min
Здравствуйте, меня зовут Дмитрий Карловский и я… давно не занимался бэкендом, но на днях вдруг наткнулся на мучения SbWereWolf по натягиванию ужа на ежа и не смог удержаться от соблазна сдуть пыль со своего мульти-инструмента OrientDB да оттяпать им чего-нибудь этакого.
Итак, мастерить мы сегодня будем базу данных для интернет-магазина с поиском товаров по параметрам, полнотекстовым поиском, локализацией, автоматическим формированием рубрикатора и мастера добавления товара.
Разбирать мы будем вот этот вот реляционный звездолёт:
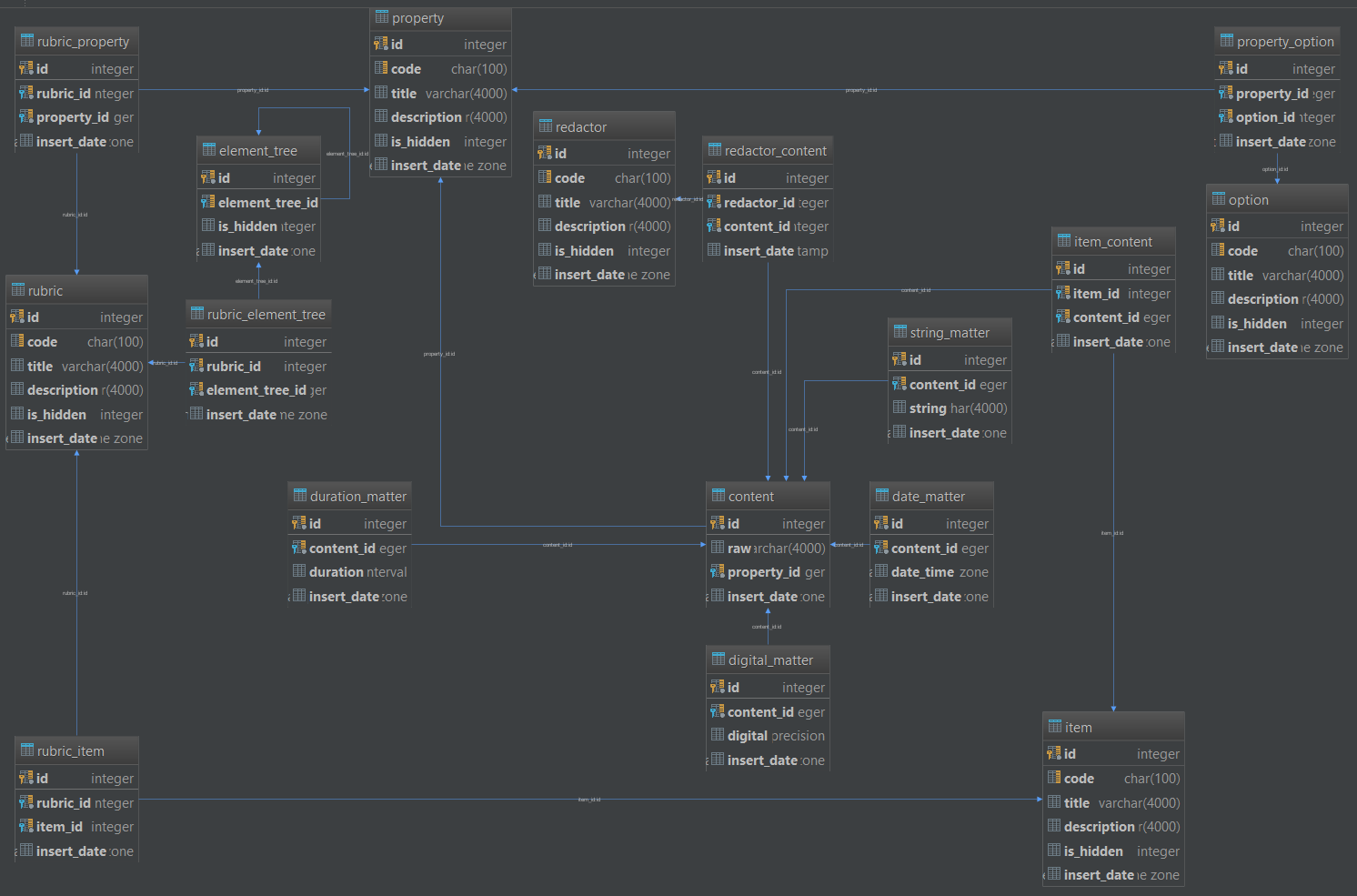
А собирать вот такой вот графовый скворечник:

JOIN в NoSQL базах данных
7 min
В этом сообщении будут рассмотрены способы соединения коллекций в NoSQL базах данных mongodb, arangodb, orientdb и rethinkdb (помимо того, что это NoSQL базы данных, их объединяет еще и наличие бесплатной версии с достаточно лояльной лицензией). В реляционных базах данных аналогичная функциональность реализуется при помощи SQL JOIN. Несмотря на то, что CRUD — операции в NoSQL базах данных очень похожи и различаются только в деталях, например, в одной базе данных для создания объекта используется функция create({… }), в другой — insert({… }), а в третьей — save({… }), — реализация выборки из двух и более коллекций в каждой из баз данных реализована совершенно по-разному. Поэтому будет интересно выполнить на всех базах данных одинаковую выборку. Для всех баз будет рассмотрено получение выборки (связь типа многие-ко многим) для двух таблиц.