В своей работе вы используете MySQL, Postgres или Mongo, а может даже Apache Spark? Хотите знать с чего начинались эти проекты и куда они движутся сейчас? В этой статье я представлю соответствующую визуализацию
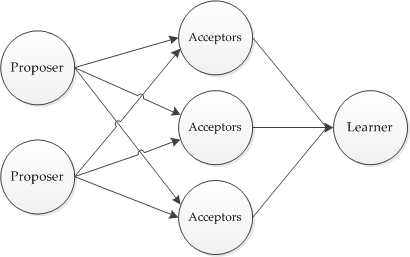
В последнее время в научных публикациях всё чаще упоминается алгоритм достижения консенсуса в распределенных системах под названием Paxos. Среди таких публикаций ряд работ сотрудников Google (Chubby, Megastore, Spanner) ранее уже частично освещенных на хабре, архитектуры систем WANdisco, Ceph и пр. В то же время, сам алгоритм Paxos считается сложным для понимания, хоть и основывается он на элементарных принципах.
В этой статье я постараюсь исправить эту ситуацию и рассказать об этом алгоритме понятным языком, как когда-то это попытался сделать автор алгоритма Лесли Лэмпорт.
Многие из нас сталкивались в своей работе с СУБД. На текущий момент базы данных в том или ином виде окружают нас повсюду, начиная с мобильных телефонов и заканчивая социальными сетями, в число которых входит и любимый нами хабр. Реляционные СУБД являются наиболее распространенными представителями семейства СУБД, и большинство из них являются транзакционными.
В институте нас заставляли заучивать определение ACID и стоящие за ним свойства, но почему-то стороной обходились подробности реализации этой парадигмы. В данной статье я постараюсь частично заполнить этот пробел, рассказав о MVCC, которая используется в таких СУБД как Oracle, Postgres, MySQL, etc. и является весьма простой и наглядной.
В современном мире часто приходится сталкиваться с проблемой рекомендации товаров или услуг пользователям какой-либо информационной системы. В старые времена для формирования рекомендаций обходились сводкой наиболее популярных продуктов: это можно наблюдать и сейчас, открыв тот же Google Play. Но со временем такие рекомендации стали вытесняться таргетированными (целевыми) предложениями: пользователям рекомендуются не просто популярные продукты, а те продукты, которые наверняка понравятся именно им. Не так давно компания Netflix проводила конкурс с призовым фондом в 1 миллион долларов, задачей которого стояло улучшение алгоритма рекомендации фильмов (подробнее). Как же работают подобные алгоритмы?
В данной статье рассматривается алгоритм коллаборативной фильтрации по схожести пользователей, определяемой с использованием косинусной меры, а также его реализация на python.
kNN расшифровывается как k Nearest Neighbor или k Ближайших Соседей — это один из самых простых алгоритмов классификации, также иногда используемый в задачах регрессии. Благодаря своей простоте, он является хорошим примером, с которого можно начать знакомство с областью Machine Learning. В данной статье рассмотрен пример написания кода такого классификатора на python, а также визуализация полученных результатов.


 Многие из нас сталкивались в своей работе с СУБД. На текущий момент базы данных в том или ином виде окружают нас повсюду, начиная с мобильных телефонов и заканчивая социальными сетями, в число которых входит и любимый нами хабр. Реляционные СУБД являются наиболее распространенными представителями семейства СУБД, и большинство из них являются транзакционными.
Многие из нас сталкивались в своей работе с СУБД. На текущий момент базы данных в том или ином виде окружают нас повсюду, начиная с мобильных телефонов и заканчивая социальными сетями, в число которых входит и любимый нами хабр. Реляционные СУБД являются наиболее распространенными представителями семейства СУБД, и большинство из них являются транзакционными.