За последние годы инфраструктура приватных ключей PKI (Public Key Infrastructure) незаметно окружила нас со всех сторон:
- Большинство сайтов в сети Интернет используют HTTPS протокол. Для его работоспособности необходимо получать сертификаты из удостоверяющих центров (Certificate Authority)
- Компании организуют доступ к своей IT инфраструктуре и информационным ресурсам с помощью ключей и сертификатов, которые сотрудники получают из специальных систем.
- Для отправки документов в государственные и коммерческие структуры требуется цифровая подпись, которая реализуется теми же механизмами.
Давайте разберемся как работают системы PKI, т.к. они еще долго будут актуальны для обеспечения аутентификации и безопасной передачи данных. В данной статье рассмотрим теорию и в качестве примера PKI возьмём самую известную в мире реализацию PKI - HTTPS протокол в сети Интернет. В качестве удостоверяющего центра будем использовать бесплатный Let's Encrypt. В следующей статье "Сам себе PKI: Практика на примере OpenSSL и CA Smallstep" перейдем к практике и организуем безопасную передачу данных на основе TLS протокола.
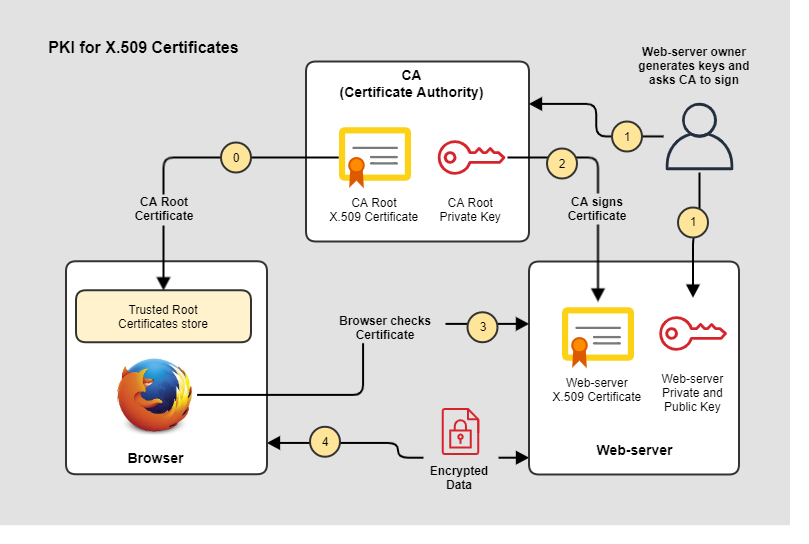
На схеме упрощенная система PKI для организации HTTPS в сети Интернет.