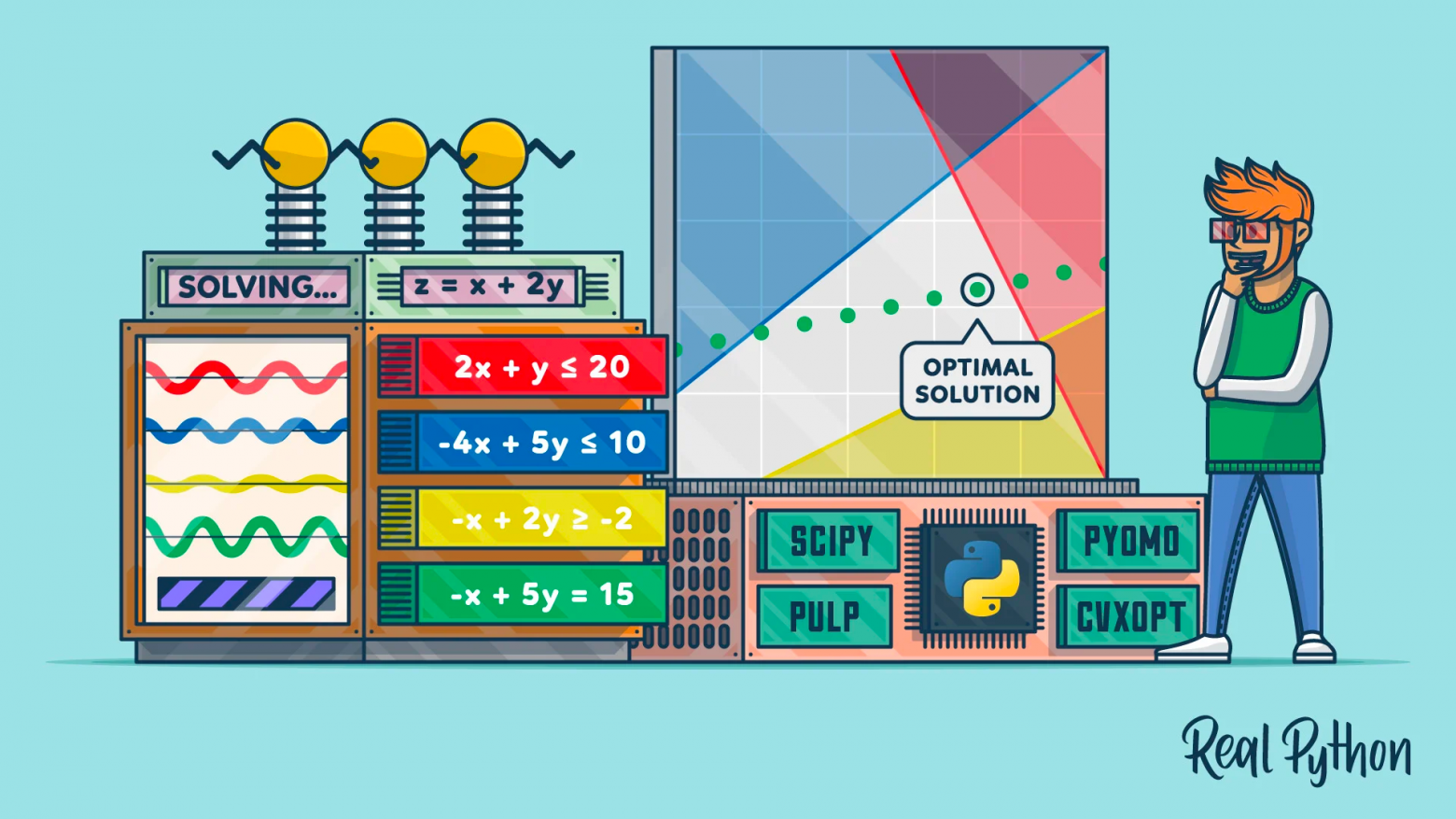
Привет, Habr! На связи отдел аналитики данных X5 Tech.
Сегодня мы поговорим об очень интересном разделе прикладной математики — оптимизации.

аналитика и визуализация данных
Привет, Habr! На связи отдел аналитики данных X5 Tech.
Сегодня мы поговорим об очень интересном разделе прикладной математики — оптимизации.

В настоящее время набирают популярность модели Reinforcement Learning для решения прикладных задач бизнеса. В этой статье мы рассмотрим подмножество этих моделей, а именно многоруких бандитов (multi-armed bandits). Также мы:
- обсудим, какие задачи теоретически могут быть решены с помощью этих моделей;
- рассмотрим некоторые популярные реализации моделей многоруких бандитов;
- опишем симулятор ценообразования, применим эти алгоритмы в нём и сравним их эффективность.

На фоне развития генеративных и больших языковых моделей набирают обороты векторные базы данных. В прошлый раз в блоге beeline cloud мы обсудили, насколько этот тренд устойчив, а также предложили несколько книг для желающих погрузиться в тему. Сегодня же мы собрали компактную подборку открытых СУБД и поисковых движков, способных помочь в разработке систем ИИ. Обсуждаем такие инструменты, как Lantern, LanceDB, CozoDB, ArcadeDB, Dart Vector DB, Marqo и Orama.
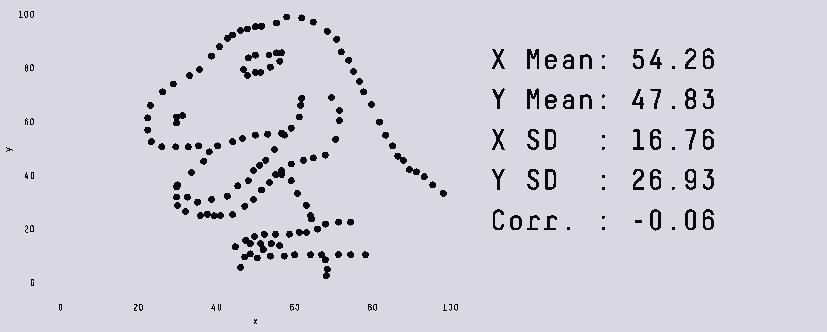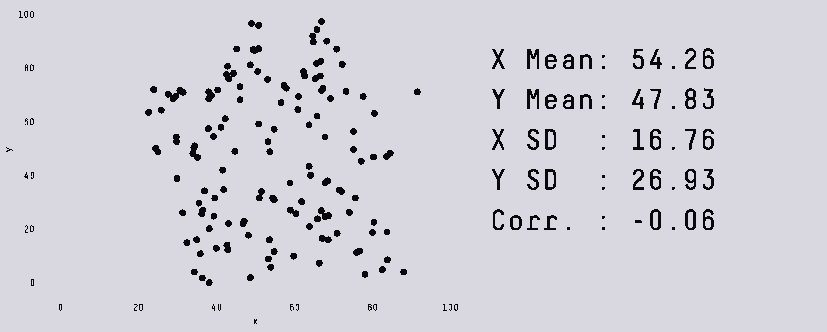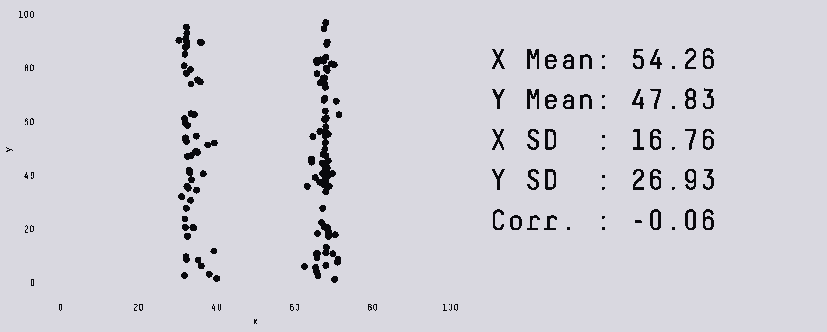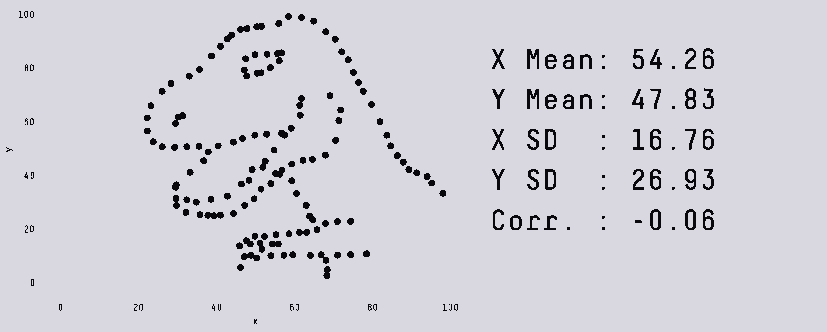
В этой заметке я хочу разобрать несколько «парадоксов» в данных, о которых полезно знать как начинающему аналитику данных, так и любому человеку, кто не хочет быть введенным в заблуждение некорректными статистическими выводами.
За рассматриваемыми примерами не кроется сложной математики помимо базовых свойств выборки (таких, как среднее арифметическое и дисперсия), зато такие кейсы могут встретиться и на собеседовании, и в жизни.
Эта статья появилась по нескольким причинам.
Во-первых, в подавляющем большинстве книг, интернет-ресурсов и уроков по Data Science нюансы, изъяны разных типов нормализации данных и их причины либо не рассматриваются вообще, либо упоминаются лишь мельком и без раскрытия сути.
Во-вторых, имеет место «слепое» использование, например, стандартизации для наборов с большим количеством признаков — “чтобы для всех одинаково”. Особенно у новичков (сам был таким же). На первый взгляд ничего страшного. Но при детальном рассмотрении может выясниться, что какие-то признаки были неосознанно поставлены в привилегированное положение и стали влиять на результат значительно сильнее, чем должны.
И, в-третьих, мне всегда хотелось получить универсальный метод учитывающий проблемные места.

Данная статья открывает цикл, посвященный розничной торговле. Идею использования аналитики в ритейле можно изобразить в виде вот такого маркетингового круга:
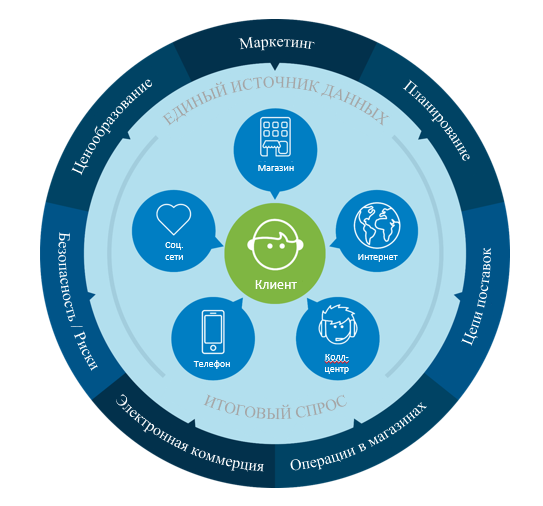
Основная идея, на первый взгляд, бесполезной картинки – показать, что аналитика позволяет предсказать последствия принятия тех или иных бизнес решений, основываясь на последующем изменении покупательского спроса. И чем лучше мы понимаем спрос, агрегируя информацию из разных каналов, тем лучше мы будем предсказывать результат. Короче говоря, картинка идеального мира, и каждый идет к этому миру своим путем.
Сегодня речь пойдет об аналитике ценообразования в офлайн ритейле.
Всем привет! Представьте себе ситуацию: ваша уютная маленькая команда Data Science занимается прогнозированием спроса для пары десятков дарксторов с помощью какого-нибудь коробочного Prophet. И в один прекрасный день к вам приходит бизнес. Бизнес садится, закидывает ногу на ногу, закуривает сигару и говорит:
«Мы хотим максимально автоматизировать закупки. Нам нужно, чтобы вы умели строить прогноз по всем товарам, старым и новым, для всех дарксторов, старых и новых. А их будет много, их будут сотни, тысячи, миллионы. А ещё у нас будет миллион видов скидок и разные типы ценообразования, и ещё куча промо-механик и конкурсов интересных. Мы хотим, чтобы прогноз обязательно адекватно на всё это реагировал». (с) Типичный Бизнес
Хорошо, думаем мы, кажется, что это звучит нетрудно…
С этой задачи начинается моя история о прогнозе спроса в Самокате. Меня зовут Мария Суртаева, я Data Scientist и расскажу о концепции прогноза спроса, его практических задачах и роли градиентного бустинга.

Привет, {{ username }}!
Добро пожаловать в очередную статью про изучение английского.
Постараюсь емко обобщить свой опыт самостоятельного изучении языка от A1 до B2 за 1-2 года. Информация релеванта для технарей 25+ лет, однако подойдет для широкого круга интересующихся.
Мнение автора субъективно. Представленные материалы, инструменты и best practices дадут вам базовое знание языка, однако не смогут подготовить к собеседованию, IELTS/TOEFL, чтению классической литературы и т.п.

«Во всякой вещи скрыт узор, который есть часть Вселенной. В нём есть симметрия, элегантность и красота — качества, которые прежде всего схватывает всякий истинный художник, запечатлевающий мир. Этот узор можно уловить в смене сезонов, в том, как струится по склону песок, в перепутанных ветвях креозотового кустарника, в узоре его листа.
Мы пытаемся скопировать этот узор в нашей жизни и нашем обществе и потому любим ритм, песню, танец, различные радующие и утешающие нас формы. Однако можно разглядеть и опасность, таящуюся в поиске абсолютного совершенства, ибо очевидно, что совершенный узор — неизменен. И, приближаясь к совершенству, всё сущее идёт к смерти» — Дюна (1965)

Привет, Хабр! Легендарная команда прогнозирования промо сети магазинов «Магнит» снова в эфире. Ранее мы успели рассказать о целях и задачах, которые мы решаем: «Магнитная аномалия: как предсказать продажи промо в ритейле», а также поделиться основными трудностями, с которыми приходится сталкиваться в нашем опасном бизнесе: «Божественная комедия», или Девять кругов прогнозирования промо в «Магните».
Сегодня подробнее расскажем о типах и особенностях используемых нами моделей прогнозирования продаж.

Привет, Хабр! На связи команда направления прогнозирования промо в «Магните». В предыдущей статье «Магнитная аномалия: как предсказать продажи промо в ритейле» мы дали читателю общее представление о том, чем занимается наша команда. Теперь поговорим о конкретных сложностях и методах их решения, с которыми нам приходится сталкиваться в работе.
Чтобы лучше разобраться во внутренней кухне, предлагаем читателю вместе прогуляться по нашим «девяти кругам прогнозирования промо спроса».


Всем привет! На связи Никита Губин, менеджер продуктов машинного обучения в СберМаркете. Моя команда занимается внедрением ML-решений в маркетинге. И сегодня хочу рассказать, как нам удалось в 8 раз увеличить ROI одного регулярного промо, которое вы можете увидеть в нашем приложении ежедневно.
Статья будет полезна:
Продактам и менеджерам по маркетингу. Разберем конкретный кейс, эффект от которого мы получаем уже более 6 месяцев. Можно забирать на инсайты и гипотезы 😉
Лидам и инженерам машинного обучения. Расскажу про конкретные алгоритмы при помощи которых получили высокий импакт.
Поехали!
Всем привет!

Вот мы постепенно и дошли до продвинутых методов машинного обучения. Сегодня обсудим, как вообще подступиться к обучению модели, если данных гигабайты или десятки гигабайт. Обсудим приемы, позволяющие это делать: стохастический градиентный спуск (SGD) и хэширование признаков, посмотрим на примеры применения библиотеки Vowpal Wabbit.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).

Привет! На связи Николай Шикунов и Леонид Сидоров из ML-команды СберМаркета. Модель, над которой мы работаем, прогнозирует наличие товаров на полках во всех точках, представленных в нашем приложении, и называется out-of-stock model. В этой статье хотим рассказать, какую проблему бизнеса мы решаем, как эволюционировал наш подход к управлению остатками с 2019 года и к чему мы пришли сейчас.

Продолжаем нырять в тему АБ и разбираться как считают тесты в большинстве продуктовых команд, где нет отдельного АБ-департамента.
Если ты еще не видел, то глянь вот здесь про дизайн тестов, как принять гипотезу от менеджера и привести ее в формат документации.
Примеры будут на R, но если ты питонист, можешь найти эти темы у меня в ТГ, там версия для Python тоже присутствует.
А теперь про сам тест.
Год назад я написал бы о том, что каждый может стать программистом, нужно лишь верить в себя, и всё получится. Два года назад я бы добавил пару строк про нити Вселенной, Закон притяжения и материальность мыслей.
Три года назад я бы стучался в каждую дверь с непрошенными советами, убеждая, что нужно срочно начать учить Java, вставать в 5 утра и ходить в бассейн, потому что это круто, полезно, а первый пункт еще и принесет высокооплачиваемую профессию.
Что я хочу сказать сегодня? Нет никакой гарантии, что все из вас, взявшиеся за изучение ИТ-профессии, в конце концов получат работу. Если ты остановил свой взгляд на этой статье в поисках решения своей проблемы, всё уже не замечательно. В статье расскажу, почему.
Привет, Хабр! На связи отдел аналитики данных X5 Tech.
По мере развития технологий больших данных в сфере Data Science продолжает оформляться всё большее количество направлений, а уже существующие становятся более обособленными. Тем не менее, до сих пор многие с трудом могут ответить на вопрос: чем занимается дата-аналитик. В одной компании в его сферу обязанностей входит построение отчётов для бизнеса, в другой — дизайн и проведение АБ-экспериментов, а в третьей — подготовка витрин данных. Поэтому вопрос "Так кто же такой этот ваш дата-аналитик?" мы слышим часто и хотим об этом поговорить.