Я материалист, и поэтому мне радостно видеть впечатляющие успехи больших языковых моделей как то GPT или PaLM. Тут и осмысленный диалог, и программирование, и сочинение сказок, и написание дипломов, и постановка диагнозов, и попытка jailbreak-а. Bing так вообще угрожает и может демонстрировать влюбленность. Эта радость - она от подтверждения правоты, что мы являемся пусть сложными, но всё таким биологическими машинами, и следовательно мы полностью познаваемы, что трансцендентной души у нас нет, что после смерти ничего не будет, а самосознание является феноменом развитой нервной системы.
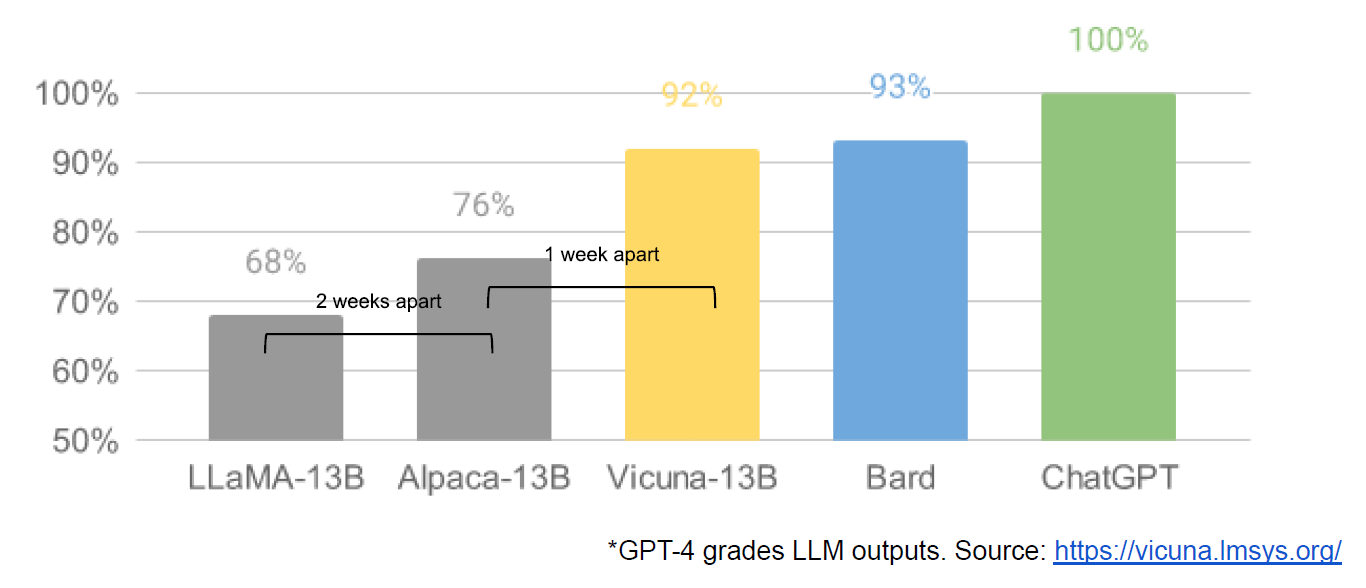
Примечательно то, что публичный прорыв с большими языковыми моделями случился внезапно. Не было какой-то долгой разбежки на протяжении десятков лет (сама GPT модель разрабатывалась с середины 2018, что по меркам истории просто мгновение). ChatGPT выпрыгнул как чёрт из табакерки в конце 2022 и явил собой качественно новое явление. Явление, которое подтверждает второй закон диалектики: количество переходит в качество. Просто возьми много-много текстов, заставь нейросеть на трансформер-архитектуре предсказывать очередное слово и вуа-ля - получи на выходе почти мыслящую сущность. Если угодно, то душа, сознание и характер распределятся у неё где-то на миллиардах весов, как и у каждого из нас в мозгу.
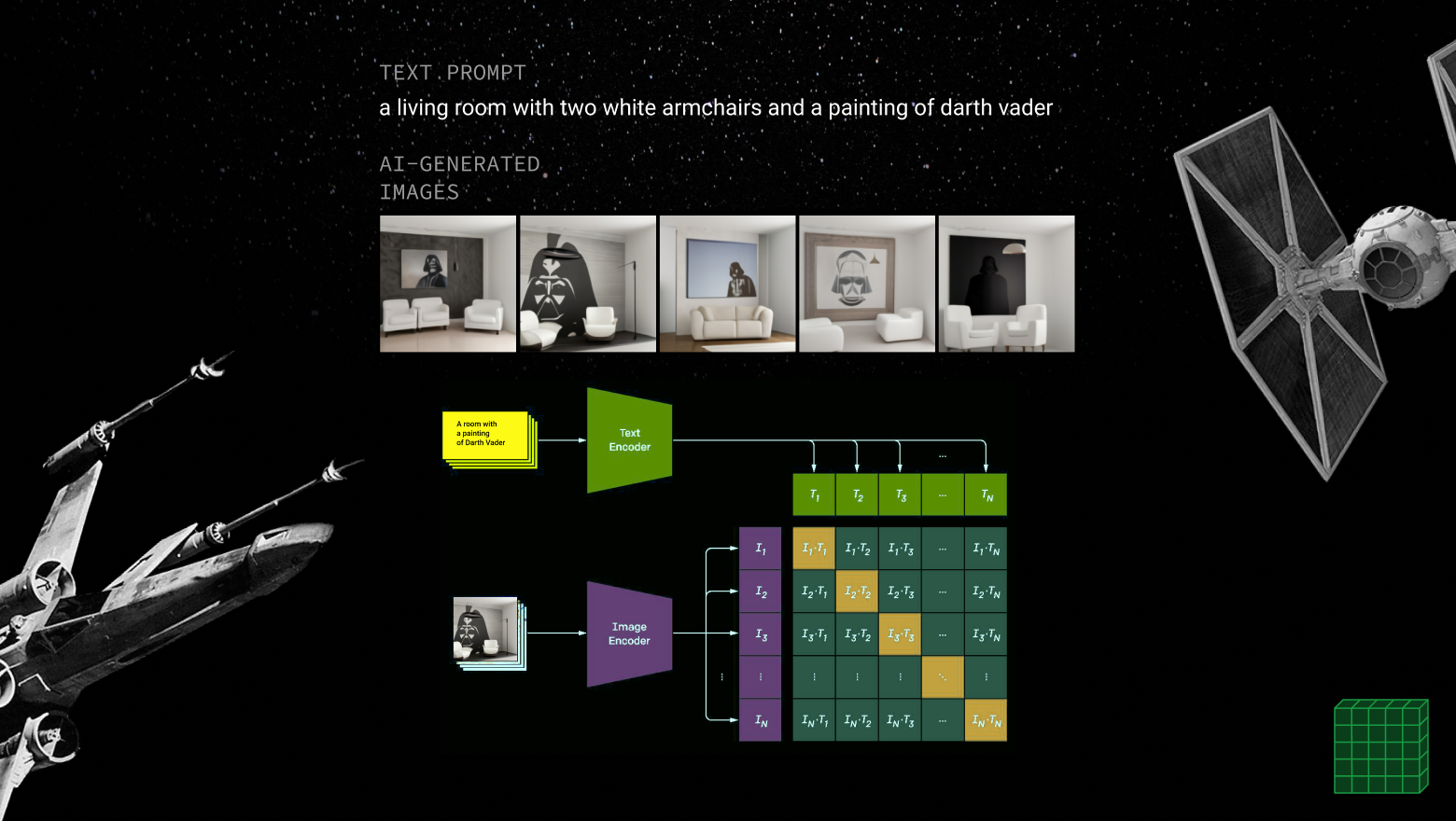
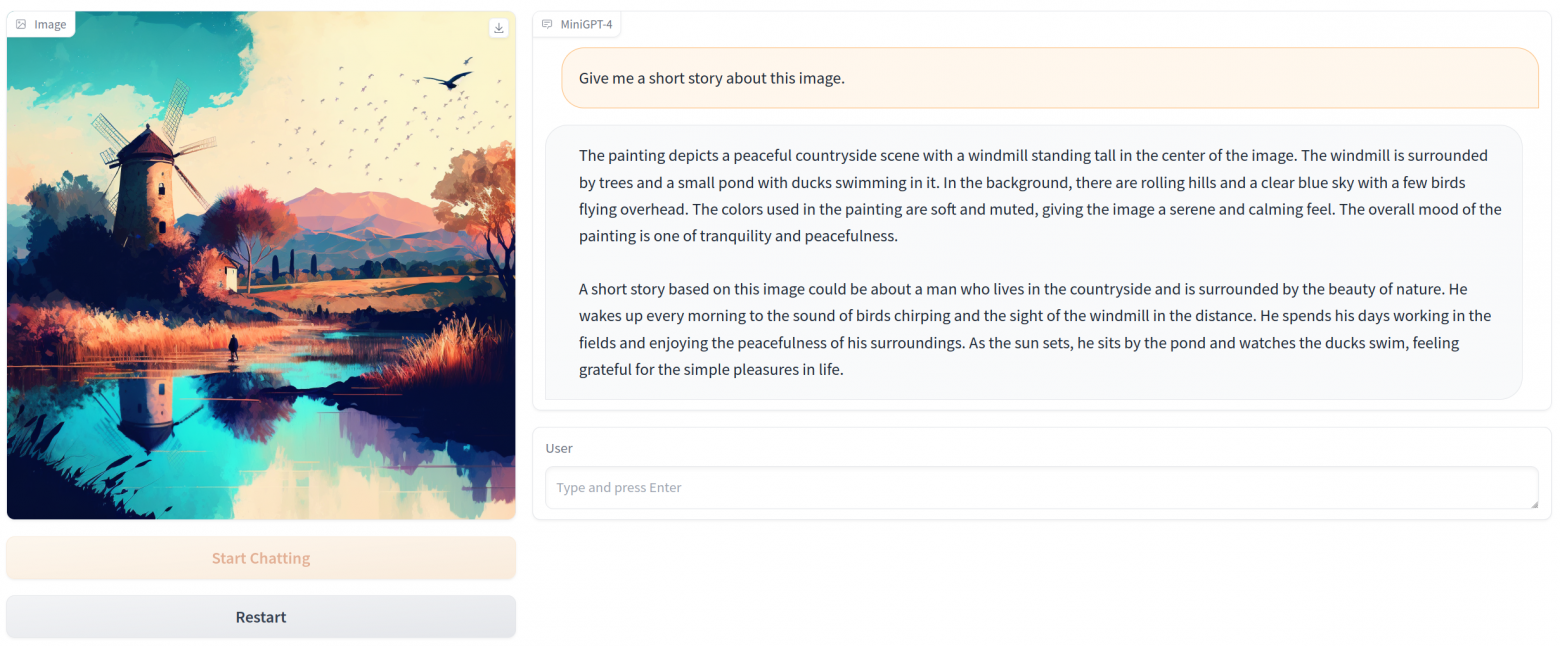
Интересный вопрос - а что такого выучила та же GPT, что позволяет ей вести разумный диалог? За счёт чего магия? При этом помним, что модель не является просто сборищем ответов на заранее известные вопросы. То есть она не похожа на Граммофон из “Сумма технологии” С. Лема, на который записано 100 триллионов ответов. Модель умеет генерировать новое, умеет понимать контекст. По мне, так модель выявила внутреннюю логику и закономерности повествования, следуя которым можно получить любой текст. Эта логика представлена в виде внутренней системы понятий и смыслов, которые активируются в зависимости от текущего диалога. И когда мы что-то спрашиваем у модели, то для неё это может выглядеть так: сюжетная линия №3429643, ситуация №93752, роли №122997 и №88223, действующее лицо №33554, стилистика №7622 и т.д. Соединив и перемножив всё это вместе, получаем небольшой репертуар слов, из которого можно выбрать очередное. Так как всевозможных комбинаций этих сущностей просто космическое, то модель в состоянии генерировать новое и постоянно удивлять нас.