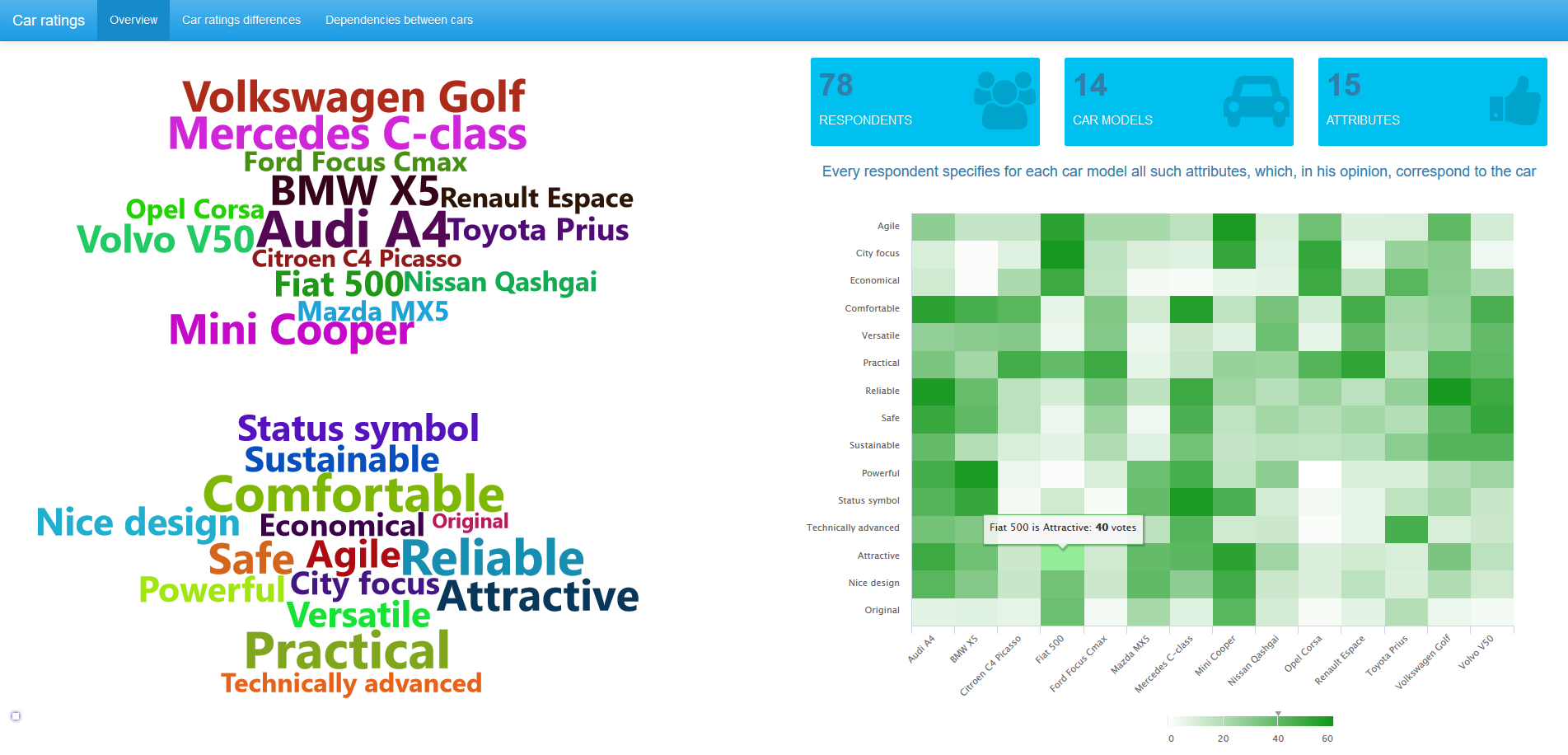
В анкетных маркетинговых исследованиях довольно часто встречаются вопросы, в которых респонденты могут выбрать несколько подходящих вариантов из списка возможных ответов (check all that apply questions). Ответы респондентов на такие вопросы задают переменные с множественным откликом (multiple-response variables). Подходящие статистического методы для работы с multiple-response переменными не являются широко известными. В этой статье мы рассмотрим анализ таких переменных на примере данных об автомобильных рейтингах.
В первой части статьи о выборах 2016 года шла речь о результатах в 225 избирательных округах. В этот раз рассмотрим данные о результатах голосования по участковым избирательным комиссиям (УИК), которых насчитывалось чуть менее 100 тысяч. Этот уровень детализации позволяет увидеть неожиданные явления и удивительные закономерности в результатах голосования.
В сентябре прошли выборы в Госдуму РФ VII созыва. При голосовании вся территория России была разделена на 225 округов. В каких округах каждая из партий получила высокие (или низкие) результаты? Какие значения принимала явка избирателей и как она влияла на результаты партий? Ответы на эти вопросы и ряд других наблюдений представлены в этой публикации.
Лог-линейные модели и их представления в виде марковских сетей позволяют показать структуру взаимосвязей между случайными величинами. Однако полученная визуализация может оказаться трудна для восприятия из-за большого числа равнозначных ребер в графе такой модели. При работе с порядковыми и бинарными переменными гауссовы копулы (Gaussian copula graphical models, сокр. GCGM) дают возможность повысить наглядность и упростить интерпретацию модели. В статье приведен краткий обзор теории и построен пример GCGM для European Social Survey данных.
Внимание, футбол на Хабре! Вот этот пост побудил меня загрузить данные о распределении игроков команд-участниц Евро 2016 по национальным лигам, в которых они выступают. На значимый турнир в национальные сборные вызывают сильнейших на данный момент футболистов. По этой выборке мы можем сравнить между собой европейские футбольные первенства. Какие лиги самые представительные на Евро 2016 и за счет чьих сборных? Под катом графики (трафик) и немного рассуждений. Свисток, игра началась!
На kaggle сейчас проходит конкурс USA Census по поиску интересных фактов в American Community Survey данных за 2013 год. Данные этого анкетирования выложены в свободный доступ, подробности можно найти здесь.
Kaggle выбрал для анализа два направления — персональные сведения (пол, возраст, семейное положение и т.д.) и сведения о домохозяйствах (различные характеристики жилья, доход домохозяйства, налоговые платежи и прочее). Хочу поделиться своими результатами, которые сфокусированы на различиях домохозяйств в зависимости от вида права собственности на их жилье — владение с ограничением (ипотека или заем), владение без ограничений и не владеют (аренда).
Обычно кластеризация подразумевает выделение нескольких групп объектов со схожими характеристиками внутри группы, а между группами — различными. Особенность ко-кластеризации — группирование не только объектов, но и самих характеристик этих объектов. То есть, если данные представлены в виде матрицы, то кластеризация — это перегруппировка строк или столбцов матрицы, а ко-кластеризация — перегруппировка и строк и столбцов матрицы данных.
Как и в предыдущих моих публикациях, примеры использования методов и визуализация решений показаны на данных результатов опросов. Типичная область применения алгоритмов ко-кластеризации — биоинформатика, сегментирование изображений, анализ текстов.
В предыдущей части публикации был рассмотрен метод факторизации неотрицательных матриц в качестве снижения размерности и визуализации таблиц сопряженности. В этой части будет проведен статистический анализ полученных диаграмм с использованием лог-линейных моделей. Напомню, примеры демонстрируются для complex survey данных — стратифицированных, кластеризованных и взвешенных выборок. Это обстоятельство предполагает применение специальных методов оценки и выбора моделей. Для визуализации полученных результатов применяются Марковские сети — удобный инструмент графического представления взаимодействия факторов лог-линейных моделей.
Факторизация неотрицательных матриц (NMF) — это представление матрицы V в виде произведения матриц W и H, в котором все элементы трех матриц неотрицательны. Это разложение используется в различных областях знаний, например, в биологии, компьютерном зрении, рекомендательных системах. В этой публикации пойдет речь о таблицах сопряженности социологических и маркетинговых данных, факторизация которых помогает понять структуру данных этих таблиц.
В предыдущей части статьи был рассмотрен метод поиска ассоциативных правил в данных европейского социального исследования. Эта часть о статистическом анализе полученных правил. Ключевой момент в том, что классические статистические методы, например, критерий согласия хи-квадрат, не имеют основания быть использованными для результатов опроса. Но по каким причинам? И как проверять гипотезы? Об этом пойдет речь в этой публикации.
Поиск ассоциативных правил хорошо известный метод анализа данных. На Хабре уже была публикация с историей вопроса об этом методе и общими определениями. В этой статье пойдет речь об адаптации алгоритма поиска ассоциативных правил в данных полученных опросами респондентов. Результаты работы алгоритма продемонстрированы на данных европейского социального исследования (ESS).
В последнем посте из R-хаба «Визуализация двумерного гауссиана на плоскости» был описан алгоритм построения доверительного эллипса по ковариационной матрице. Алгоритм сопровождался примером и R-скриптом.
Возможно, автору поста о «Визуализации гауссианы» mephistopheies и читателям R-хаба будет полезной следующая информация. В репозитории R есть пакет ellipse. Этот пакет содержит различные процедуры для построения эллипсов доверительных областей.