Привет всем. Продолжу о Фантоме. Для понимания полезно прочесть
статью про персистентную оперативку, а так же
общую статью про Фантом на Открытых Системах. Но можно и так.
Итак, мы имеем ОС (или просто среду, не важно), которая обеспечивает прикладным программам персистентную оперативную память, и вообще персистентную «жизнь». Программы живут в общем адресном пространстве с управляемыми (managed) пойнтерами, объектной байткод-машиной, не замечают рестарта ОС и, в целом, счастливы.
Очевидно, что такой среде нужна сборка мусора. Но — какая?
Есть несколько проблем, навязанных спецификой.
Во-первых, теоретически, объём виртуальной памяти в такой среде огромен — терабайты, всё содержимое диска. Ведь мы отображаем в память всё и всегда.
Во-вторых, нас категорически не устраивают stop the world алгоритмы. Если для обычного процесса остановка в полсекундны может быть приемлема, то для виртуальной памяти, которая, большей частью, на диске, это будут уже полчаса, а то как бы не полсуток!
Наконец, если считать, что полная сборка мусора составляет полсуток, нас, наверное, это не устроит — было бы здорово иметь какой-то быстрый процесс сбора мусора, хотя бы и не полностью честный, пусть он часть мусора теряет, но если удаётся быстро вернуть 90% — уже хорошо.
Тут нужна оговорка. Вообще говоря, в системе, которая располагает парой терабайт виртуальной памяти, это не так уж критично — даже если не делать освобождение памяти полсуток, возможно, не так много и набежит — ну, например, истратится 2-3, ну 5 гигабайт, ну даже и 50 гигабайт — не жалко, диск большой.
Но, скорее всего, это приведёт к большой фрагментации памяти — множество локальных переменных окажутся раскиданы по многим далеко расположенным страницам, при этом высока вероятность того, что небольшие вкрапления актуальной информации будут перемежены с тоннами неактуального мусора, что сильно повысит нагрузку на оперативную память.
Ок, итого у нас две задачи.

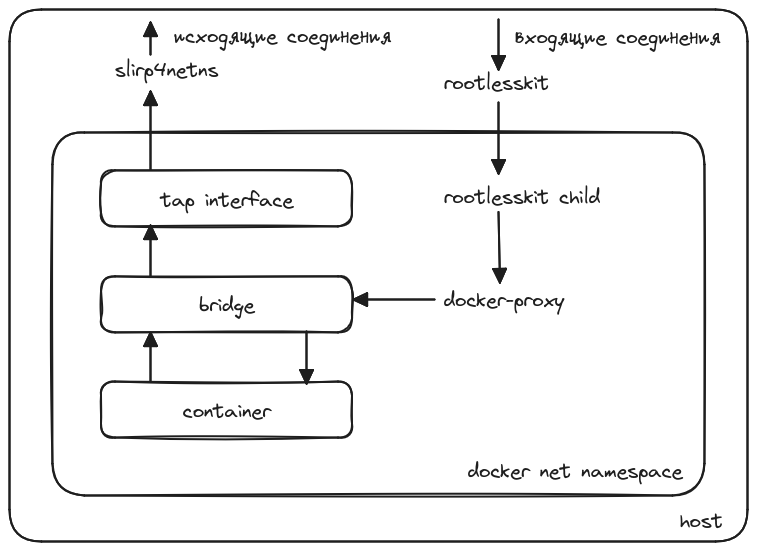

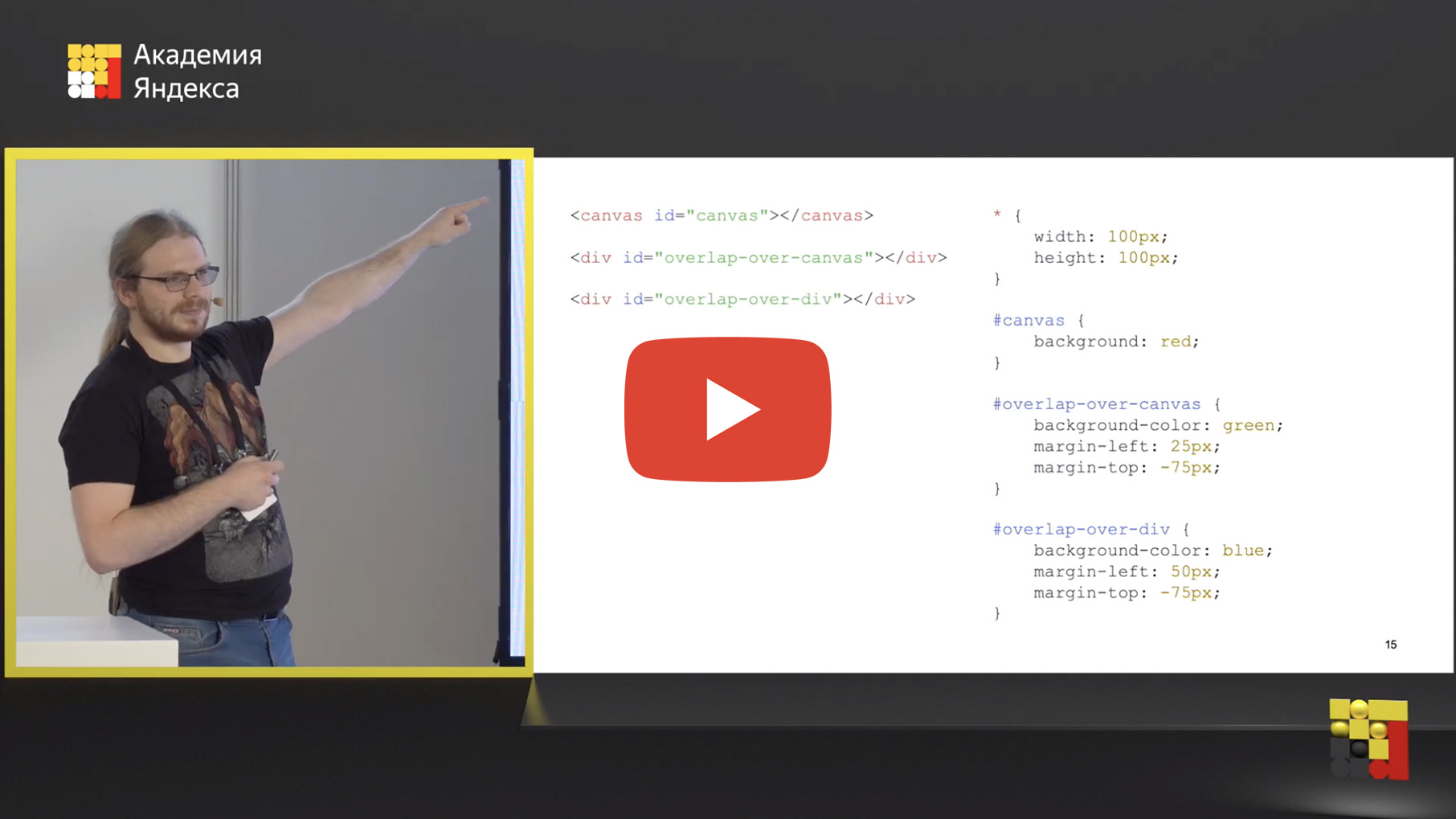
 Я люблю автоматизировать процесс и писать собственные велосипеды для изучения того или иного материала. Моей новой целью стал DHCP-сервер, который будет выдавать адрес в маленьких сетях, чтобы можно было производить первоначальную настройку оборудования.
Я люблю автоматизировать процесс и писать собственные велосипеды для изучения того или иного материала. Моей новой целью стал DHCP-сервер, который будет выдавать адрес в маленьких сетях, чтобы можно было производить первоначальную настройку оборудования.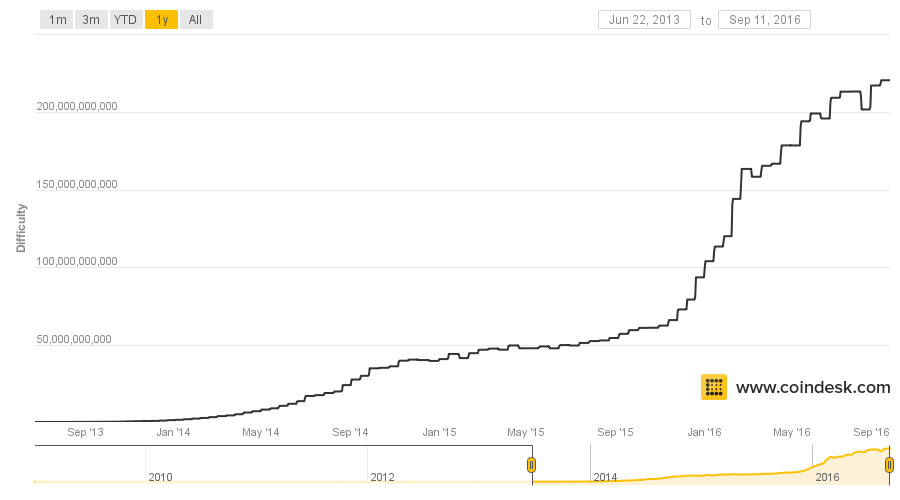
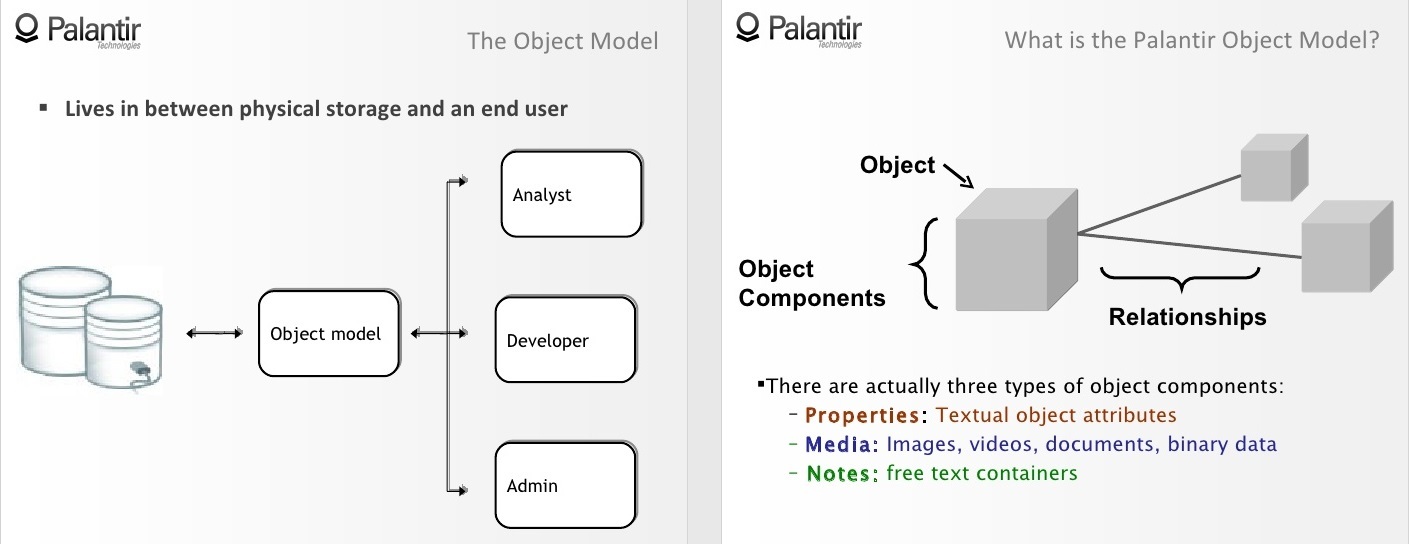







 Привет! Я воплощаю интересные идеи на python и рассказываю о том, что из этого вышло. В прошлый
Привет! Я воплощаю интересные идеи на python и рассказываю о том, что из этого вышло. В прошлый