Здравствуйте, меня зовут Дмитрий Карловский и я… многозадачный человек. В смысле у меня много задач и мало времени, чтобы их все уже, наконец, закончить. Отчасти это и к лучшему — всегда есть чем заняться. С другой стороны — пока ты разрываешься между проектами, мир катится куда-то не туда и некому забраться на броневик и призвать толпу остановиться и немного подумать. А вопрос-то серьёзный — долгое время мир JS был погружён в ад обратных звонков и с ними не только не боролись — их боготворили. Потом он чуть менее чем полностью погряз в обещаниях. Сейчас к ним с разных сторон усиленно вставляют подпорки разной степени кривизны. А света в конце тоннеля всё не видать. Но обо всём по порядку...
Теория многозадачности
Сперва определимся с терминами. В процессе работы, приложение выполняет различные задачи. Например, "скачать файл с удалённого сервера" или "обработать запрос пользователя".
Не редки ситуации, когда для выполнения одной задачи требуется выполнение дополнительных задач — "подзадач". Например, для обработки запроса пользователя, необходимо скачать файл с удалённого сервера.
Запустить подзадачу мы можем синхронно, и тогда текущая задача заблокируется в ожидании завершения подзадачи. А можем запустить асинхронно, и тогда текущая задача продолжит своё выполнение не дожидаясь завершения подзадачи.
Тем не менее, обычно для завершения выполнения задачи, пусть и не сразу, но требуется и завершение выполнения подзадачи с последующей обработкой её результатов. Блокировку одной задачи в ожидании сигналов от другой будем называть "синхронизацией". В общем случае, синхронизация одних и тех же задач может происходить и множество раз, по самой различной логике, но в дальнейшем мы будем рассматривать лишь простейший и самый распространённый вариант — синхронизацию по завершению подзадачи.


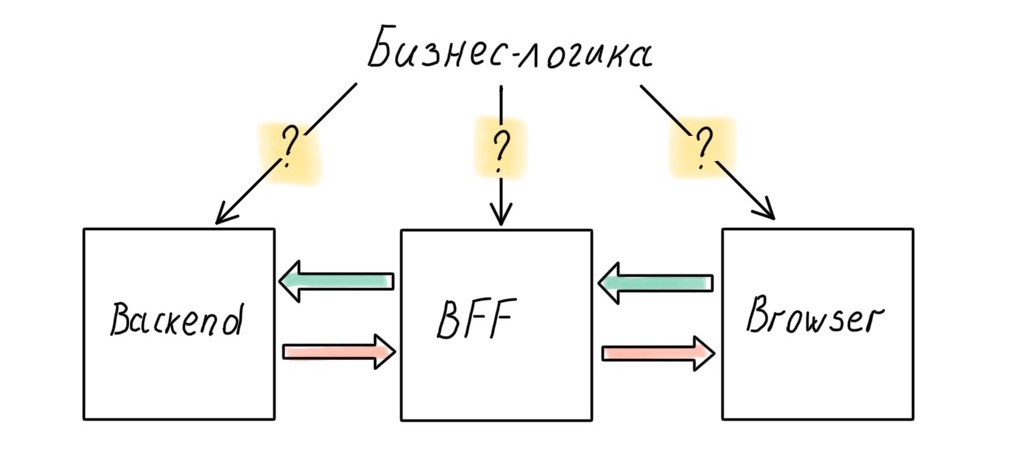
 "
" 




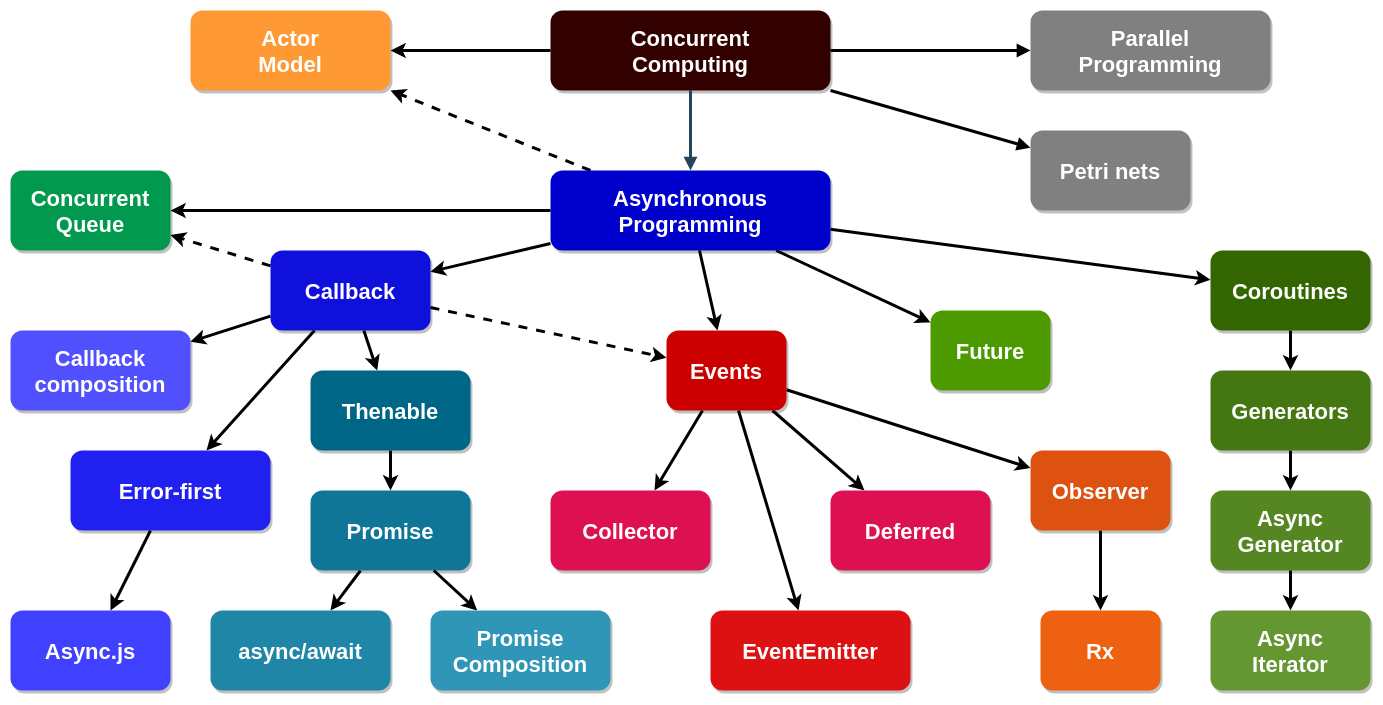



 Товарищи инженеры, докладываю вам об успехах в подготовке научно-технических кадров в области программной инженерии на
Товарищи инженеры, докладываю вам об успехах в подготовке научно-технических кадров в области программной инженерии на