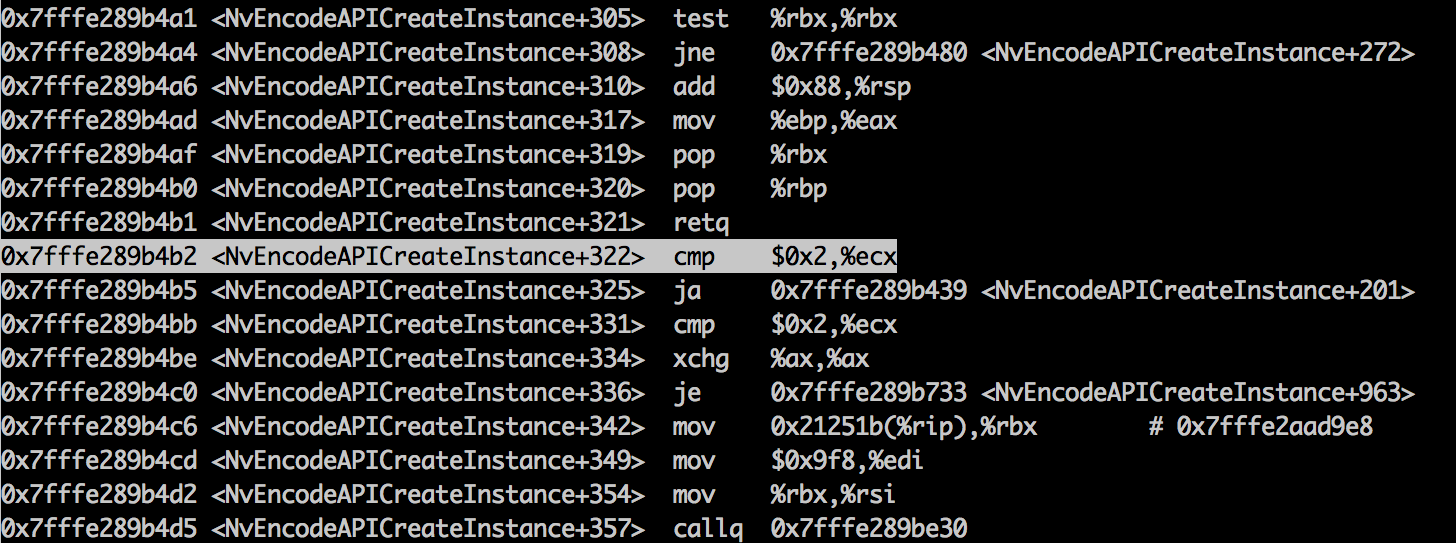
Про монаду ходит множество мемов и легенд. Говорят, что каждый уважающий себя программист в ходе своего функционального возмужания должен написать хотя бы один туториал про монаду — недаром на сайте языка Haskell даже ведётся
специальный таймлайн для всех отважных попыток приручить этого таинственного зверя. Бывалые разработчики поговаривают также и о
проклятии монад — мол, каждый, кто постигнет суть этого чудовища, начисто теряет способность кому-либо увиденное объяснить. Одни для этого
вооружаются теорией категорий, другие
надевают космические костюмы, но, видимо, единого способа подобраться к монадам не существует, иначе каждый программист не выдумывал бы свой собственный.
Действительно, сама концепция монады неинтуитивна, ведь лежит она на таких уровнях абстракции, до которых интуиция просто не достаёт без должной тренировки и теоретической подготовки. Но так ли это важно, и нет ли другого пути? Тем более, что эти таинственные монады уже окружают многих ничего не подозревающих программистов, даже тех, кто пишет на языках, никогда не считавшихся «функциональными». Действительно, если приглядеться, то можно обнаружить, что они уже здесь, в языке Java, под самым нашим носом, хотя в документации по стандартной библиотеке слово «монада» мы едва ли найдём.
Именно поэтому важно если не постичь глубинную суть этого паттерна, то хотя бы научиться распознавать примеры использования монады в уже существующих, окружающих нас API. Конкретный пример всегда даёт больше, чем тысяча абстракций или сравнений. Именно такому подходу и посвящена эта статья. В ней не будет теории категорий, да и вообще какой-либо теории. Не будет оторванных от кода сравнений с объектами реального мира. Я просто приведу несколько примеров того, как монады уже используются в знакомом нам API, и постараюсь дать читателям возможность уловить основные признаки этого паттерна. В основном в статье пойдёт речь о Java, и ближе к концу, чтобы вырваться из мира legacy-ограничений, мы немного коснёмся Scala.







 Несмотря на то, что могут быть (и есть) и более фундаментальные определения этого понятия, тем не менее, Виртуальные Миры (ВМ) всегда придерживаются определенных условий, отличающих их от других родственных виртуальных пространств. Самыми основными будут следующие:
Несмотря на то, что могут быть (и есть) и более фундаментальные определения этого понятия, тем не менее, Виртуальные Миры (ВМ) всегда придерживаются определенных условий, отличающих их от других родственных виртуальных пространств. Самыми основными будут следующие: