
TL;DR: закинул 10к фотографий панелек в Stylegan2 и запустил на Google Colab.
Подробнее под катом

Компьютерный лингвист
TL;DR: закинул 10к фотографий панелек в Stylegan2 и запустил на Google Colab.
Подробнее под катом






Около месяца назад Google сервис Colaboratory, предоставляющий доступ к Jupyter ноутбукам, включил возможность бесплатно использовать GPU Tesla K80 с 13 Гб видеопамяти на борту. Если до сих пор единственным препятствием для погружения в мир нейросетей могло быть отсутствие доступа к GPU, теперь Вы можете смело сказать, “Держись Deep Learning, я иду!”.
Я попробовал использовать Colaboratory для работы над kaggle задачами. Мне больше всего не хватало возможности удобно сохранять натренированные tensorflow модели и использовать tensorboard. В данном посте, я хочу поделиться опытом и рассказать, как эти возможности добавить в colab. А напоследок покажу, как можно получить доступ к контейнеру по ssh и пользоваться привычными удобными инструментами bash, screen, rsync.
Недавно я натолкнулся на вопрос на Stackoverflow, как восстанавливать исходные слова из сокращений: например, из wtrbtl получать water bottle, а из bsktball — basketball. В вопросе было дополнительное усложнение: полного словаря всех возможных исходных слов нет, т.е. алгоритм должен быть в состоянии придумывать новые слова.
Вопрос меня заинтриговал, и я полез разбираться, какие алгоритмы и математика лежат в основе современных опечаточников (spell-checkers). Оказалось, что хороший опечаточник можно собрать из n-граммной языковой модели, модели вероятности искажений слов, и жадного алгоритма поиска по лучу (beam search). Вся конструкция вместе называется модель зашумлённого канала (noisy channel).
Вооружившись этими знаниями и Питоном, я за вечер создал с нуля модельку, способную, обучившись на тексте "Властелина колец" (!), распознавать сокращения вполне современных спортивных терминов.
 Йо-хо-хо, хабровчане!
Йо-хо-хо, хабровчане!
— Eh bien, mon prince. Gênes et Lucques ne sont plus que des apanages, des поместья, de la famille Buonaparte. Non, je vous préviens que si vous ne me dites pas que nous avons la guerre, si vous vous permettez encore de pallier toutes les infamies, toutes les atrocités de cet Antichrist (ma parole, j'y crois) — je ne vous connais plus, vous n'êtes plus mon ami, vous n'êtes plus мой верный раб, comme vous dites 1. Ну, здравствуйте, здравствуйте. Je vois que je vous fais peur 2, садитесь и рассказывайте.
Недавно на хабре наткнулся на эту статью https://habrahabr.ru/post/342738/. И захотелось написать про word embeddings, python, gensim и word2vec. В этой части я постараюсь рассказать о обучении базовой модели w2v.
Итак, приступаем.
utf-8.В свободное и не свободное время[1] я развиваю несколько своих проектов на github, а также, по мере сил, участвую в жизни интересных для меня, как программиста, проектах.
Недавно один из коллег попросил консультацию: как выложить разработанную им библиотеку на github. Библиотека никак не связана с бизнес-логикой приложения компании, по сути это адаптер к некоему API, реализующему определённый стандарт. Помогая ему, я понял что вещи, интуитивно понятные и давно очевидные для меня, в этой области, совершенно неизвестны человеку делающему это впервые и далёкому от Open Source.
Я провел небольшое исследование и обнаружил что большинство публикаций по этой теме на habrahabr освещают тему участия (contributing), либо просто мотивируют каким-нибудь образом примкнуть к Open Source, но не дают исчерпывающей инструкции как правильно оформить свой проект. В целом в рунете, если верить Яндекс, тема освещена со стороны мотивации, этикета контрибуции и основ пользования github. Но не с точки зрения конкретных шагов, которые следует предпринять.
Так что из себя представляет стильный, модный, молодёжный Open Source проект в 201* году?
Доброго дня! Мы продолжаем наш цикл статей открытого курса по машинному обучению и сегодня поговорим о временных рядах.
 Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).

Продолжаем публикацию наших образовательных материалов. Этот курс посвящен изучению основ языка Go. На примере простой текстовой игры будут рассмотрены все основные задачи, с которыми сталкивается разработчик современных веб-приложений в крупных проектах, с реализацией их на Go. Курс не ставит задачи научить программированию с нуля, для обучения будут необходимы базовые навыки программирования.
Список лекций:
В этом посте речь пойдет о том, как я восстанавливал демографические данные для регионов Дании, где после реформы территориального устройства 2007 года официальной гармонизации данных не проводилось. Это лишь небольшая часть гармонизации евростатовских данных, которую я выполнил в рамках своего phd проекта. Пост сперва опубликован в моем англоязычном блоге и в блоге Demotrends. Думаю, что он может быть интересен далеко не только демографам.
NUTS расшифровывается как Nomenclature of Territorial Units For Statistics. Это стандартизированная система административно-территориального деления, принятая странами Евросоюза. История вопроса уходит в 1970-е, когда родилась идея сделать регионы различных стран Европы сопоставимыми. В более или менее законченном и широко употребимом виде система появилась лишь на рубеже веков. Существуют три основных уровня NUTS (см. рис. 1), и наиболее распространенным в региональном анализе оказывается NUTS-2.
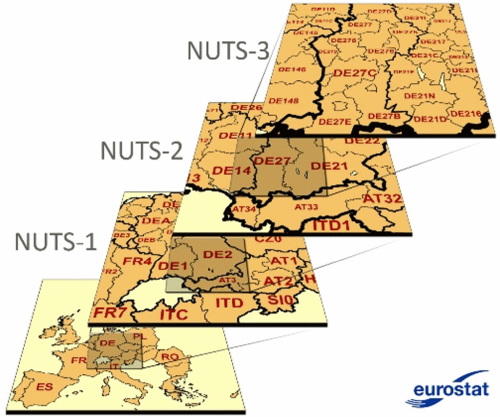
Рисунок 1. Иллюстрация принципа выделения регионов NUTS различного иерархического уровня
 Прогнозирование временных рядов — это достаточно популярная аналитическая задача. Прогнозы используются, например, для понимания, сколько серверов понадобится online-сервису через год, каков будет спрос на каждый товар в гипермаркете, или для постановки целей и оценки работы команды (для этого можно построить baseline прогноз и сравнить фактическое значение с прогнозируемым).
Прогнозирование временных рядов — это достаточно популярная аналитическая задача. Прогнозы используются, например, для понимания, сколько серверов понадобится online-сервису через год, каков будет спрос на каждый товар в гипермаркете, или для постановки целей и оценки работы команды (для этого можно построить baseline прогноз и сравнить фактическое значение с прогнозируемым).
Существует большое количество различных подходов для прогнозирования временных рядов, такие как ARIMA, ARCH, регрессионные модели, нейронные сети и т.д.
Сегодня же мы познакомимся с библиотекой для прогнозирования временных рядов Facebook Prophet (в переводе с английского, "пророк", выпущена в open-source 23-го февраля 2017 года), а также попробуем в жизненной задаче – прогнозировании числа постов на Хабрехабре.
Этот пост написан под впечатлением от вот этого отличного поста с Хабра, в котором автор наглядно, при помощи двумерных моделек, которые рисует его программа, объясняет как работает Специальная Теория Относительности.
Я работаю в IT, а по образованию – физик-теоретик. Уже долгое время увлекаюсь популяризацией науки, и теоретической физики в частности. Постараюсь аналогично вышеупомянутому посту о специальной теории относительности объяснить на специально подготовленном примере как работает квантовая механика.
Модель, которую я рассматриваю – отнюдь не нова. Более полугода назад Chris Cantwell разместил на YouTube анонс новой настольной игры: квантовых шахмат (многим, возможно, известно об этом из вот этого вирусного ролика).
Недавно игра вышла в Steam, она стоит 249 руб. Есть ещё другая реализация – бесплатное приложение для iOS (не знаю, есть ли оно в Google Play). Однако в процессе игр с друзьями я экспериментально выяснил, что она неправильная с точки зрения квантовой механики. Такую реализацию скорее можно назвать статистическими шахматами, а не квантовыми.
Поэтому я решил написать свою реализацию, с запутанностью и суперпозициями. В своей реализации я постарался исправить те недостатки, которые на мой взгляд присутствуют в версии на Steam (например, у меня пешки тоже могут ходить квантовыми ходами, как и все остальные фигуры). Про приложение для iOS и так всё понятно: любая реализация квантовых шахмат должна быть по-настоящему квантовой, т.е. не только быть вероятностной, но поддерживать такие эффекты квантовой механики как интерференция, запутанность, etc.
{kind=link}