
 Когда возникает идея создать что-нибудь полезное, обычно очень хочется сделать прототип (или версию 1.0) как можно скорее. Для кого-то, видеть быстрый результат — это хорошая мотивация, чтобы развивать идею дальше; для других — главное «начать», всем известная истина, что доделывать/переделывать готовое намного легче, чем писать с нуля. Итак, в процессе очередного чаепития и обсуждения финансовых рынков, у нас появилась идея создания легкого сервиса для обмена идей и новостей, а также определения текущей ситуации на фынансовых рынках (т.н. тренды) — ведь зная тренды, можно более эффективно торговать.
Когда возникает идея создать что-нибудь полезное, обычно очень хочется сделать прототип (или версию 1.0) как можно скорее. Для кого-то, видеть быстрый результат — это хорошая мотивация, чтобы развивать идею дальше; для других — главное «начать», всем известная истина, что доделывать/переделывать готовое намного легче, чем писать с нуля. Итак, в процессе очередного чаепития и обсуждения финансовых рынков, у нас появилась идея создания легкого сервиса для обмена идей и новостей, а также определения текущей ситуации на фынансовых рынках (т.н. тренды) — ведь зная тренды, можно более эффективно торговать.В требованиях были: веб сервис, мобильная версия (желательно app), легкая коллективная админ-часть, и простой интерфейс.
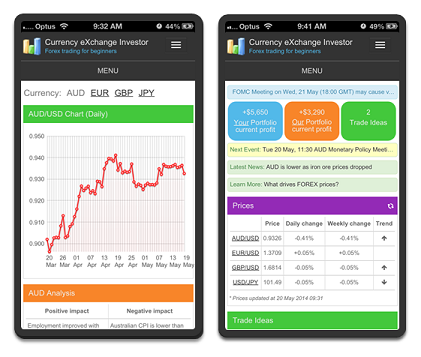
Как у нас получилось мега-быстро «слепить» одновременно и веб и мобильную версию приложения CxInvestor и пойдет речь в этой статье.
Разработка
Первый вопрос, который нужно было решить — на чем писать сервер.



 Довольно давно являюсь обитателем Хабра, но так и не доводилось читать статьи на тему многомерных кубов, OLAP и MDX, хотя тема очень интересная и с каждым днем становится все более актуальной.
Довольно давно являюсь обитателем Хабра, но так и не доводилось читать статьи на тему многомерных кубов, OLAP и MDX, хотя тема очень интересная и с каждым днем становится все более актуальной.