

Одним из популярных оркестратором задач является Apache Airflow. Он, как и все инструменты, имеет свои преимущества и недостатки, о которых пойдет речь в данной статье.
Одним из популярных оркестратором задач является Apache Airflow. Он, как и все инструменты, имеет свои преимущества и недостатки, о которых пойдет речь в данной статье.

Год назад я планировал выпустить серию статей по мотивам бесед с моими коллегами, но дальше одной статьи не пошло, хотя материала накопилось достаточно. Большинство моих товарищей остались на прошлых местах работ и считаю необходимым в знак уважения перед этими неординарными и талантливыми личностями продолжить свои рассказы охотника до талантов.
Сегодня — это руководитель и senior fullstack Марк Локшин. В этой беседе мы обсуждаем о заходе в тему разработки собственного инструмента Business Intelligence. Тема недвусмысленно намекает на то, что данная тема уже не раз была описана на соответствующих ресурсах, а российский рынок даже после ухода с него западных вендоров обладает собственным набором вполне зрелых и рабочих решений.
Собственно, откуда у нас появилась такая задача? Конечно же от заказчиков. А заказчики у нас чаще специфические: государственные и около организации, администрации субъектов регионов. У этих «ребят» чаще всего основная задача показать большому начальнику на совещании красивый график и отчитаться, как же все классно поработали, у особенных из этих заказчиков предъявлены жесткие требования к инструментам разработки.
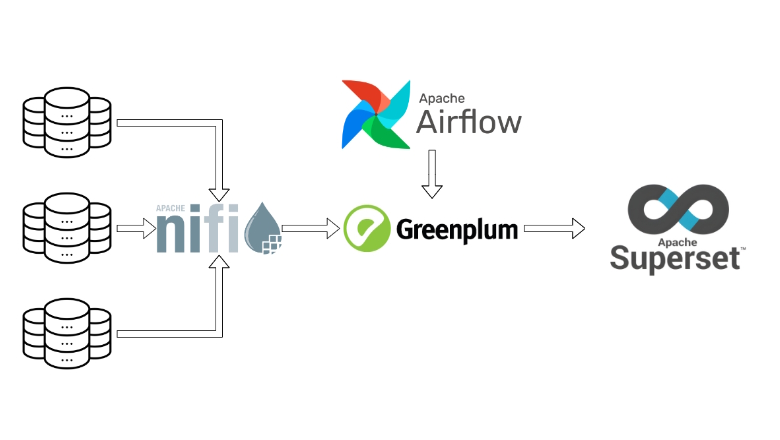
В статье расскажу о практических аспектах использования Apache NiFi, опишу преимущества и проблемы, с которыми я столкнулся.
Для наглядности собрал "песочницу" в контейнере Docker, в которой представлены упрощенные примеры пайплайнов, аналогичные тем, которые были использованы в реальном проекте.

Привет, Хабр!
Apache Ignite - это высокопроизводительная, распределённая in-memory платформа, которая предназначена для хранения и обработки больших объёмов данных с ультранизкой задержкой. Основная фича Ignite заключается в его способности обеспечивать молниеносный доступ к данным, распределённым по горизонтально масштабируемому кластеру.

Сегодня в статье разберем, как Kafka обрабатывает оффсеты сообщений и какие существуют стратегии их сохранения и обновления.
Оффсет в Kafka — это числовой идентификатор, который указывает позицию каждого сообщения внутри партиции топика. Оффсеты представляют собой порядковые номера, начинаемые с нуля, и уникальны в рамках каждой партиции, но не между разными партициями. Т.е сообщение с оффсетом 5 в партиции 1 и сообщение с оффсетом 5 в партиции 2 — это разные сообщения.
Apache Kafka является мощным инструментом для обработки и передачи потоковых данных в реальном времени, который находит широкое применение в различных индустриях для обработки огромных объемов данных с низкой задержкой. В центре этой платформы лежит способность эффективно распределять данные между множеством производителей (producers) и потребителей (consumers), при этом поддерживая высокую пропускную способность и масштабируемость. Однако, с увеличением количества и разнообразия данных, возникает необходимость в управлении структурами этих данных, что обеспечивает Schema Registry. Этот компонент является критически важным для поддержания согласованности данных в Kafka, поскольку он управляет схемами сообщений и обеспечивает совместимость между различными версиями схем, что позволяет системам бесперебойно обмениваться данными даже при изменении структуры сообщений.

Привет, Хабр! Меня зовут Сергей Евсеев, сегодня я расскажу, как в Apache NiFi настраивается ETL-пайплайн на задаче с JSON’ами. В этом мне помогут инструменты Jolt и Avro. Пост пригодится новичкам и тем, кто выбирает инструмент для решения схожей задачи.
Что делает наша команда
Команда работает с данными по рекрутингу — с любой аналитикой, которая необходима персоналу подбора сотрудников. У нас есть различные внешние или внутренние источники, из которых с помощью NiFi или Apache Spark мы забираем данные и складируем к себе в хранилище (по умолчанию Hive, но есть еще PostgreSQL и ClickHouse). Этими же инструментами мы можем брать данные из хранилищ, создавать витрины и складывать обратно, предоставлять данные внутренним клиентам или делать дашборды и давать визуализацию.
Описание задачи
У нас есть внешний сервис, на котором рекрутеры работают с подбором. Сервис может отдавать данные через свою API, а мы эти данные можем загружать и складировать в хранилище. После загрузки у нас появляется возможность отдавать данные другим командам или работать с ними самим. Итак, пришла задача — нужно загрузить через API наши данные. Дали документацию для загрузки, поехали. Идем в NiFi, создаем пайплайн для запросов к API, их трансформации и складывания в Hive. Пайплайн начинает падать, приходится посидеть, почитать документацию. Чего-то не хватает, JSON-ы идут не те, возникают сложности, которые нужно разобрать и решить.
Ответы приходят в формате JSON. Документации достаточно для начала загрузки, но для полного понимания структуры и содержимого ответа — маловато.
Мы решили просто загружать все подряд — на месте разберемся, что нам нужно и как мы это будем грузить, потом пойдем к источникам с конкретными вопросами. Так как каждый метод API отдает свой класс данных в виде JSON, в котором содержится массив объектов этого класса, нужно построить много таких пайплайнов с обработкой разного типа JSON’ов. Еще одна сложность — объекты внутри одного и того же класса могут отличаться по набору полей и их содержимому. Это зависит от того, как, например, сотрудники подбора заполнят информацию о вакансии на этом сервисе. Этот API работает без версий, поэтому в случае добавления новых полей информацию о них мы получим только либо из данных, либо в процессе коммуникации.

Всем привет! Меня зовут Амир, я Data Engineer в компании «ДЮК Технологии». Расскажу, как мы спроектировали и реализовали на Apache Druid хранилище разрозненных табличных данных.
В статье опишу, почему для реализации проекта мы выбрали именно Apache Druid, с какими особенностями реализации столкнулись, как сравнивали методы реализации датасорсов.

Привет, Хабр! Доводилось ли вам тратить долгие бесплодные часы в попытке настроить коннекторы Kafka Connect, чтобы добиться адекватного потока данных? Мне, к сожалению, доводилось. Представляю вашему вниманию перевод статьи "How to Tune Kafka Connect Source Connectors to Optimize Throughput" автора Catalin Pop. Это прекрасное руководство от Confluent, где подробно и с примером описывается, как настроить Source коннекторы.

Всем привет!
В этой статье возьмем за основу пару таблиц и пройдемся по планам запросов по нарастающей: от обычного селекта до джойнов, оконок и репартиционирования. Посмотрим, чем отличаются виды планов друг от друга, что в них изменяется от запроса к запросу и разберем каждую строчку на примере партиционированной и непартиционированной таблицы.

Сегодня все крупные компании сохраняют и обрабатывают большие объёмы информации, причём стремятся делать это максимально эффективным для бизнеса способом. Меня зовут Мазаев Роман и я работаю в проекте загрузки данных на платформу SberData. Мы используем PySpark, который позволяет очень быстро распределённо обрабатывать данные в оперативной памяти узлов нашего кластера на базе Hadoop. Я поделюсь способом, с помощью которого можно снизить потребление ресурсов кластера за счёт перезапуска PySpark-приложений между выполняемыми Spark-задачами, и расскажу, как это делать правильно.

Всем привет! Случались ли у вас ситуации, когда количество DAG’ов в вашем Airflow переваливает за 800 и увеличивается на 10-20 DAG’ов в неделю? Согласен, звучит страшно, чувствуешь себя тем героем из Subway Surfers… А теперь представьте, что эта платформа является единой точкой входа для всех аналитиков из различных команд и DAG’и пишут более 50 различных специалистов. Подкосились ноги, холодный пот и желание уйти из IT?
Не спешите паниковать, под катом я расскажу о том, как контролировать потребление ресурсов DAG’ов Airflow для предупреждения неоптимально написанных DAG’ов и борьбы с ними.
Меня зовут Давид Хоперия, я Data Engineer в департаменте данных Ozon.Fintech и моим основным инструментом является Apache Airflow, поэтому настало время углубиться в детали его работы.

Привет, дорогие читатели!
Apache Tomcat — это открытое программное обеспечение, реализующее спецификации Java Servlet, JSP и Java WebSocket, предоставляя таким образом платформу для запуска веб-приложений, написанных на языке Java. Разработанный и поддерживаемый Apache Software Foundation, Tomcat служит контейнером сервлетов, который позволяет веб-приложениям использовать Java для создания динамичных веб-страниц.
Tomcat может работать как самостоятельный веб-сервер, где он обрабатывает как статические страницы, так и динамические запросы через Servlets и JSP. Однако часто Tomcat используется в сочетании с традиционными веб-серверами, такими как Apache HTTP Server или Nginx, для обработки статического контента, в то время как динамический контент обрабатывается через Tomcat.
В этой статье мы рассмотрим основной функционал Tomcat.








Казалось бы, про Apache NiFi уже писали не раз. Но если ты только знакомишься с инструментом, разобраться в таких статьях бывает нелегко. Обычно с тобой говорят так, будто ты уже давно в теме, да и задачи чаще решают явно не твои. С официальной документацией тоже все сложно: она есть, но для быстрого погружения явно не подходит.
Вот почему я решил подготовить свой гайд для новичка. Попробуем максимально быстро разобраться с первичной настройкой NiFi и NiFi Registry, подключить авторизацию по LDAP, протестировать работоспособность, рассмотреть возможные ошибки настройки и отдебажить их.
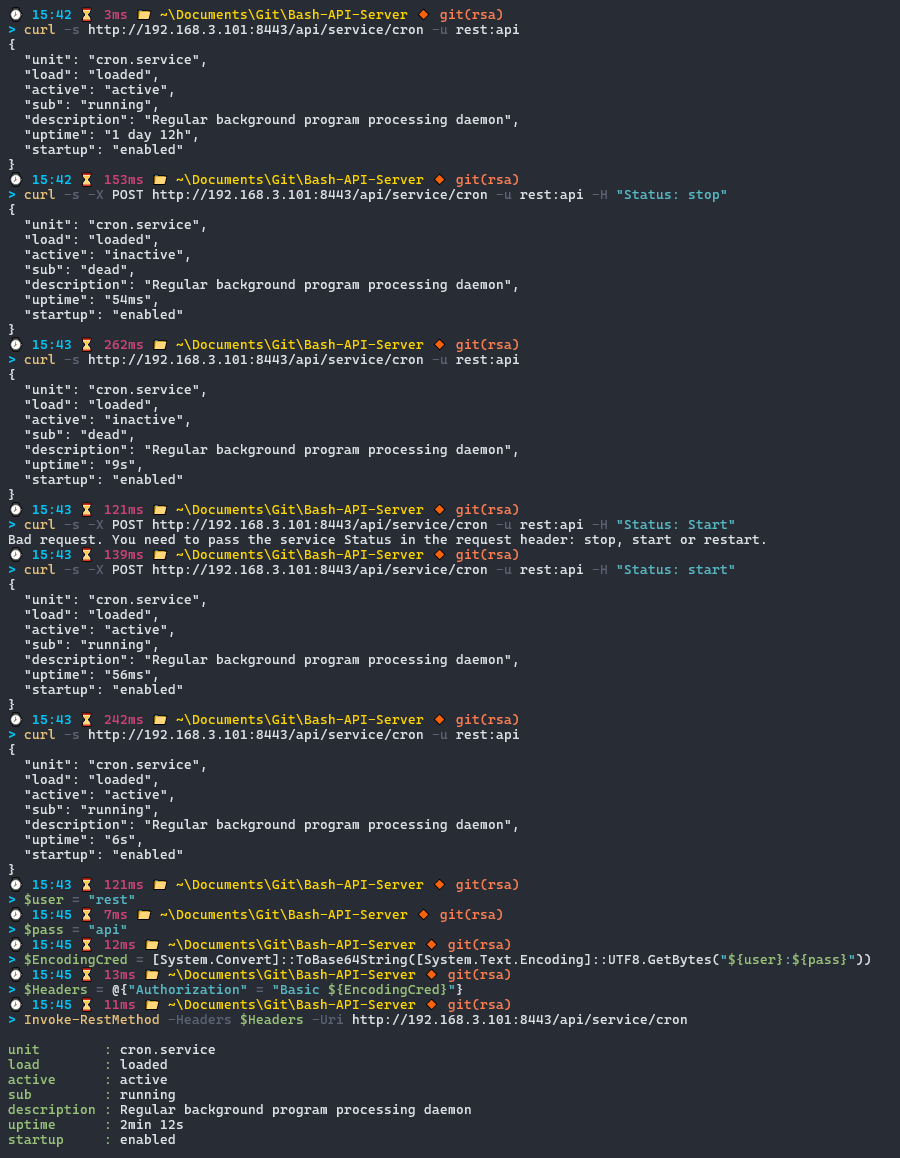
Всем привет! Ранее рассказывал о том, как создать REST API и Web-сервер на PowerShell для Windows, а также упоминал, что подобный сервер будет работать и в системе Linux, благодаря кроссплатформенной версии PowerShell Core. Безусловно, для подобных целей лучше используются специализированные серверные фреймворки или библиотеки, такие как Flask или Django в Python, но меня не покидала идея реализации похожего сервера, где описание логики будет производиться на языке одного только Bash. Приведу примеры, с помощью которых можно создать такой сервер используя сетевые сокеты netcat , socat и ncat, а также веб-сервера Apache с использованием встроенных модулей.

Коллеги, здарова! Часто бывает что нужно отправить сообщение в мессенджер к разработчикам, в случае возникновения различных проблем.
Представляю небольшое решение, которое позволит отправить сообщение в Telegram с информацией о состоянии DAG`а Apache Airflow

От проблемы к практике: как привязать JMeter к Allure Report если нет опыта программирования, но очень хочется

Когда я пришла на проект, в нём уже было много всего: много данных, много источников, много задач в Airflow. Чтобы ощутить масштаб, достаточно, пожалуй, взглянуть на одну картинку.

Привет, Хабр!
Репликация в Apache Kafka - это механизм, который обеспечивает доступность и надежность в обработке потоков данных. Она представляет собой процесс дублирования данных с одной части темы в другие, называемые репликами.
В этой статье рассмотрим основы репликации в кафке.

Салют, Хабр!
Apache Kafka - это распределенная платформа потоковой обработки, предназначенная для построения систем обработки данных. Kafka позволяет публиковать, подписываться, хранить и обрабатывать потоки данных в реальном времени. Все это дает нам очень высокую пропускную способность и масштабируемость.
Основные фигуры в кафке это продюсеры и консюмеры. Продюсеры — это компоненты, которые производят и отправляют данные в Kafka. Они могут быть чем угодно: от простых скриптов до сложных систем. Консюмеры — это те, кто подписывается на данные и обрабатывает их. Они могут быть реализованы в различных формах, например, для анализа данных или мониторинга.
В статье мы и поговорим именно про продюсерах и консюмерах в экосистеме Kafka в коннекте с Python.