

Несмотря на полезность SQL, он также подвержен определённым трудностям, которые могут серьезно сказаться на производительности баз данных.
В этой статье рассмотрим 4 типичные ошибки в SQL.
Несмотря на полезность SQL, он также подвержен определённым трудностям, которые могут серьезно сказаться на производительности баз данных.
В этой статье рассмотрим 4 типичные ошибки в SQL.

Привет, Хабр!
Хеш-индексы в PostgreSQL — это хороший инструмент для ускорения выполнения запросов.
В основе хеш-индекса лежит хеш-функция. Хеш-функция — это алгоритм, который преобразует входные данные (или ключ) в число фиксированного размера, называемое хеш-значением. В PostgreSQL хеш-функция всегда возвращает значение типа integer, что составляет примерно 4 миллиарда возможных значений.

Всем привет! Меня зовут Виктор, я работаю в Компании БФТ-Холдинг руководителем группы разработки. Продолжаю цикл статей по работе с Greenplum. В этом материале хочу рассказать, как СУБД Greenplum строит планы и выбирает самый оптимальный, а также разберу типовые проблемы, которые влияют на выбор плана запроса. Статья будет полезна разработчикам Greenplum, которые пока не имеют достаточного опыта «чтения» плана запроса.

Поговорим о блокировках в 1С:Предприятие. Идея написать эту статью появилась «по просьбам слушателей». Постараюсь максимально простым языком, без зауми рассказать о природе блокировок и что с ними делать. В один пост весь материал помещать не буду — громоздко, поэтому сегодня речь пойдет о логических блокировках сервера СУБД.
С точки зрения конечного пользователя проблема избыточных блокировок выглядит почти одинаково — замедление при выполнении операций и/или ошибка. Но природа блокировок бывает разной и решения тоже разные.

Вдохновившись прошлогодним опытом, мы продолжили начинание и снова проводим конкурс по SQL на международной олимпиаде «IT-Планета».
Конкурс состоит из трех этапов. Заочный теоретический тест собрал почти 3000 человек, из которых на следующий этап мы отобрали примерно 200. Вопросы для этого этапа были подготовлены моим коллегой, Евгением Давыдовым.
Второй этап — также заочный. Здесь участником было предложено подумать над пятью задачами моего авторства, о которых я сегодня и хочу рассказать.
Третий — очный — этап пройдет в конце мая; постараюсь не затягивать с отчетом, но пока храню интригующее молчание.
Поскольку все вводные слова про мотивацию я уже сказал в прошлый раз, сразу приступим к делу.

Привет, Хабр!
Меня зовут Денис, я Ведущий Продуктовый Аналитик из МТС. Давайте сегодня поговорим про грейды в аналитике. Чем они отличаются? Расскажу, как можно быстро повышать свой грейд.
В целом, в разных компаниях разное понимание того, чем должен обладать тот или иной грейд. Однако, есть основные пункты, которые повторяются во многих командах, про них мы сегодня и поговорим.

Для аналитиков, владение SQL — это база. И от познаний в SQL зачастую зависит, отправит ли вам компания, где вы собеседуетесь — оффер.
В статье мы обсудим четыре области вопросов, которые могут встретиться на собеседованиях по SQL. А в конце рассмотрим три задачки.

Различные СУБД предлагают широкий набор разновидностей операторов JOIN для таблиц. Если Вам встретилась проблема с производительностью CROSS JOIN, - например, декартово произведение таблицы с миллионом записей самой на себя, - добро пожаловать, в этой статье перечислены простейшие способы избавиться от CROSS JOIN.
Конечно, можно пересмотреть и упростить саму бизнес-логику или способы расчетов, в данной статье рассмотрены некоторые базовые случаи, про которые не стоит забывать и имеет смысл проверять первыми. Надеюсь, они окажутся релевантными или смогут помочь найти другие SQL оптимизации.
Примеры в статье рассматриваются на основе CROSS JOIN из ClickHouse. Текущая версия ClickHouse не оптимизирует CROSS JOIN автоматически. Также стоит отметить, что поскольку часто SQL запросы не пишутся вручную, а, например, собираются по частям программно, то перечисленные далее случаи вполне реальны.

GTT – global temporary tables, таблицы которые наполняются и очищаются в рамках ABAP-сессии (application session), но находятся при этом на уровне БД (то есть данные не передаются между Database и Application).
GTT могут помочь сделать код по выборке из БД более удобочитаемым, а также сократить количество передаваемых данных между DataBase и Application.

Многие Golang-разработчики пробовали работать с БД в Go, и у каждого — свои боли. В этой статье разберём библиотеку database/sql как безотносительно конкретной СУБД, так и применительно к YDB. Рассмотрим трудности эксплуатации при использовании драйвера database/sql на проде. А также рассмотрим, что мы делали для решения проблем.
Меня зовут Алексей Мясников, я — руководитель Application Team в команде разработки YDB. Я очень люблю git blame за то, что с его помощью можно проследить, как развивалась инженерная мысль с течением времени и немножко побыть в шкуре разработчика той или иной классной штуки. В статье я расскажу, как реализовать драйвер database/sql для распределённой базы данных, какие проблемы при этом придётся преодолеть и как менялся подход с выходом новых версий Go.

Hola, Amigos! Меня зовут Евгений Шмулевский, я backend-разработчик на Laravel в агентстве продуктовой разработки Amiga. В статье описываю организацию поиска через Meilisearch и нюансы использования в связке с Laravel.

Как реализовать хранение и работу каталога папок в PostgreSQL? Есть большое количество вариантов. Но хочется, чтобы реализация выглядела лаконично, не нарушала прозрачность выполняемых операций, не вызывала блокировок, не требовала большого вовлечения клиента в специфику работы и т.д. Потому сегодня попробуем реализовать хранение древовидных структур и работу с ними без использования триггеров, блокировок, дополнительных таблиц (представлений) и внешних инструментов в SQL.
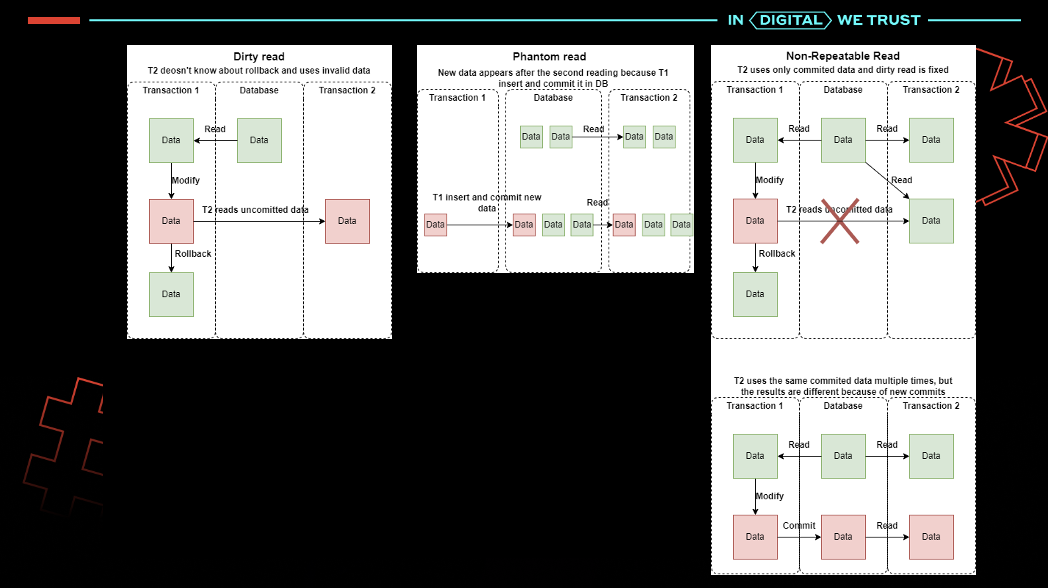
Данный материал позволит вам подготовиться к собеседованию, освежить знания или познакомиться с такими терминами как транзакции, ACID и уровни изоляции.
Важно отметить, что речь пойдет о реляционных базах данных, которые наилучшим образом подходят для транзакций и соответствуют критериям ACID.







Всем привет!
Как вы знаете, многие поставщики ПО ушли с российского рынка ввиду введённых санкций и многие компании столкнулись с необходимость заняться импортозамещением в кратчайшие сроки. Не стал исключением и наш заказчик. Целевой системой, на которое было принято решение мигрировать старое хранилище, стал Greenplum (далее GP) от компании Arenadata.
Этой статьей мы запускаем цикл материалов посвященных Greenplum. В рамках цикла мы разберем, как вообще устроен GP и как выглядит его архитектура. Постараемся выделить must have практики при работе с данным продуктом, а также обсудим, как можно спроектировать хранилище на GP, осуществлять мониторинг эффективности работы и многое другое. Данный цикл статей будет полезен как разработчикам БД, так и аналитикам.

Сначала запрос адаптирован для работы в PostgreSQL 15.6.
Затем работа запроса проверена на достаточно объемной иерархии - в качестве источника данных использована структура архива jdk-master.zip из OpenJDK 22
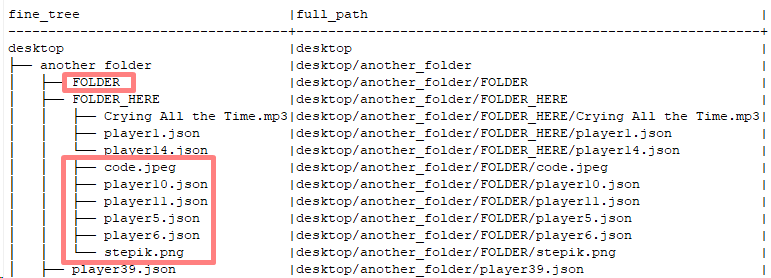
Продолжение статьи, в которой предложено решение задачи визуализации иерархической структуры средствами SQL запросов, на примере MySQL и SQLite
В этой части производится доработка запросов для отображения части иерархии, начиная с конкретных узлов, и анализируются возможные связанные ошибки
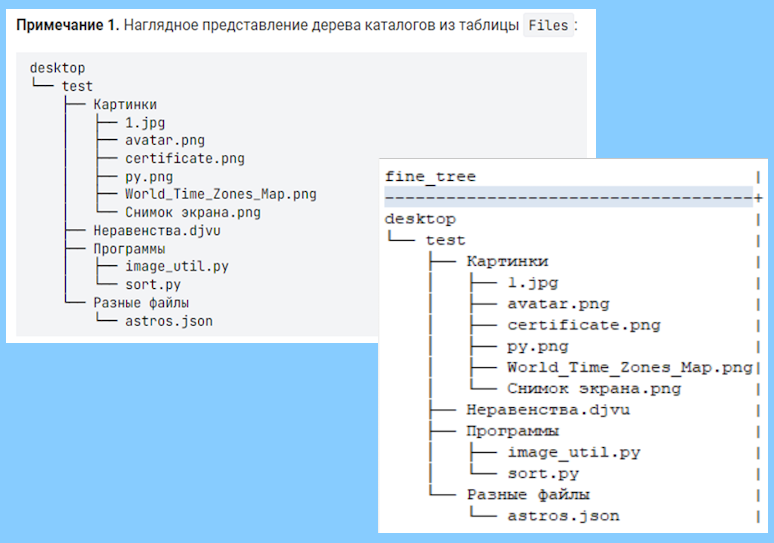
В процессе тестирования одного курса по SQL на stepik.org встретилась задача, из которой сочинилась другая, более интересная:
Необходимо с помощью одного SQL запроса с использованием обобщенных табличных выражений отобразить иерархию, в соответствии с иллюстрацией выше

Yandex Query Language (YQL) — универсальный декларативный язык запросов к системам хранения и обработки данных, разработанный в Яндексе. А ещё это один из самых нагруженных сервисов: YQL ежедневно обрабатывает около 800 петабайт данных и 600 000 SQL-запросов, и эти показатели постоянно растут.
Изначально YQL основывался на операциях MapReduce, которые эффективны для больших данных. Но для средних объёмов данных (до 50 Гб, которые составляют около 60% запросов) этот подход оказался неоптимальным, потому что нужно было обмениваться данными между операциями через диск. Поэтому разработчики создали новый более гибкий стриминговый движок, который значительно ускоряет обработку данных за счёт выполнения всех вычислений в памяти.
В этой статье я хочу рассказать о подходах и технологиях в разработке систем для обработки данных на примере YQL. Основное внимание я уделил переходу от MapReduce к стриминговому движку, который обеспечивает более эффективную обработку данных, вмещающихся в память, и который доступен в опенсорсе.

Нежданно ни гадано, затеяли значит высшие "итишные" силы включить новые заморские очереди Кафка в уже выполненный на 4/3 проект и слава богу, что только для внешних взаимодействий и передачи всякой информации туды-сюды. Главный архитектор дал благословение и понеслось, да не туда, так как нести то некому это невиданное заморское чудо. Что делать, в обозримые сроки не впихнуть и перед боярами чин и обязательства не сдержать. Посидел РП, погоревал, да сдул пыль со знаний древних и ранее опробованных и тут понеслось.

Привет, Хабр! Я Денис, ведущий продуктовый аналитик!
Я не отниму у Вас много времени, а постараюсь максимально кратко и четко рассказать про основные фишки, которые помогут Вам на собеседованиях.
Давайте начинать!