
Ранее мы рассматривали интеграцию YDB c Liquibase, теперь поговорим о результатах поддержки инструмента Flyway для управления миграциями схемы данных YDB.
И дополнительно разберем, как мы реализовали распределенную блокировку в Flyway.
Ранее мы рассматривали интеграцию YDB c Liquibase, теперь поговорим о результатах поддержки инструмента Flyway для управления миграциями схемы данных YDB.
И дополнительно разберем, как мы реализовали распределенную блокировку в Flyway.

Многие Golang-разработчики пробовали работать с БД в Go, и у каждого — свои боли. В этой статье разберём библиотеку database/sql как безотносительно конкретной СУБД, так и применительно к YDB. Рассмотрим трудности эксплуатации при использовании драйвера database/sql на проде. А также рассмотрим, что мы делали для решения проблем.
Меня зовут Алексей Мясников, я — руководитель Application Team в команде разработки YDB. Я очень люблю git blame за то, что с его помощью можно проследить, как развивалась инженерная мысль с течением времени и немножко побыть в шкуре разработчика той или иной классной штуки. В статье я расскажу, как реализовать драйвер database/sql для распределённой базы данных, какие проблемы при этом придётся преодолеть и как менялся подход с выходом новых версий Go.

10 лет назад сотни серверов Яндекса работали на Apache Kafka®, но в этом продукте нам нравилось далеко не всё. Наши задачи требовали единой шины для передачи всех видов данных: от биллинговых до журналов приложений. Сегодня объёмы достигли уже десятков тысяч именованных наборов сообщений.
При таком количестве данных в Apache Kafka® становилось сложно управлять правами доступа, организовывать распределённую работу нескольких команд и многое другое. Проблемы роста и отсутствие подходящего решения в открытом доступе привели к тому, что мы разработали своё решение YDB Topics и выложили его в опенсорс в составе платформы данных YDB. В этом посте расскажу о предпосылках создания продукта, нашей архитектуре передачи данных, возникающих задачах и возможностях, которые появились вместе с YDB Topics.

В этой статье мы подробно рассмотрим процесс интеграции одного из наиболее известных и широко используемых в мире Java инструментов для управления миграциями - Liquibase - с YDB.
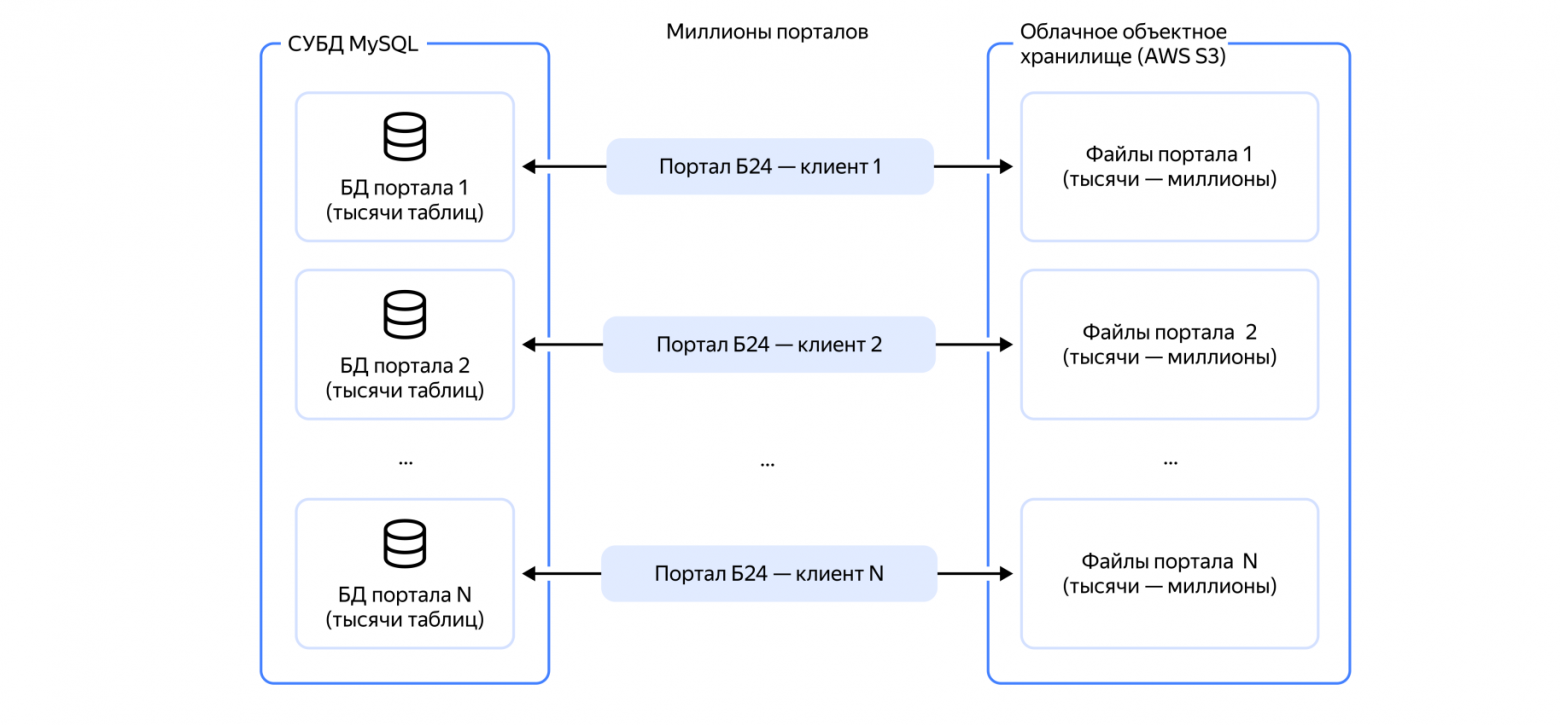
Меня зовут Александр, я руковожу направлением больших данных в Битрикс24. Клиенты нашего сервиса хранят миллиарды файлов: от документов до фотографий, — а моя команда предоставляет возможность строить бизнес-аналитику на основе этого множества данных. И нам важно позаботиться об их сохранности.
Более 10 лет назад мы продумали необходимую нам схему репликации объектного хранилища в облаке. Затем файлы клиентов потребовалось перенести в другое облако, и нам очень хотелось также перенести все наши наработки в режиме «Ctrl+C, Сtrl+V».
В статье расскажу, как мы организовали резервирование данных в парадигме слабого связывания и как перенесли эту схему в Yandex Cloud без потери важных нам деталей.

Первоначальная документация YDB, опубликованная в рамках open-source запуска в 2022 году, имела структуру, на которую в значительной степени повлиял закон Конвея. Создание проекта с открытым исходным кодом значительно повышает планку того, что ожидается от документации по технологии. В нашем случае для быстрого создания большого количества контента перед запуском потребовалась командная работа по принципу «разделяй и властвуй». На раннем этапе такое четкое владение каждым фрагментом было полезным. Однако, поскольку общий объем документации со временем продолжает расти, читателям становится всё труднее находить нужную им информацию. Чтобы решить эту проблему, мы перепроектируем структуру документации, чтобы она была ориентирована на пользователя. Таким образом, если вы являетесь командой, работающей с кластером YDB, каждый может иметь свою собственную любимую директорию в документации в соответствии со своей ролью в команде и не отвлекаться на контент, ориентированный на читателей с другой ролью.
Эта реструктуризация ещё в процессе: появился новый раздел для DevOps-инженеров, а также дополнительные разделы для администраторов баз данных, разработчиков приложений, инженеров по безопасности, аналитиков и т.д. Перемещение контента может потребовать выработки новых привычек, но в долгосрочной перспективе такая структура должна упростить навигацию. Мы создаём перенаправление со старого URL на новый при перемещении любой страницы документации, чтобы свести неудобства к минимуму.

Общеизвестно, что PostgreSQL - крайне эффективная СУБД с богатой функциональностью. При этом не секрет, что PostgreSQL масштабируется только вертикально и её производительность ограничена возможностями одного сервера.
Написано много хороших постов, в которых сравнивают архитектуру монолитных и распределенных СУБД. К сожалению, обычно авторы ограничиваются теоретическим сравнением и не приводят конкретные цифры. Данный пост же наоборот основан на эмпирическом исследовании с использованием бенчмарка TPC-C, который является промышленным стандартом для оценки производительности транзакционных СУБД (On-Line Transaction Processing, OLTP).
Мы расскажем, когда именно одного Postgres'a становится мало, и какие возможны компромиссы между производительностью и надежностью. Для тех, кто не готов к компромиссам, мы покажем, что могут предложить такие распределенные СУБД, как CockroachDB и YDB.

Краткий дайджест свежего контента и новой функциональности в документации YDB за декабрь прошлого года.

В этом посте мы расскажем о примере дедлока в TPC-C для PostgreSQL, причиной которого является исключительно переход на виртуальные потоки Java 21 - и никаких проблем обедающих философов.

Любой более или менее серьезный продакшен, работающий с базой данных, подразумевает процесс миграции - обновление структуры базы данных от одной версии до другой (обычно более новой) [источник].
Миграции в БД можно делать вручную или использовать для этого специальные утилиты (фреймворки). В данной статье речь идет об утилите goose. Это инструмент миграции схемы, который обеспечивает управление миграциями схемы в проекте. Начиная с версии v3.16.0 goose поддерживает YDB - распределенную open-source СУБД. В данной статье мы будем разбирать кейс применения миграций конкретно в YDB.

Документация YDB разрабатывается на GitHub рядом с основной кодовой базой YDB и автоматически публикуется на сайт посредством CI/CD. Быть в курсе что в ней появляется можно с помощью функции «Watch» на GitHub или периодически просматривая вывод команды git log , но эти способы сложно назвать удобными. В этом дайджесте мы рассмотрим основные недавно опубликованные изменения в документации YDB.

Существуют различные способы снижения стоимости выполнения SQL-запросов в современных СУБД. Наиболее распространенными подходами являются использование подготовленных запросы и кэширование. Оба метода доступны в YDB.
Кэширование запросов позволяет скомпилировать запрос один раз (проанализировать его, построить оптимальный план запроса, в т.ч. JIT-скомпилировать в машинный код), а затем повторно выполнить его с разными значениями параметров. Это позволяет сократить общее время выполнения запроса на величину времени компиляции запроса. Кроме того, кэширование запросов значительно сокращает объем вычислительных ресурсов, необходимых для выполнения повторяющихся пользовательских запросов, поскольку они компилируются только при первом запросе (и инвалидации кеша). Ниже мы объясняем, почему в самых общих случаях необходима Prepare, какие трудности возникают с этим в случае распределенной СУБД и как кэшировать запросы без Prepare.
В нашем предыдущем посте о производительности YDB, посвященном Yahoo! Cloud Serving Benchmark (YCSB), мы упоминали, что готовим к публикации результаты других бенчмарков. Мы придерживаемся плана и сегодня рады представить вашему вниманию наши первые результаты бенчмарка TPC-C*, который является индустриальным стандартом оценки производительности онлайн транзакций (OLTP). Согласно этим результатам есть сценарии, в которых YDB немного превосходит CockroachDB, другую хорошо известную распределенную SQL СУБД.

Статьи про YDB публиковались на Хабре ещё до выхода в open source, а отдельным блогом мы обзавелись всего несколько недель назад. В связи с этим проведём небольшую ретроспективу — что пишут про YDB в других хабах.

Восемь разработчиков YDB собрались, чтобы поделиться тем, что они сделали для последнего релиза YDB v23.1. Рассмотренные новые возможности можно разделить на две категории: функциональные улучшения и улучшения производительности.

YQL — это SQL‑диалект, специфичный для базы данных YDB. YQL требует заранее объявлять имена и типы параметров запроса. Это обеспечивает высокую производительность и корректное поведение. В синтаксисе YQL параметры необходимо перечислять явно с помощью инструкции DECLARE. И этот нюанс YDB может быть неожиданным для пользователей традиционных баз данных. В статье раскрывается вспомогательный механизм, позволяющий писать привычные простые SQL‑запросы при работе с YDB.

Привет! Меня зовут Евгений Иванов, я разработчик YDB. Мне очень нравится заниматься задачами, связанными с производительностью: бенчить, анализировать, оптимизировать. И в YDB мы придаем очень большое значения тому, чтобы быть эффективными. В этом посте я хочу представить Вашему вниманию перевод нашей свежей статьи "YCSB performance series: YDB, CockroachDB, and YugabyteDB".
Реализовать распределённую систему управления базами данных (СУБД), высокопроизводительную, масштабируемую и консистентную, — настоящий вызов. В YDB успешно с ним справились, и наши пользователи могут это подтвердить. Мы ещё не делились показателями нашей производительности на широкую аудиторию, но понимаем их значимость. Поэтому сегодня мы расскажем о результатах нашего исследования производительности.
YDB — это распределённая реляционная СУБД. Производительность распределённых транзакций в TPC-C и других сложных бенчмарках во многом зависит от реализации хранения данных по ключу. В этом посте посте мы сравним результаты тестов YCSB для YDB и двух других известных распределённых SQL-баз данных — CockroachDB и YugabyteDB. Спойлер: YDB превзойдёт конкурентов по многим нагрузкам YCSB.

Меня зовут Алексей Мясников, я тимлид на проекте YDB в Яндекс Облаке. А ещё — старший ментор на курсе «Go-разработчик» в Яндекс Практикуме и кандидат технических наук. В коммерческой разработке более 15 лет, стек — C++, Java, Go, TypeScript, а пробовал около 20 языков программирования, в том числе в продакшн.
Эта статья про Go и микросервисную архитектуру написана на основе вебинара для Практикума.
Рассмотрим, как работает Jaeger, один из популярных инструментов, который помогает расследовать инциденты и находить узкие места в производительности в микросервисной архитектуре. Разберём, как правильно настроить трассировку и с какими проблемами можно столкнуться в процессе.