
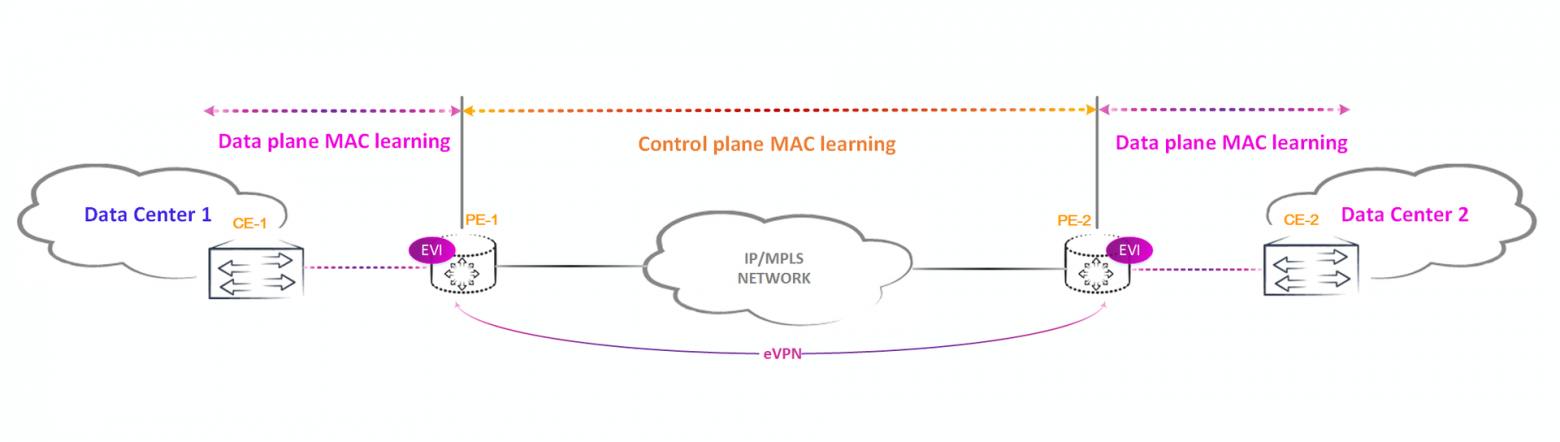
Как вы помните из прошлого выпуска провайдер linkmeup встал на ступень Tier 2. Но просто предоставлять услуги доступа в Интернет или L2/3VPN-ы (быть по сути трубой для трафика) Linkmeup не устраивает. Сейчас большим спросом пользуются услуги облачного хранения данных, поэтому linkmeup обзавелся несколькими собственными датацентрами, расположенные по экономическим соображениям в Рязани. В связи с этим перед нами встала новая задача — как связать датацентры между собой и предоставить клиентам доступ к корпоративным СХД, расположенные в наших автозалах? Ввиду того, что в core-network уже запущен MPLS, то наш выбор пал на EVPN/MPLS. Его и рассмотрим.
Данная технология решает проблемы существующих на сегодняшний день методов объединения датацентров через виртуальную L2 сеть. Конечно, эта технология не единственная в своем роде, но другие мы пока что рассматривать не будем в силу их проприетарности. Всегда надо смотреть в будущее и хотя сегодня мы будем строить сеть исключительно на Juniper MX, мы, как провайдер, не можем быть уверены в том, что завтра у нас не появятся парочка ASR9K. Возможно, некоторые из решений, примененных в EVPN, вам покажутся слишком сложными и непонятными. Но при этом не стоит забывать зачем эта технология была придумана, какие проблемы она решает и возможно ли было реализовать это по-другому. Хотя в названии присутствует слово микровыпуск, не стоит думать, что данная статья будет маленькой и простой. Наоборот, объем статьи более 115 000 знаков (порядка 60 страниц А4, написанных 11-м шрифтом) и многое из описанного не совсем очевидно и понятно с первого раза.
Сразу хочу заострить внимание читателя на том, что в данной статье мы будем разворачивать и рассматривать на практике EVPN поверх MPLS, а не VXLAN. Но, как вы понимаете, EVPN это control plane, поэтому принцип работы что поверх MPLS, что поверх VXLAN будет примерно одинаков, но есть и существенные отличия. Поэтому, если вы хотите поближе узнать EVPN/VXLAN, то можете почитать документацию, например, Brocade — у них эта тема хорошо раскрыта, либо документацию Cisco на коммутаторы серии Nexus. Ну а мы приступим к изучению EVPN/MPLS.
Содержание статьи:
1.0. Вспоминаем VPLS
2.0. Базовая часть технологии EVPN
3.0. Лаборатория для тестов и конфигурации
4.0. Маршрут типа 3
5.0. Маршрут типа 2
5.1. Изучение MAC-адресов
6.0. Маршрут типа 1
6.1. Автоматический поиск multihomed PE и ESI label
6.2. MAC Mass Withdrawal
6.3. Aliasing label
7.0 Маршрут типа 4
7.1 Механизм выбора DF
8.0. L3-функционал в EVPN
8.1. IRB synchronisation
8.2. Маршрутизация между bridge-доменами
8.3. Выход в другие VRF и внешние сети
9.0. Зачем это все таки нужно?
10.0. Заключение
2.0. Базовая часть технологии EVPN
3.0. Лаборатория для тестов и конфигурации
4.0. Маршрут типа 3
5.0. Маршрут типа 2
5.1. Изучение MAC-адресов
6.0. Маршрут типа 1
6.1. Автоматический поиск multihomed PE и ESI label
6.2. MAC Mass Withdrawal
6.3. Aliasing label
7.0 Маршрут типа 4
7.1 Механизм выбора DF
8.0. L3-функционал в EVPN
8.1. IRB synchronisation
8.2. Маршрутизация между bridge-доменами
8.3. Выход в другие VRF и внешние сети
9.0. Зачем это все таки нужно?
10.0. Заключение
Вспоминаем VPLS
Думаю, что все уже прочитали выпуск про L2VPN и представляют себе, что такое VPLS и с чем его едят. Немного освежим в памяти какие виды VPLS существуют на сегодняшний день и чем же они существенно отличаются:
- VPLS LDP-signaling (Martini)
- VPLS LDP-signaling with BGP-Autodiscovery
- VPLS BGP-signaling (Kompella)
VPLS LDP-signaling (Martini) — наиболее простая технология, реализующая функционал VPLS, и в плане конфигурирования и в плане траблшутинга, но сложна в администрировании, так как данная не наделена функцией автоматического поиска РЕ-маршрутизаторов, входящих в один VPLS домен. Поэтому, все РЕ-маршрутизаторы, участвующие в одном VPLS домене, явно прописываются на каждом РЕ-маршрутизаторе вручную. В итоге, добавление нового сайта в существующий VPLS домен подразумевает изменение конфигурации на всех РЕ-маршрутизаторах данного VPLS домена, что, на мой взгляд, не очень удобно, особенно если у клиента 5-6 сайтов и более. К плюсам данной технологии можно отнести ее простоту и отсутствие необходимости в добавлении нового семейства адресов в протокол BGP (для части старого оборудования в тот момент, когда родилась технология, понадобилось бы обновить софт). Tак как вся сигнализация работает исключительно по LDP, то работа данной технологии была понятна инженерами без необходимости что-то заново изучать (всё-таки мы, люди, в основной своей массе существа ленивые). Но в современных реалиях, думаю, что удобнее один раз добавить новое семейство адресов в BGP (пусть даже придется обновиться софт на паре железок), а не бегать постоянно по всем PE-кам при добавлении нейбора в VPLS-домен.
VPLS LDP-signaling with BGP-Autodiscovery. В конечном счете разработчики технологии VPLS LDP-signaling все же поняли свою ошибку — отсутствие автоматического поиска других РЕ-шек сильно ограничивало масштабируемость данного решения в сравнении с VPLS BGP-signaling, поэтому было решено добавить в данную технологию автоматический поиск РЕ-маршрутизаторов. Естественно, средствами LDP это реализовать у них не получилось, поэтому был использован великий и могучий BGP, в который было добавлено еще одно семейство адресов (причем отличное от семейства адресов, использующихся в VPLS Kompella), зарезервировано новое расширенное комьюнити l2vpn-id и добавлен новый FEC — FEC129 (в VPLS LDP используется FEC128). В итоге, при использовании данной технологии, поиск PE маршрутизаторов производится по протоколу BGP, а L2 каналы уже сигнализируются по LDP. На мой взгляд, данными действиями разработчики перечеркнули все, чем они гордились до этого и, если ваше оборудование поддерживает и Martini+BGP AD и Kompella, то лично я бы предпочел второе.
VPLS BGP-signaling (Kompella). Данная технология сильно отличается от двух предыдущих — общая у них только цель — организация виртуальной L2 сети поверх сети провайдера. Данный вид VPLS использует для сигнализации протокол BGP, который обеспечивает и автоматический поиск соседей и сигнализирование виртуальных L2 каналов. В итоге мы имеем хорошо масштабируемое решение, а меньшая распространенность VPLS BGP-signaling в сетях провайдеров обусловлена скорее всего тем, что данная разработка продвигалась Juniper и до определенного времени просто не поддерживалась другими вендорами, а также кажущаяся на первый взгляд сложность самой технологии — чего стоит одна модель распределения меток.
Все перечисленные технологии обеспечивают один и тот же результат — организацию виртуальной L2 сети поверх сети провайдера, разнятся только средства реализации и возможности данных технологий, о которых вы можете почитать в предыдущем выпуске СДСМ. Но у данных технологий есть несколько общих проблем, которые накладывают определенные неудобства при эксплуатации и не дают покоя разработчикам. Таких проблем как минимум три:
1. Нет возможности для multihomed сайтов (сайтов, подключенных к 2-м и более PE маршрутизаторам одновременно) использовать все линки для передачи трафика (работать в Active-Active mode);
2. Эти технологии не предоставляют расширенных функций L3, за исключением банального добавления BVI/IRB интерфейса в VPLS домен для выхода во внешнюю сеть;
3. MAC-адреса изучаются исключительно на уровне data plane, что приводит к увеличению флуда BUM трафика в сети провайдера.
Бороться с этими недостатками в VPLS уже бесполезно — это сильно усложнит и так не простые технологии (к примеру есть технология NG-VPLS, которая используется P2MP LSP, но о ее реальном использовании я не слышал). Поэтому была изобретена новая технология, в которой данные недостатки были устранены. Сегодня мы поговорим об Ethernet VPN (EVPN). Бытует мнение, что данная технология является развитием VPLS BGP-signaling, думаю, что для простоты восприятия, не будет лишним в данной статье сравнивать EVPN c VPLS BGP-signaling (далее буду писать просто VPLS, что подразумевает именно VPLS BGP-signaling).
Лично мое мнение, что данная технология является гибридом L3VPN и VPLS BGP-signaling. А почему, думаю, вы поймете, дочитав статью до конца. Итак, поехали…
Базовая часть технологии EVPN
Как и VPLS, EVPN использует для сигнализации исключительно протокол BGP, но использует уже новые NLRI: AFI 25 SAFI 70 (некоторые версии Wireshark еще не знают данное AFI/SAFI и при снятии дампа пишут unknown SAFI for AFI 25). Использование нового семейства адресов обусловлено тем, что EVPN использует для изучения MAC-адресов не только data-plane, как в стандартном VPLS или коммутаторе, но и control-plane:
Маленькое лирическое отступление: возможно иллюстрации в стиле Brocade кому-то не понравятся, но использование данных иллюстраций обусловлено тем, что если использовать обозначения маршрутизаторов и коммутаторов в стиле Juniper или Cisco, то мы на некоторых рисунках получим не читаемое месиво, а нам этого не хочется. Ну и лично мне такие рисунки как то больше нравятся (но это, как говорится, на вкус и цвет...). Ниже представлен список всех обозначений на схемах:

Давайте рассмотрим, как же происходит изучение MAC-адресов в EVPN. Использовать будем вот такую банальную сеть:

Представим, что CE1 хочет отправить ICMP пакет на CE2:
1. Так как у CE1 нет MAC-адреса CE2, то CE1 делает широковещательный ARP запрос на резолв адреса CE2.
2. PE1, получив от CE1 широковещательный пакет, анализирует его заголовок и понимает, что этот пакет надо переслать всем остальным PE маршрутизаторам в данном широковещательном домене. Помимо этого, PE1 записывает source MAC в MAC-таблицу соответствующего bridge-домена.
Если бы у нас был VPLS, то больше никаких операций PE1 не стал бы производить. Но у нас EVPN, поэтому PE1 генерирует BGP Update, в котором указывает MAC-адрес CE1 и метку VPN, и отправляет его на все остальные PE маршрутизаторы (естественно, через роутрефлектор).
3. PE2 и PE3 получают данный широковещательный пакет и отправляют его всем подключенным CE-маршрутизаторам. Как и в VPLS, в EVPN есть функция split horizon — пакет, полученный от PE маршрутизатора, не будет отправлен на другие PE маршрутизаторы.
В VPLS PE2 и PE3, при получении пакета от PE1, должны были бы записать MAC-адрес CE1 в MAC-таблицы и ассоциировать его с PW в сторону PE1. Но в EVPN изучать MAC-адреса по source адресам пакетов, пришедшим от других PE маршрутизаторов, нет необходимости, ведь PE1 уже сделал анонс MAC+label, а значит PE1 и PE2 запись в таблицу MAC-адресов сделают по данному анонсу (да, как в L3VPN с IPv4 префиксами).
4. PE2 получает от CE2 ответ на данный ARP запрос. Так как MAC-адрес CE1 и метка до него уже известны из полученного от PE1 BGP анонса, то пакет отправляется юникастом прямиком на PE1. Помимо этого PE2 записывают MAC-адрес CE2 в MAC-таблицу и генерирует BGP Update, в котором указывает MAC-адрес CE2 и метку, и отправляет его на остальные PE маршрутизаторы.
5. PE1 получает уже юникастовый пакет и по MAC-таблице отправляет его в соответствующий интерфейс.
Как вы уже поняли, EVPN использует MAC-адреса, как роутинговые адреса. Это можно сравнить с распределением маршрутов внутри L3VPN.
Думаю все прочитавшие статью о L2VPN помнят, что в VPLS распределение меток с помощью BGP производится блоками, так как получателю пакета (в смысле PE маршрутизатору) необходимо знать, с какого PE-маршрутизатора прилетел данный пакет, и ассоциировать MAC-адрес с PW до этого PE маршрутизатора. В EVPN такой необходимости уже нет. Это происходит из за того, что EVPN обрабатывает MAC-адреса, так же, как L3VPN IPv4 префиксы — PE маршрутизатор, изучив новый MAC-адрес через data plane от подключенного CE маршрутизатора, сразу анонсирует данный MAC по BGP. В BGP анонсе указывается MPLS метка и protocol next-hop (как правило, это лупбек PE маршрутизатора). В итоге все остальные PE маршрутизаторы знают куда отправлять пакет и с какой меткой.
Интересный факт: в VPLS (любом его виде), в описанном выше сценарии, PE3 узнала бы только MAC-адрес CE1, так как от CE2 к CE1 пакет передается уже юникастом и не попадет на PE3. А при использовании EVPN PE3 изучает оба MAC-адреса: и CE1 и CE2, первый узнает из анонса от PE1, второй из анонса от PE2.
Надеюсь, принцип работы технологии понятен, и теперь мы можем перейти от теории к практике и посмотреть на работу EVPN на примере.
Лаборатория для тестов и конфигурации
Для тестов я использовал Unetlab, в которой собрал стенд из четырех vMX и трех Cisco IOL (L3). Как вы понимаете vMX-сы используется для эмуляции сети провайдера, а Cisco — как клиентские CE маршрутизаторы. Если кому интересно, то данная лаба была запущена на самом обычном ноутбуке с i5 и 12 Гб ОЗУ (из которых только 6 было занято, а загрузка CPU не превышала 30 процентов) — так что можете запустить у себя и пощупать EVPN.
Наша схема выглядит следующим образом:

Как вы поняли, у нас три PE маршрутизатора, один P-маршрутизатор, он же и роутрефлектор, и три CE маршрутизатора. Вся адресация для удобства приведена на схеме.
Juniper позволяет нам сконфигурировать routing-instance для EVPN двумя способами — первый это instance с типом EVPN — самый простой, и второй, instance с типом virtual-switch. Лично мне больше нравится второй вариант, так как он более гибок, но для наглядности в нашей лабе мы будем использовать оба способа. Однако различия этих двух способов не только в конфигурации.
VLAN Based Service — данный тип использования EVPN хорош тем, что bridge-домены полностью изолированы друг от друга. Но на каждый влан придется делать новую routing instance. В таком сценарии трафик между PE маршрутизаторами может идти как с влан тегом так и не тегированным. JunOS по умолчанию отправляет тегированный трафик с оригинальным тегом (если, конечно, не настроены какие-либо правила перезаписи тега на интерфейсе).
Конфигурация routing instance с типом EVPN выглядит вот так:
bormoglotx@RZN-PE-3> show configuration routing-instances RZN-VPN-1 instance-type evpn; vlan-id 777; interface ge-0/0/2.200; interface ge-0/0/2.777; routing-interface irb.777; route-distinguisher 62.0.0.3:1; vrf-import VPN-1-IMPORT; vrf-export VPN-1-EXPORT; protocols { evpn { interface ge-0/0/2.777; } } bormoglotx@RZN-PE-3> show configuration interfaces ge-0/0/2 description "link to RZN-CE3-SW1"; flexible-vlan-tagging; encapsulation flexible-ethernet-services; mac 50:01:00:03:00:04; unit 777 { encapsulation vlan-bridge; vlan-id 777; family bridge; }
В конфигурации инстанса с типом EVPN стоит обратить внимание на такую строчку:
bormoglotx@RZN-PE-3> show configuration routing-instances RZN-VPN-1 | match vlan vlan-id 777;
Это значение определяет, какой тег используется для нормализации. То есть если к данному EVPN инстансу будет подключен помимо влана 777 еще и влан 200 (как в показанном выше конфиге), то при получении пакета с тегом 200, PE маршрутизатор будет снимать данный тег (тег 200) и навешивать новый — 777. На прием PE-ка будет действовать в обратной последовательности — сниматься тег 777 и навешивать тег 200 при отправке в интерфейс в сторону CE-маршрутизатора, в нашем случае в интерфейс ge-0/0/2.200 (см конфигурацию выше, на схемах данный CE маршрутизатор не показан).
Это минимальная конфигурация, которая позволит EVPN работать (не забываем про базовую настройку сети — IGP, MPLS и т.д., которая тут не представлена). Как видите, мы указываем RD и RT, так как для сигнализации используется BGP. Все как обычно — RD делает наш маршрут уникальным, а RT используются для фильтрации маршрутов. Политики импорта и экспорта на всех PE-маршрутизаторах одинаковые, но для тех, кому интересна их конфигурация, приведу ее под спойлером:
Конфигурация политик
bormoglotx@RZN-PE-3> show configuration policy-options policy-statement VPN-1-IMPORT term DEFAULT-IMPORT { from { protocol bgp; community VPN-1; } then accept; } term REJECT { then reject; } bormoglotx@RZN-PE-3> show configuration policy-options policy-statement VPN-1-EXPORT term DEFAULT { then { community + VPN-1; accept; } } term REJECT { then reject; } bormoglotx@RZN-PE-3> show configuration policy-options community VPN-1 members target:6262:777;
VLAN Aware Service — в этом случае мы делаем только одну routing instance с типом virtual switch и добавляем в нее bridge-домены. Если у клиента будет 30 вланов, нам не надо городить конфиг на сотни строк, делая instance на каждый влан — достаточно в созданный для клиента instance добавить 30 bridge-доменов. В этом случае наличие vlan тега, согласно RFC, обязательно.
Конфигурация instance с типом virtual-switch имеет примерно такой вид:
bormoglotx@RZN-PE-1> show configuration routing-instances RZN-VPN-1 instance-type virtual-switch; interface ge-0/0/2.0; route-distinguisher 62.0.0.1:1; vrf-import VPN-1-IMPORT; vrf-export VPN-1-EXPORT; protocols { evpn { extended-vlan-list 777; } } bridge-domains { VLAN-777 { vlan-id 777; } } bormoglotx@RZN-PE-1> show configuration interfaces ge-0/0/2 description "link to RZN-CE1-SW1"; flexible-vlan-tagging; encapsulation flexible-ethernet-services; mac 50:01:00:01:00:04; unit 0 { family bridge { interface-mode trunk; vlan-id-list 777; } }
Никаких проблем при использовании с одной стороны EVPN, с другой virtual switch быть не должно (если вы все делаете как положено), так как JunOS из инстанса EVPN отправляет тегированный трафик с оригинальным тегом. Во всяком случае в ходе тестирования я проблем не обнаружил. Но есть один нюанс. Стоит учитывать, что нормализация может сыграть с вами злую шутку, если вы начнете в одном и том же EVPN домене использовать разные типа инстансов не разделяя вланы по bridge-доменам. К примеру на одном PE-маршрутизаторе в инстанс с типом EVPN вы добавляете два влана: 777 и 1777, а для нормализации используете влан 777. С другого конца у вас будет virtual switch с двумя bridge доменами — vlan 777 и vlan 1777. В итоге что получаем: пакет прилетает от CE во влане 1777, происходит нормализация влана на 777 и в инстанс virtual switch пакет прилетает во влан 777. А хост назначения то во влане 1777, то есть в другом bridge домене. В итоге — у вас нет связности между хостами в одном влане. Либо другой вариант развития событий — в одном и том же bridge домене вы сконфигурировали разные теги, предназначенные для нормализации. В таком сценарии у вас тоже не будет связности (вообще не будет), так как с PE1 пакет будет улетать например с нормальным тегом 777, а на PE2 нормальный тег — 1777. В итоге PE2 будет просто отбрасывать пакеты с не соответствующим номером влана.
Маршрут типа 3
В данный момент времени еще обмена пакетами между CE маршрутизаторами не производилось (естественно, CDP, LLDP и прочие радости отключены, дабы в сеть не улетало что то лишнее), поэтому ни один из PE маршрутизаторов не изучил ни одного MAC-адреса. Это можно проверить:
bormoglotx@RZN-PE-1> show evpn instance RZN-VPN-1 brief Intfs IRB intfs MH MAC addresses Instance Total Up Total Up Nbrs ESIs Local Remote RZN-VPN-1 1 1 0 0 2 0 0 0
Из данного вывода мы можем узнать, что всего в данной routing-instance 1 интерфейс и он в активном состоянии, IRB интерфейсов у нас нет (о них позже). Мы видим двух соседей ( по нашей схеме это PE2 и PE3), а также что нами еще не изучен ни один MAC-адрес ( local — это MAC-адреса, локальные для данного PE маршрутизатора, а remote — это MAC-адреса, полученные от соседних PE маршрутизаторов).
Теперь посмотрим, какие маршруты у нас есть в таблице маршрутизации данной routing-instance:
bormoglotx@RZN-PE-1> show route table RZN-VPN-1.evpn.0 RZN-VPN-1.evpn.0: 3 destinations, 3 routes (3 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 3:62.0.0.1:1::777::62.0.0.1/304 *[EVPN/170] 01:33:42 Indirect 3:62.0.0.2:1::777::62.0.0.2/304 *[BGP/170] 01:10:22, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.1 via ge-0/0/0.0, Push 299808 3:62.0.0.3:1::777::62.0.0.3/304 *[BGP/170] 01:10:01, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.1 via ge-0/0/0.0, Push 299776
У нас всего три маршрута, причем первый локальный для PE1. Что же это за маршруты и зачем они нужны? Давайте разбираться. В EVPN существует всего 5 типов маршрутов:
- 1 — Ethernet Auto-Discovery (A-D) route
- 2 — MAC/IP Advertisement route
- 3 — Inclusive Multicast Ethernet Tag route
- 4 — Ethernet Segment route
- 5 — IP Prefix Route*
Примечание: маршрут 5-го типа в настоящее время еще не утвержден в статуте RFC, и пока что описан только в драфте и поэтому в данной статье мы его рассматривать не будем.
В представленном выше выводе мы видим, что первой цифрой в маршруте является 3, а значит это Inclusive Multicast Ethernet Tag route. Данный маршрут генерируется каждым PE маршрутизатором и используется для приема и отправки BUM трафика. Состоит маршрут из следующих полей:

RD — думаю всем понятно, что это такое, в показанном ниже анонсе это :62.0.0.3:1:
Ethernet Tag ID — это номер влана, в нашем случае :777:
IP Address Length — длина IP-адреса, указанного в следующем поле (на оборудовании Juniper данное значение не показывается)
Originating Router’s IP Address — IP-адрес оригинатора маршрута, как правило лупбек PE маршрутизатора. В нашем случае это :62.0.0.3.
Примечание: /304 — длина префикса, Juniper автоматически добавляет ее ко всем EVPN маршрутам, смысловой нагрузки по сути не несет. Как написано на сайте Juniper, данное значение означает максимальную длину маршрута и позволяет использовать эту особенность при поиске маршрутов с помощью регулярных выражений. Ну что ж, учтем на будущее.
3:62.0.0.3:1::777::62.0.0.3/304 (1 entry, 1 announced) *BGP Preference: 170/-101 Route Distinguisher: 62.0.0.3:1 PMSI: Flags 0x0: Label 299904: Type INGRESS-REPLICATION 62.0.0.3 Next hop type: Indirect Address: 0x95ca3d4 Next-hop reference count: 2 Source: 62.0.0.255 Protocol next hop: 62.0.0.3 Indirect next hop: 0x2 no-forward INH Session ID: 0x0 State: <Secondary Active Int Ext> Local AS: 6262 Peer AS: 6262 Age: 1:16:02 Metric2: 1 Validation State: unverified Task: BGP_6262.62.0.0.255+179 Announcement bits (1): 0-RZN-VPN-1-evpn AS path: I (Originator) Cluster list: 62.0.0.255 Originator ID: 62.0.0.3 Communities: target:6262:777 Import Accepted Localpref: 100 Router ID: 62.0.0.255 Primary Routing Table bgp.evpn.0
Если посмотреть на маршрут внимательнее, то мы видим следующую строку:
PMSI: Flags 0x0: Label 299904: Type INGRESS-REPLICATION 62.0.0.3
PMSI расшифровывается как Provider Multicast Service Interface, и это не что иное, как Point-to-Multipoint LSPs. В данной статье мы не будем рассматривать как работает P2MP LSP, так как это очень большая и сложная тема, но, как видите, в EVPN используется функционал p2mp LSP для пересылки BUM трафика. PE3 сгенерировал метку 299904, которую могут использовать другие PE маршрутизаторы, чтобы отправить BUM трафик на PE3.
Маршрут типа 3 генерируется на каждый влан отдельно, о чем и говорят в его названии слова Ethernet Tag. Если у вас будет два bridge-домена (например влан 777 и влан 1777), то PE маршрутизатор сгенерирует два маршрута типа 3 — по одному на каждый влан (bridge-домен).
Мы выяснили, что в начальный момент времени в таблице маршрутизации EVPN есть только маршруты типа 3, чтобы PE маршрутизаторы знали с какой меткой им отправлять широковещательные пакеты на удаленные PE маршрутизаторы.
Маршрут типа 2
Теперь запустим пинг между CE1 и CE2:
RZN-CE1-SW1#ping 10.0.0.2 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 10.0.0.2, timeout is 2 seconds: .!!!! Success rate is 80 percent (4/5), round-trip min/avg/max = 7/8/11 ms
Одни пакет потерялся, так как CE1 сделал ARP запрос на резолв адреса 10.0.0.2. Теперь посмотрим, появились ли адреса в MAC-таблице:
bormoglotx@RZN-PE-1> show evpn instance RZN-VPN-1 brief Intfs IRB intfs MH MAC addresses Instance Total Up Total Up Nbrs ESIs Local Remote RZN-VPN-1 1 1 0 0 2 0 1 1
Появились сразу два MAC-адреса: один локальный для PE1 (адрес CE1) и один MAC, полученный от PE2 (адрес CE2):
bormoglotx@RZN-PE-1> show route table RZN-VPN-1.evpn.0 RZN-VPN-1.evpn.0: 5 destinations, 5 routes (5 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 2:62.0.0.1:1::777::aa:bb:cc:00:06:00/304 *[EVPN/170] 00:05:23 Indirect 2:62.0.0.2:1::777::aa:bb:cc:00:07:00/304 *[BGP/170] 00:05:23, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.1 via ge-0/0/0.0, Push 299808
Теперь у нас в таблице два новых маршрута (всего в таблице маршрутов 5, маршруты типа 3 не показаны для сокращения вывода). Маршруты имеют тип 2 — MAC/IP Advertisement route. Данный маршрут имеет следующий вид:

RD — Route Distinguisher, куда же без него, в нашем случае равен :62.0.0.2:1;
Ethernet Segment Identifier — идентификатор ESI, о нем поговорим позже. JunOS показывает это значение только при detail или extensive выводах, у нас в маршруте он равен нулю: ESI: 00:00:00:00:00:00:00:00:00:00;
Ethernet Tag ID — номер влана :777;
MAC Address Length — длина MAC-адреса, по сути всегда 48 бит, и JunOS данное значение не выводит;
MAC Address — сам MAC-адрес: aa:bb:cc:00:07:00;
IP Address Length — длина IP-адреса, для IPv4 равна 32 битам, и для IPv6 — 128. Данное поле опционально и может не содержать никаких значений (все нули). JunOS данное значение не выводит.
IP Address — сам адрес, в выводе ниже он не представлен. Поле заполняется опционально.
MPLS Label1|2 — непосредственно сама метка, JunOS ее показывает только при detail или extensive выводе.
2:62.0.0.2:1::777::aa:bb:cc:00:07:00/304 (1 entry, 1 announced) *BGP Preference: 170/-101 Route Distinguisher: 62.0.0.2:1 Next hop type: Indirect Address: 0x95c9f90 Next-hop reference count: 4 Source: 62.0.0.255 Protocol next hop: 62.0.0.2 Indirect next hop: 0x2 no-forward INH Session ID: 0x0 State: <Secondary Active Int Ext> Local AS: 6262 Peer AS: 6262 Age: 26 Metric2: 1 Validation State: unverified Task: BGP_6262.62.0.0.255+179 Announcement bits (1): 0-RZN-VPN-1-evpn AS path: I (Originator) Cluster list: 62.0.0.255 Originator ID: 62.0.0.2 Communities: target:6262:777 Import Accepted Route Label: 300272 ESI: 00:00:00:00:00:00:00:00:00:00 Localpref: 100 Router ID: 62.0.0.255 Primary Routing Table bgp.evpn.0
Как я и написал ранее, EVPN использует MAC-адреса как роутинговые адреса. Из анонса от PE2, PE1 теперь знает, что, чтобы добраться до MAC-адреса aa:bb:cc:00:07:00 во влане 777 (обращаю внимание, что именно в 777 влане, так как один и тот же MAC-адрес может быть в разных вланах, и это будут разные маршруты), необходимо навесить на пакет две метки: 300272 (VPN) и транспортную метку до 62.0.0.2.
Примечание: помимо всем известных полей Route Distinguisher, Protocol next hop и т д, мы видим поле ESI, которое в данном анонсе выставлено в нули. Это поле очень важно при использовании multihomed сайтов, и к нему мы вернемся чуть позже, в данном сценарии оно не играет роли.
Как и L3VPN, EVPN умеет генерировать метки per-mac, per-next-hop и per-instance:
per-mac — на каждый мак адрес генерируется отдельная метка. Как вы понимаете данный вид распределения меток слишком расточителен;
per-next-hop — наверно точнее будет сказать per-CE или per-AC, то есть одна и та же метка генерируется только для MAC-адресов, находящихся за одним и тем же Attachment Circuit (то есть если к одному PE маршрутизатору в одном routing-instance подключено два CE маршрутизатора, то для MAC-адресов, изученных от CE1, PE маршрутизатор будет генерировать одну метку, а для MAC-адресов, изученных от CE2 — другую)
per-instance — одна метка генерируется на весь routing-instance, то есть у всех маршрутов будет одна и та же метка. В JunOS вы можете увидеть данную метку при просмотре EVPN instance в режиме extensive.
Изучение MAC-адресов
Теперь посмотрим на MAC-таблицу на PE1:
bormoglotx@RZN-PE-1> show bridge mac-table MAC flags (S -static MAC, D -dynamic MAC, L -locally learned, C -Control MAC SE -Statistics enabled, NM -Non configured MAC, R -Remote PE MAC) Routing instance : RZN-VPN-1 Bridging domain : VLAN-777, VLAN : 777 MAC MAC Logical NH RTR address flags interface Index ID aa:bb:cc:00:06:00 D ge-0/0/2.0 aa:bb:cc:00:07:00 DC 1048575 1048575
Колонка flag говорит нам о том, как был изучен данный адрес: MAC-адрес aa:bb:cc:00:06:00 имеет только флаг D, что означает, что этот мак изучен динамически (стандартным способом через data plane) и, так как больше никаких флагов мы не видим, то можем с уверенностью сказать, что данный MAC изучен от локально подключенного CE маршрутизатора. А вот MAC-адрес aa:bb:cc:00:07:00 имеет два флага — DC. Что значит первый флаг, мы уже знаем, а вот флаг С говорит о том, что данный адрес изучен через control plane.
Если мы посмотрим на таблицу MAC-адресов на PE3, то увидим, что все адреса изучены данным PE маршрутизатором через control plane, и нет ни одного локального MAC-адреса:
bormoglotx@RZN-PE-3> show evpn mac-table MAC flags (S -static MAC, D -dynamic MAC, L -locally learned, C -Control MAC SE -Statistics enabled, NM -Non configured MAC, R -Remote PE MAC) Routing instance : RZN-VPN-1 Bridging domain : __RZN-VPN-1__, VLAN : 777 MAC MAC Logical NH RTR address flags interface Index ID aa:bb:cc:00:06:00 DC 1048574 1048574 aa:bb:cc:00:07:00 DC 1048575 1048575
Примечание: если вы заметили, в одном случае я использовал команду show bridge mac-table, а во втором show evpn mac-table. Это обусловлено тем, что на разных PE маршрутизаторах routing instance сконфигурированы по-разному — в первом случае virtual-swicth, во втором EVPN.
На PE3 нет ни одного изученного локально MAC-адреса, так как еще не было трафика от CE3. Давайте исправим данную ситуацию, запустив пинг до CE3, и еще раз посмотрим данную таблицу:
RZN-CE1-SW1#ping 10.0.0.3 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 10.0.0.3, timeout is 2 seconds: .!!!! Success rate is 80 percent (4/5), round-trip min/avg/max = 7/10/13 ms
bormoglotx@RZN-PE-3> show evpn mac-table MAC flags (S -static MAC, D -dynamic MAC, L -locally learned, C -Control MAC SE -Statistics enabled, NM -Non configured MAC, R -Remote PE MAC) Routing instance : RZN-VPN-1 Bridging domain : __RZN-VPN-1__, VLAN : 777 MAC MAC Logical NH RTR address flags interface Index ID aa:bb:cc:00:05:00 D ge-0/0/2.777 aa:bb:cc:00:06:00 DC 1048574 1048574 aa:bb:cc:00:07:00 DC 1048575 1048575
Как видите, на PE3 теперь появился MAC-адрес CE3, изученный через data plane.
Как и у обычного свича, адреса в MAC-таблице EVPN имеют определенный “срок годности”, по умолчанию этот срок равен 300-м секундам. Если в течении данного времени этот MAC был неактивен и не обновлялся, то маршрут удаляется из таблицы. Вроде, все просто — таймер отработал — MAC удалили. Но все не так просто, как кажется. Давайте рассмотрим, как это происходит.
Итак, PE3 изучил MAC-адрес CE3 и отправил его в BGP анонсе остальным PE маршрутизаторам. Предположим, что в течении 300 секунд запись не обновлялась. Тогда PE3 должен удалить данный MAC-адрес из таблицы, что он и делает. Но мы помним, что PE3 отправил всем своим соседям информацию о том, что данный MAC-адрес находится за ним. А вдруг этот хост переехал или вообще уже выключен? Что тогда? Остальные PE маршрутизаторы так и будут слать пакеты для CE3 на PE3, как в черную дыру? Конечно, нет. Дело в том, что если PE маршрутизатор удаляет из таблицы локальный MAC-адрес, то он отправляет BGP Withdrawn сообщение, которое заставляет другие PE маршрутизаторы удалить этот маршрут, а следовательно и MAC-адрес, из своих таблиц. Давайте это проверим.
На первом скрине представлен BGP UPDATE Message, который объявляет MAC-адрес aa:bb:cc:00:07:00 (картинки кликабельны):
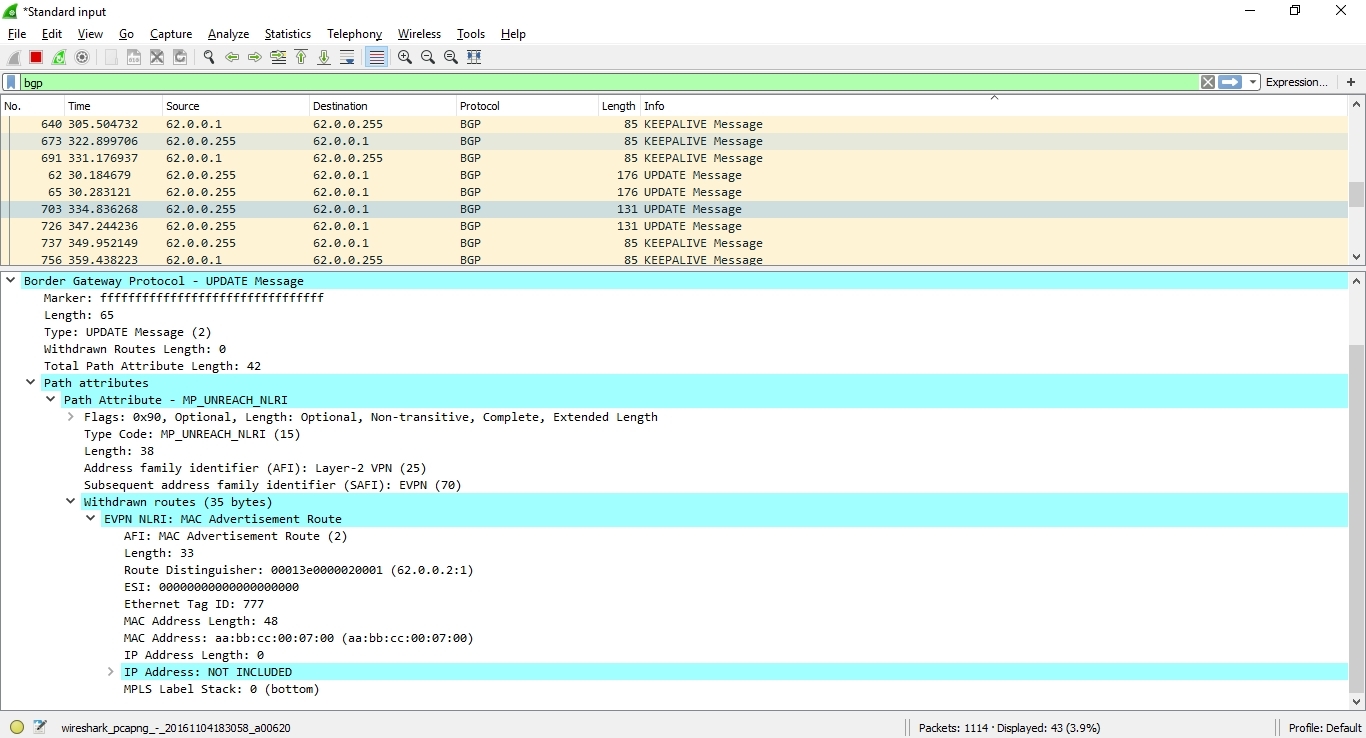
Спустя 300 секунд, мы видим еще одно BGP UPDATE Message, которое является Withdrawn сообщением, отменяющим маршрут до указанного ранее MAC-адреса:
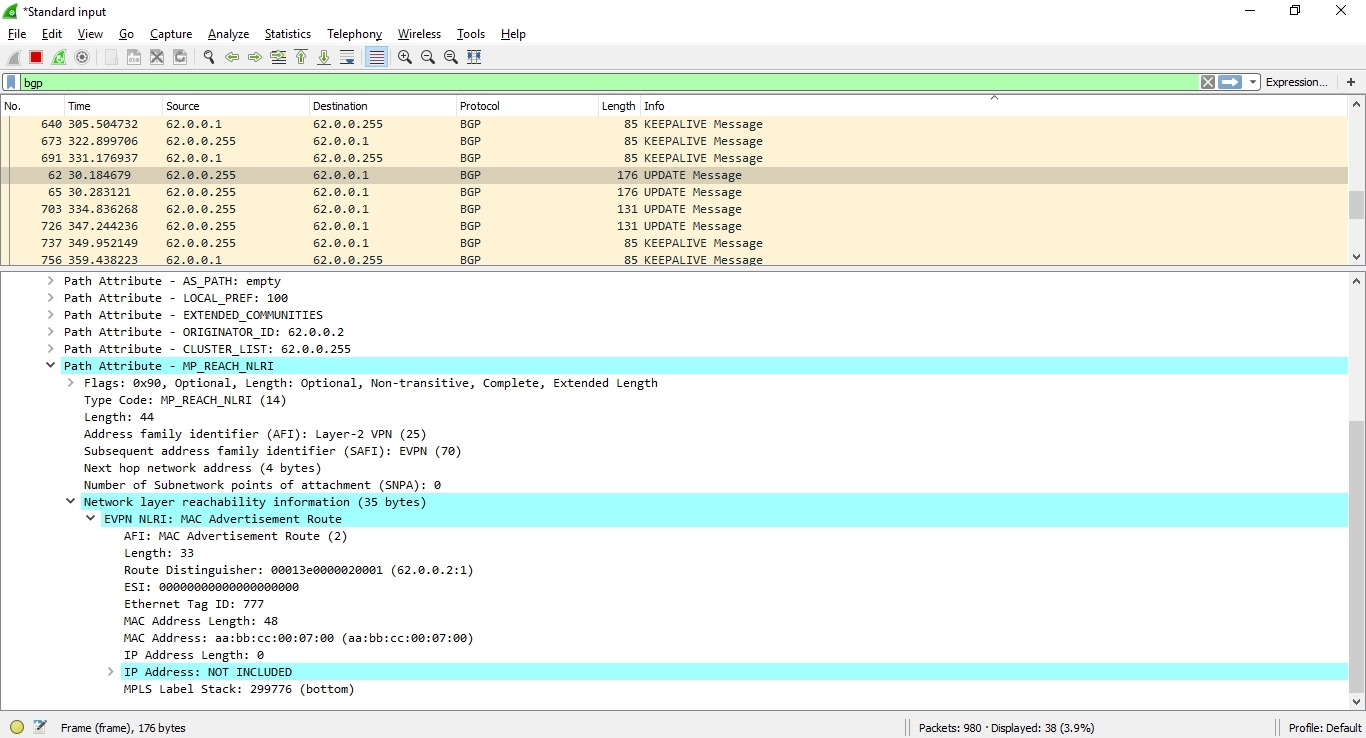
Помимо MAC aging time, у EVPN есть механизм сигнализации о смене MAC-адреса. Когда от CE маршрутизатора PE-ка получает Gratuitous ARP, то генерируется BGP Update, в котором содержится withdrawn сообщение с указанием старого MAC-адреса и анонс нового MAC-адреса.
Но помимо MAC-адреса маршрут MAC/IP Advertisement route может опционально содержать в себе и IP-адрес хоста. Добавим в наш EVPN роутинговый-интерфейс IRB и посмотрим какой маршрут появился:
bormoglotx@RZN-PE-1> show configuration interfaces irb.777 family inet { address 10.0.0.254/24; } mac 02:00:00:00:00:02; bormoglotx@RZN-PE-1> *2:62.0.0.1:1::777::02* show route table RZN-VPN-1.evpn.0 match-prefix RZN-VPN-1.evpn.0: 18 destinations, 18 routes (18 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 2:62.0.0.1:1::777::02:00:00:00:00:02/304 *[EVPN/170] 14:17:31 Indirect 2:62.0.0.1:1::777::02:00:00:00:00:02::10.0.0.254/304 *[EVPN/170] 14:17:31 Indirect
Появились два новых маршрута, причем первый это только MAC-адрес irb.777, а вот второй MAC+IP. Mac+IP анонс имеет вид ARP записи, все PE маршрутизаторы, участвующие в одном EVPN-домене, синхронизируют свои ARP записи, что позволяет уменьшить количество флуда широковещательных ARP запросов по сети провайдера.
Теперь посмотрим на маршрут внимательнее:
bormoglotx@RZN-PE-1> show route table RZN-VPN-1.evpn.0 match-prefix *2:62.0.0.1:1::777::02* detail RZN-VPN-1.evpn.0: 18 destinations, 18 routes (18 active, 0 holddown, 0 hidden) 2:62.0.0.1:1::777::02:00:00:00:00:02/304 (1 entry, 1 announced) *EVPN Preference: 170 Next hop type: Indirect Address: 0x940d804 Next-hop reference count: 7 Protocol next hop: 62.0.0.1 Indirect next hop: 0x0 - INH Session ID: 0x0 State: <Active Int Ext> Age: 14:21:34 Validation State: unverified Task: RZN-VPN-1-evpn Announcement bits (1): 1-BGP_RT_Background AS path: I Communities: evpn-default-gateway Route Label: 300144 ESI: 00:00:00:00:00:00:00:00:00:00
В данном маршруте появилось новое расширенное комьюнити evpn-default-gateway. Именно так помечаются маршруты, которые являются основным шлюзом для routing-instance. Данный маршрут будет генерироваться для каждого влана отдельно.
Почему генерируются два маршрута? Дело в том, что первый маршрут, в котором указан только MAC-адрес, используется исключительно для свитчинга в bringe-домене, а вот маршрут MAC+IP уже используется для маршрутизации и является по своей сути arp записью. Забегу чуточку вперед и напишу, что точно так же будут генерироваться маршруты до хостов при движении трафика в другие вланы или во внешнюю сеть (это мы рассмотрим далее при добавлении в схему еще одного влана).
Маршрут типа 1
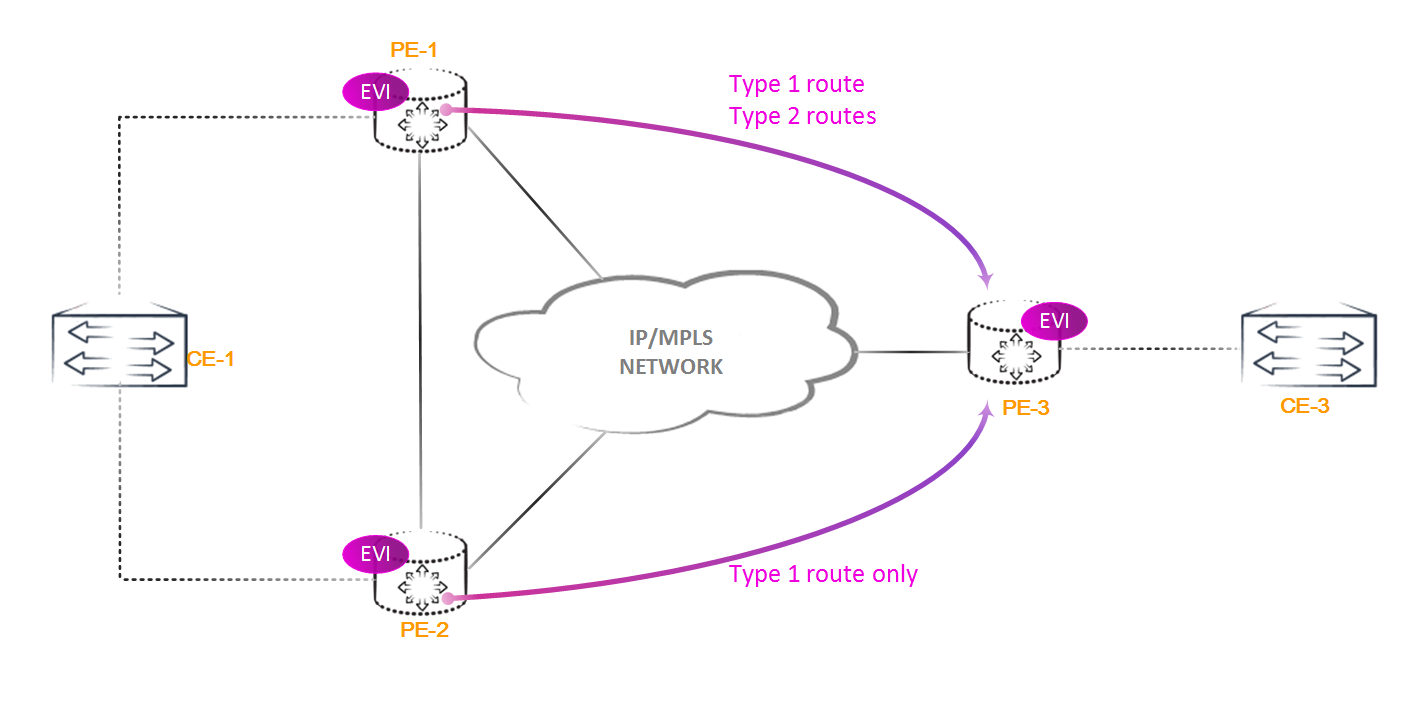
Пока что у нас без внимания остались маршруты типа 1 и типа 4. Эти маршруты используются для multihomed сайтов.
Примечание: ввиду слишком большого объема статьи глубоко погружаться в работу EVPN с multihomed сайтами мы не будем. Если кому-то будет интересно — пишите в комментарии — напишу по этой теме отдельную статью.
Маршрут типа 1 имеет следующий вид:

1:62.0.0.2:0::112233445566778899aa::0/304 *[BGP/170] 00:00:56, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.1 via ge-0/0/0.0, Push 299792
Данный маршрут не несет информации о MAC-адресах, но имеет очень широкое применение, такое как:
- Автоматический поиск PE маршрутизаторов, к которым подключен один и тот же CE-маршрутизатор
- Анонс ESI метки
- Анонс массовой отмены изученных MAC-адресов
- Анонс Aliasing метки
Маршрут типа 1 может анонсироваться per-EVI или per-ESI. Первый анонс используется при анонсировании Aliasing метки, второй — для возможности массовой отмены анонсированных MAC-адресов какого-либо ethernet сегмента.
Давайте остановимся на вышеописанных функция данного маршрута подробнее.
Автоматический поиск multihomed PE и ESI label
В отличии от VPLS, в EVPN включена функция автоматического обнаружения РЕ-маршрутизаторов, подключенных к одному и тому же СЕ-маршрутизатору (multihomed сайты). В терминах EVPN стык PE<->CE называется Ethernet Segment. Каждому сегменту назначается ESI (Ethernet Segment Identifier, число размером 80 бит записанное в 10 группах по 8 бит в группе). Для single-homed сайтов данный идентификатор не играет роли и поэтому назначается автоматически и равен 0. Но вот для multihomed сайтов данный идентификатор очень важен и должен быть уникальным для всего EVPN-домена (благо количество возможных комбинаций ESI очень велико и равно 2^80). ES, подключенные к одному и тому же CE-маршрутизатору, должны иметь один и тот же ESI. Два значения из всего диапазона зарезервированы, и их нельзя задать административно — это все нули (используется как идентификатор для не multihoming сегментов) и все F.
В представленном выше выводе магический набор букв и цифр :112233445566778899aa: есть не что иное, как ESI, сконфигурированный администратором сети на физическом интерфейсе:
bormoglotx@RZN-PE-2> show configuration interfaces ge-0/0/4 description "link to RZN-MULTI-SW-1"; flexible-vlan-tagging; encapsulation flexible-ethernet-services; esi { 11:22:33:44:55:66:77:88:99:aa; single-active; } mac 50:01:00:02:00:06; unit 111 { encapsulation vlan-bridge; vlan-id 111; family bridge; }
Данный маршрут, помимо ESI несет в себе очень важное значение, которое представлено в виде расширенного комьюнити: esi-label. Выглядит оно следующим образом:
bormoglotx@RZN-PE-2> show route table RZN-VPN-3.evpn.0 match-prefix *1:62* detail RZN-VPN-3.evpn.0: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden) 1:62.0.0.1:0::112233445566778899aa::0/304 (1 entry, 1 announced) *BGP Preference: 170/-101 Route Distinguisher: 62.0.0.1:0 Next hop type: Indirect Address: 0x95c0f28 Next-hop reference count: 20 Source: 62.0.0.255 Protocol next hop: 62.0.0.1 Indirect next hop: 0x2 no-forward INH Session ID: 0x0 State: <Secondary Active Int Ext> Local AS: 6262 Peer AS: 6262 Age: 2:50 Metric2: 1 Validation State: unverified Task: BGP_6262.62.0.0.255+179 Announcement bits (1): 0-RZN-VPN-3-evpn AS path: I (Originator) Cluster list: 62.0.0.255 Originator ID: 62.0.0.1 Communities: target:6262:111 esi-label:00049660(label 300640) <<<<<<community Import Accepted Localpref: 100 Router ID: 62.0.0.255 Primary Routing Table bgp.evpn.0
Так как данный маршрут имеет в своем составе нативное расширенное комьюнити, характерное для данного EVPN-домена, то все PE маршрутизаторы в evpn-домене импортируют данный маршрут в таблицу маршрутизации соответствующей EVPN instance:
bormoglotx@RZN-PE-3> show route table RZN-VPN-3.evpn.0 match-prefix *1:62* detail | match esi Communities: target:6262:111 esi-label:00049660(label 300640) Communities: target:6262:111 esi-label:00049680(label 300672)
Зачем оно нужно? Рассмотрим такую схему:
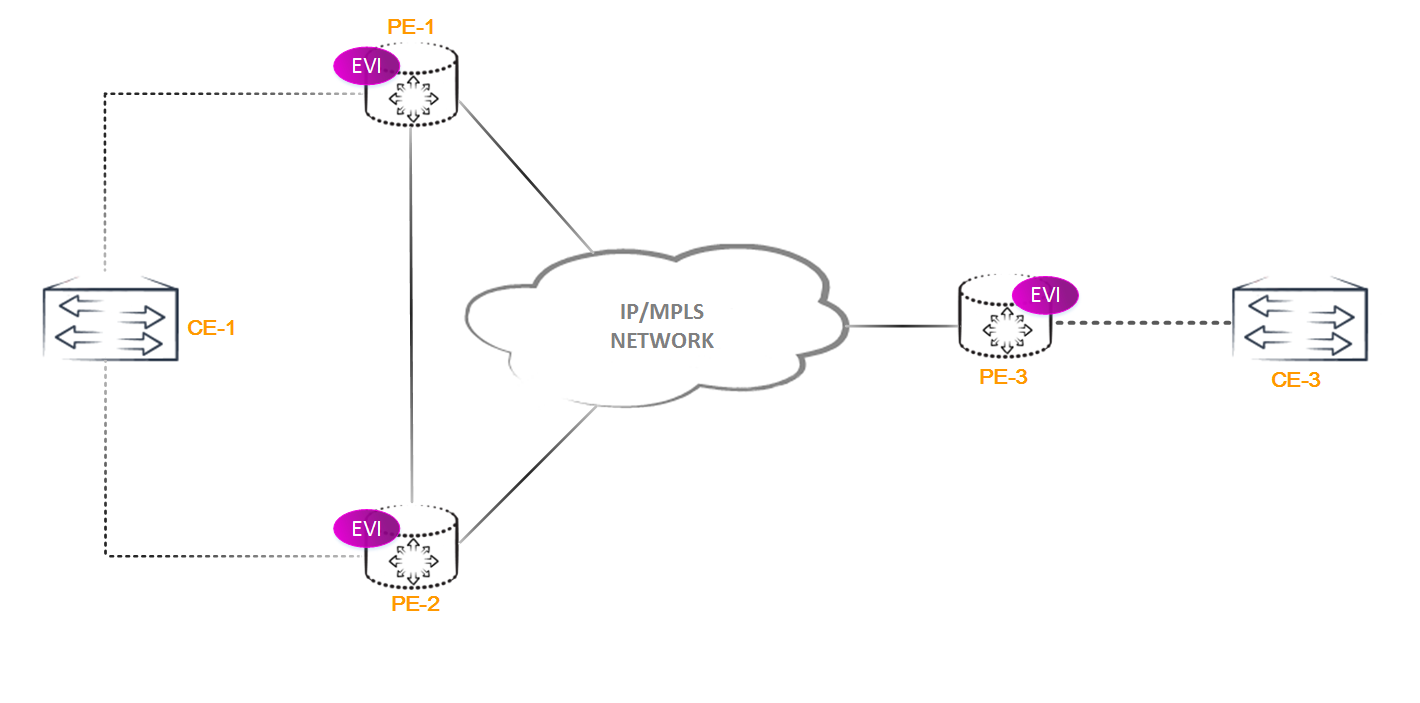
В данном сценарии мы имеем потенциальную L2 петлю, так как если BUM трафик от CE1 попадет на PE2, то будет отправлен всем остальным PE маршрутизаторам, включая и PE1. PE1 тоже имеет линк в сторону CE1, от которого и был получен BUM трафик. И если PE1 отправит пакет на CE1, то мы получаем петлю на 2 уровне, а как вы знаете, в L2 заголовке нет поля ttl. Ситуация, мягко говоря, будет неприятная. Как с этим бороться? В EVPN для данной цели используется автоматически выбор Designated Forwarder-а (DF). Как он выбирается мы рассмотрим позже, а пока поговорим о его назначении.
DF имеет исключительное право отправлять широковещательные кадры в сторону CE маршрутизатора, находящегося в ethernet сегменте, для которого данный PE маршрутизатор является DF. Все остальные non-DF маршрутизаторы BUM трафик в сторону CE маршрутизатора не отправляют.
У нас может быть два сценария: когда используется режим Single-Active и когда используется режим Active-Active (All-Active).
Как нетрудно догадаться, в Single-Active режиме у нас работает только одно плечо, второе находится в резерве. В случае падения основного плеча, трафик переходит на резервное. Возможно использовать одно плечо для передачи трафика в одном влане, а второе во втором, но сразу по обоим плечам в одном влане трафик идти не может (точнее не должен — если не так, то пишите в поддержку, видимо вы нашли баг, либо, что более вероятно, у инженера, который собирал схему, кривые руки).
В Active-Active или All-Active режиме работают все линки от CE к PE, для чего собирается MC-LAG. Принцип работы технологии MC-LAG в данной статье рассматриваться не будет: подразумевается, что читатель уже изучил данную тему.
В первом случае все просто — выбирается DF, и весь трафик, включая и BUM трафик, форвардит только он. При этом ESI label в анонсе отсутствует (во всяком случае на оборудовании Juniper ее нет), хотя согласно RFC даже при Single-Active режиме рекомендуется использовать данную метку, чтобы в случае ошибки в работе механизма выбора DF (когда оба PE маршрутизатора вдруг будут считать себя DF) не образовалась петля.
При нормальной работе механизма выбора DF одно плечо просто блокируется, а значит PE маршрутизатор не изучает по заблокированному линку MAC-адреса, следовательно и не анонсирует ничего на другие PE маршрутизаторы. Но, даже если каким то заковыристым путем на данный маршрутизатор прилетит BUM трафик, то он будет просто отброшен.

Во втором случае немного сложнее. Тут так же выбирается DF, который имеет право отправлять BUM трафик в сторону CE маршрутизатора — то есть проблемы с трафиком, идущим к CE маршрутизатору, нет. Проблемы могут появиться при передаче BUM трафика от CE маршрутизатора. Так как CE маршрутизатору абсолютно без разницы кто из PE маршрутизаторов DF (точнее сказать CE маршрутизатор думает, что просто подключен к другому коммутатору агрегированным интерфейсом), то возможна следующая ситуация. Предположим, что широковещательный пакет от CE1 прилетел на PE1, который не является DF. PE1 получает пакет и отправляет его всем остальным PE маршрутизаторам, включая и PE2. PE2, являясь DF маршрутизатором для данного сегмента, форвардит BUM трафик обратно на CE маршрутизатор. Да, получили петлю. Вот тут-то нам и пригодится ESI-label. Дело в том, что при отправке пакета на PE2, PE1 навешивает две метки: ESI-label (дно меток) и Inclusive Multicast label. PE2 получает пакет, снимает верхнюю метку и обнаруживает ESI-label, это говорит маршрутизатору о том, что флудить пакет в сторону CE1 не надо, так как трафик из этого сегмента и прилетел. Но зачем же тогда этот пакет вообще отправлять на PE2? Дело в том, что к PE2, помимо CE1, от которой и был получен данный трафик, могут быть подключены другие CE маршрутизаторы, которые могут быть заинтересованы в данном трафике.

Сокращения на схеме:
IM — Inclusive Multicast label
ESI — ESI label
TL — Transport MPLS label
Примечание: PE1 и PE2 непосредственно соединены, поэтому транспортная метка при отправке трафика от PE1 на PE2 не навешивается. Если бы между ними было бы больше одного хопа, то мы бы получили стек из трех меток.
MAC Mass Withdrawal
Эта функция предназначена для тех случаев, когда у нас отвалится один из линков, которыми подключен multihomed CE-маршрутизатор. Так как в случае с Active-Active режимом трафик от CE маршрутизатора балансируется, то и MAC-адреса будут изучены ит обоих PE маршрутизаторов. Если у нас упал один из линков, то PE маршрутизатор должен отменить все маршруты данного сегмента, которые им были отправлены. Представьте, что их 1000 или более, тогда мы получим высокую утилизацию процессора резким всплеском BGP сообщений, что может плохо сказаться на всем control-plane. Да и по времени обработать большое количество Withdrawn сообщений не так-то просто. Поэтому PE маршрутизатор отравляет Withdrawn сообщение об отмене ранее отправленного маршрута типа 1, сгенерированный per-ESI (об этом чуть позже). Получив данное сообщение, другие PE маршрутизаторы могут или очистить все соответствия MAC-label, ассоциированные с данным сегментом (ES), или, если в данном сегменте есть другой маршрутизатор, который способен форвардить трафик, то использовать маршруты, полученные от него (то есть по сути сменить protocol next-hop). Если “умер” последний маршрутизатор в данном сегменте, то очистить таблицу MAC-адресов, связанную с данным сегментом.
Как вы понимаете, это необходимо для быстрого переключения с резерва на бекап.
Aliasing label
И снова данная функция касается multihoming CE. Трафик от CE маршрутизатора в All-Active режиме должен балансироваться между всеми линками. Так как балансировка производится по какому-то алгоритму, известному только самому CE маршрутизатору и его разработчику, то возможна ситуация, когда multihoming CE маршрутизатор будет отправлять весь исходящий трафик только через один интерфейс. В результате, маршруты типа 2 будут отправляться только с одного PE маршрутизатора, предположим что только с PE1:
Так как другие маршрутизаторы не будут знать, как добраться до указанного сегмента через PE2, то через него трафик не пойдет, что вызовет простой одного из плеч между PE и CE маршрутизаторами. Для этого каждый PE маршрутизатор анонсирует анонсирует Aliasing метку для своего ethernet сегмента. Так как остальные PE маршрутизаторы получают маршруты типа 1, то они видят, что PE1 и PE2 имеют линки в одном и том же ES и работают в All-Active режиме. Используя полученную Aliasing метку, другие PE маршрутизаторы могу отправлять пакеты на CE маршрутизатор и через PE1 и через PE2, навещивая на пакет, который пойдет через PE2 вместо VPN метки — Aliasing-метку, полученную в от PE2 в маршруте типа 1, сгенерированного per-EVI.

Сокращения на схеме:
AL — Aliasing label
EVPN — EVPN label
TL — Transport MPLS label
В маршрутах типа 1 есть флаг, который отвечает за информирование других PE маршрутизаторов о том, в каком режиме работает данный PE маршрутизатор в данном ethernet сегменте — Single-Active или All-Active. Данный флаг находится находится в составе расширенного комьюнити, добавляемого к анонсу маршрута типа 1. Если флаг поднят, то маршрутизатор работает в режиме Single-Active (флаг так и называется Single-Active flag), если флаг не поднят — то маршрутизатор работает в All-Active режиме. Ниже пример маршрута, в котором поднят флаг и отсутствует метка:
bormoglotx@RZN-PE-1> show route advertising-protocol bgp 62.0.0.255 table __default_evpn__.evpn.0 detail match-prefix *112233445566778899aa::* __default_evpn__.evpn.0: 9 destinations, 9 routes (9 active, 0 holddown, 0 hidden) * 1:62.0.0.1:0::112233445566778899aa::0/304 (1 entry, 1 announced) BGP group RR-NODES type Internal Route Distinguisher: 62.0.0.1:0 Nexthop: Self Flags: Nexthop Change Localpref: 100 AS path: [6262] I Communities: target:6262:111 esi-label:100000(label 0)
А вот маршрут уже с меткой и не поднятым Single-Active флагом:
bormoglotx@RZN-PE-1> show route advertising-protocol bgp 62.0.0.255 table __default_evpn__.evpn.0 detail match-prefix *62000000000000000001::* __default_evpn__.evpn.0: 9 destinations, 9 routes (9 active, 0 holddown, 0 hidden) * 1:62.0.0.1:0::62000000000000000001::0/304 (1 entry, 1 announced) BGP group RR-NODES type Internal Route Distinguisher: 62.0.0.1:0 Nexthop: Self Flags: Nexthop Change Localpref: 100 AS path: [6262] I Communities: target:100:100 esi-label:000493a0(label 299936)
Маршрут типа 4
Теперь разберем маршрут типа 4. Этот маршрут нужен для выбора DF, о назначении которого я писал ранее. Данный маршрут выглядит следующим образом:

bormoglotx@RZN-PE-2> show route table bgp.evpn.0 match-prefix *4:6* bgp.evpn.0: 11 destinations, 11 routes (11 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 4:62.0.0.1:0::112233445566778899aa:62.0.0.1/304 *[BGP/170] 01:07:57, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.3 via ge-0/0/0.0, Push 299808
Примечательно, что данный маршрут не несет комьюнити, которое сконфигурено на экспорт из routing-instance:
bormoglotx@RZN-PE-2> show route table bgp.evpn.0 match-prefix *4:6* detail bgp.evpn.0: 11 destinations, 11 routes (11 active, 0 holddown, 0 hidden) 4:62.0.0.1:0::112233445566778899aa:62.0.0.1/304 (1 entry, 0 announced) *BGP Preference: 170/-101 Route Distinguisher: 62.0.0.1:0 Next hop type: Indirect Address: 0x95c1954 Next-hop reference count: 14 Source: 62.0.0.255 Protocol next hop: 62.0.0.1 Indirect next hop: 0x2 no-forward INH Session ID: 0x0 State: <Active Int Ext> Local AS: 6262 Peer AS: 6262 Age: 1:07:59 Metric2: 1 Validation State: unverified Task: BGP_6262.62.0.0.255+51796 AS path: I (Originator) Cluster list: 62.0.0.255 Originator ID: 62.0.0.1 Communities: es-import-target:33-44-55-66-77-88 Import Accepted Localpref: 100 Router ID: 62.0.0.255 Secondary Tables: __default_evpn__.evpn.0
Данные маршруты используют новое комьюнити: es-import-target:XX-XX-XX-XX-XX-XX. Само комьюнити генерируется из ESI. Для этого из идентификатора берутся 48 бит, как это показано ниже:
ESI:
11:22:33:44:55:66:77:88:99:aa
Сгенерированное коммьюнити:
Communities: es-import-target:33-44-55-66-77-88
Только PE маршрутизаторы, имеющие одинаковые ESI (точнее одинаковые биты с 16 по 64 в идентификаторе), импортируют данный маршрут. Как видите, в анонсе нет RT, указанного на импорт или экспорт в routing instance. То есть маршруты типа 4 не видны в таблице маршрутизации самой EVPN. Их можно посмотреть только в таблицах bgp.evpn.0 и __default_evpn__.evpn.0.
Если у другого PE маршрутизатора будет ESI, например aaaa334455667788aaaa, то, как не трудно догадаться, их коммьюнити будет одинаково, а значит маршрут будет тоже импортирован. Но не стоит паниковать, все уже украдено до нас: в теле самого маршрута указан полный идентификатор ESI и данный маршрут будет импортирован, но проигнорирован. Как и RT, es-import-target предназначен только для фильтрации маршрутов. Ниже представлен сам маршрут типа 4 и его комьюнити:
bormoglotx@RZN-PE-1> show route table bgp.evpn.0 match-prefix *4:62* detail | match "comm|\/304" 4:62.0.0.2:0::112233445566778899aa:62.0.0.2/304 (1 entry, 0 announced) Communities: es-import-target:33-44-55-66-77-88
Интересным случаем является вот такой конфиг:
bormoglotx@RZN-PE-1> show configuration interfaces ae1 | match esi | display set set interfaces ae1 esi 62:00:00:00:00:00:00:00:00:01 set interfaces ae1 esi all-active
Думаю, вы уже догадались, что мы получаем в анонсе расширенное комьюнити, состоящее из всех нулей:
bormoglotx@RZN-PE-1> show route advertising-protocol bgp 62.0.0.255 table __default_evpn__.evpn.0 detail match-prefix *62000000000000000001:6* __default_evpn__.evpn.0: 9 destinations, 9 routes (9 active, 0 holddown, 0 hidden) * 4:62.0.0.1:0::62000000000000000001:62.0.0.1/304 (1 entry, 1 announced) BGP group RR-NODES type Internal Route Distinguisher: 62.0.0.1:0 Nexthop: Self Flags: Nexthop Change Localpref: 100 AS path: [6262] I Communities: es-import-target:0-0-0-0-0-0
Не стоит полагать, что из за этого все сломается. Даже с таким комьюнити все будет работать, но если у вас в сети будут, например, ESI в диапазоне хх: хх:00:00:00:00:00:00:00:01-хх: хх:00:00:00:00:00:00:99:99, то у всех маршрутов типа 4 будут одинаковые комьюнити, а значит PE маршрутизаторы будут принимать и устанавливать в таблицы маршрутизации все маршруты типа 4, даже если они им не нужны. Но думаю, что об это не стоит париться, плюс/минус 100 маршрутов погоды не сделают (почему не сделают — поймете, когда дочитаете статью до конца).
Не знаю, заметил ли читатель, но в маршрутах типа 1 и 4 RD выглядит несколько странно. Например, маршрут типа 2 от PE2:
2:62.0.0.2:1::777::aa:bb:cc:00:07:00/304 *[BGP/170] 00:00:18, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.1 via ge-0/0/0.0, Push 299792
А вот маршрут типа 1 с того же PE2:
1:62.0.0.2:0::112233445566778899aa::0/304 *[BGP/170] 00:00:56, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.1 via ge-0/0/0.0, Push 299792
От PE2 маршурт типа 1 имеет RD 62.0.0.2:0, хотя от этого же PE2 маршруты типа 2 или 3 прилетают с RD 62.0.0.2:1, который и сконфигурен в routing instance. Что происходит с RD? Для проверки данного явления создадим два routing instance с типом EVPN и назначим им совершенно разные RD:
bormoglotx@RZN-PE-1> show configuration routing-instances RZN-VPN-3 | match route route-distinguisher 62.0.0.1:3; bormoglotx@RZN-PE-1> show configuration routing-instances RZN-VPN-4 | match route route-distinguisher 9999:99;
Теперь посмотрим, с каким RD будет анонсироваться маршрут типа 1:
bormoglotx@RZN-PE-1> show route advertising-protocol bgp 62.0.0.255 | match "1:6" 1:62.0.0.1:0::112233445566778899aa::0/304 1:62.0.0.1:0::aaaa334455667788aaaa::0/304
RD в маршруте не соответствует сконфигуренному ни на RZN-VPN-3, ни на RZN-VPN-4. Откуда же это RD берется? JunOS генерирует его автоматически из router-id или loopback адреса. Причем первое значение имеет приоритет. Например, сейчас имеем router-id:
bormoglotx@RZN-PE-1> show configuration routing-options router-id router-id 62.0.0.1;
И это значение берется как первая часть RD, а вторая выставляется в нашем случае в ноль. Давайте помянем router id:
bormoglotx@RZN-PE-1> show configuration routing-options router-id router-id 62.62.62.62;
Смотрим, какие теперь отдаются маршруты:
bormoglotx@RZN-PE-1> show route advertising-protocol bgp 62.0.0.255 | match "1:6" 1:62.62.62.62:0::112233445566778899aa::0/304 1:62.62.62.62:0::aaaa334455667788aaaa::0/304
Как видите JunOS сам сгенерировал RD. Что будет если мы не укажем router-id? Давайте проверим. Но усложним задачу, навесив на лупбек еще пару адресов:
bormoglotx@RZN-PE-1> show configuration interfaces lo0 description "BGP & MPLS router-id"; unit 0 { family inet { address 10.1.1.1/32; address 62.0.0.1/32; address 62.62.62.62/32; } family iso { address 49.0000.0620.0000.0001.00;
Смотрим теперь:
bormoglotx@RZN-PE-1> show route advertising-protocol bgp 62.0.0.255 | match " 1:(1|6)" 1:10.1.1.1:0::112233445566778899aa::0/304 1:10.1.1.1:0::aaaa334455667788aaaa::0/304
JunOS выбрал наименьший IP-адрес лупбека и использовал его как router-id. Это происходит потому, что данный маршрут типа 1 сгенеирирован per-ESI. Если маршрут будет генерироваться per-EVI, то у него будет нативный RD инстанса, из которого данный маршрут анонсируется. А вот маршрут типа 4 всегда будет иметь RD, уникальный на маршрутизатор, так как он всегда генерируется per-ESI.
Генерация маршрута per-ESI имеет некоторую особенность. Так как идентификатор ESI конфигурируется на физическом интерфейсе, то если у нас будет например 10 логических юнитов (можно сказать вланов) на данном интерфейсе и все в разных EVPN-инстансах, то мы получим, что в разных инстансах будет сгенерирован один и тот же маршрут типа 1. Зачем генерировать 10 одинаковых маршрутов (разница в них будет только в RT), если можно сгенерировать только один и навесить на него RT-ки всех заинтересованных в данном маршруте инстансов?
Давайте посмотрим как это работает на примере. Вот конфигурация ESI на физическом интерфейсе:
bormoglotx@RZN-PE-1> show configuration interfaces ge-0/0/2 | match esi | display set set interfaces ge-0/0/2 esi 00:00:00:00:00:00:00:00:00:07 set interfaces ge-0/0/2 esi single-active
Данный интерфейс используется двумя инстансами с типом evpn:
bormoglotx@RZN-PE-1> show configuration routing-instances | display set | match ge-0/0/2. set routing-instances RZN-VPN-1 interface ge-0/0/2.0 set routing-instances eVPN-test interface ge-0/0/2.200
Посмотрим, какие RT соответствуют данным инстансам (я удалил политики и прописал RT с помощью vrf-target для наглядности):
bormoglotx@RZN-PE-1> show configuration routing-instances RZN-VPN-1 | match target vrf-target target:62:1; bormoglotx@RZN-PE-1> show configuration routing-instances eVPN-test | match target vrf-target target:62:2;
А теперь посмотрим маршрут типа 1, анонсируемый на рефлектор:
bormoglotx@RZN-PE-1> show route advertising-protocol bgp 62.0.0.255 table __default_evpn__.evpn.0 match-prefix *1:6*:07:* detail __default_evpn__.evpn.0: 8 destinations, 8 routes (8 active, 0 holddown, 0 hidden) * 1:62.0.0.1:0::07::0/304 (1 entry, 1 announced) BGP group RR-NODES type Internal Route Distinguisher: 62.0.0.1:0 Nexthop: Self Flags: Nexthop Change Localpref: 100 AS path: [6262] I Communities: target:62:1 target:62:2 esi-label:100000(label 0)
Как видите, у маршрута две RT-ки: target:62:1, которая соответствует RZN-VPN-1 и target:62:2, соответствующая eVPN-test. Эта функция уменьшает время сходимости. Если данный линк отвалится, то он отвалится у всех инстансов, к которым он прикреплен. В нашем случае вместо 2-x BGP Withdrawn сообщений, улетит только одно, но с двумя RT.
Примечание: маршруты типа 1 и 4, если будет желание у читателя будем рассматривать отдельно, в отдельной статье, посвященной EVPN multihoming.
Механизм выбора DF
Механизм выбора DF позволяет выбрать разный DF для разных вланов, тем самым можно, например, добиться балансировки трафика между различными bridge-доменами — трафик разных вланов будет идти по разным линкам в сторону CE маршрутизатора внутри одного EVPN-instance.
Маршрутизатор отправляет анонс маршрута типа 4 с указанием ESI и соответствующим комьюнити и запускает таймер выбора DF. По умолчанию данный таймер установлен в 3 секунды. Его можно изменить, но он должен быть одинаков на всех PE маршрутизаторах сегмента — иначе алгоритм может отработать некорректно.
По истечению таймера все PE маршрутизаторы, участвующие в выборе DF, составляют полный список всех PE маршрутизаторов сегмента начиная с самого маленького адреса. Каждому из PE маршрутизаторов в списке присваивается номер (i), начиная с нуля.
После этого высчитывается номер DF по формуле V mod N = i, где V — номер влана, а N количество PE маршрутизаторов в сегменте. Тот PE маршрутизатор, номер которого будет результатом вычисления и становится DF данного сегмента в данном влане.
Попробуем высчитать DF для влана 777 если у нас будет только 2 PE маршрутизтора с адресами 62.0.0.1 и 62.0.0.2.
Оба PE маршрутизатора составят такой список
62.0.0.1 i=0 62.0.0.2 i=1
Так как влан у нас 777, то V=777, а N=2 (так как у нас всего два маршрутизатора в сегменте). Теперь считаем 777 mod 2 = 1. Значит DF у нас 62.0.0.2.
Теперь увеличим число PE маршрутизаторов в сегменте до 3 и еще раз посчитаем.
62.0.0.1 i=0 62.0.0.2 i=1 62.0.0.3 i=2
777 mod 3 = 0, значит DF 62.0.0.1.
Как нетрудно догадаться, если у нас в сегменте будет два влана например 777 и 778 и два PE маршрутизатора, то в 777 влане DF станет PE1, а в 778 PE2.
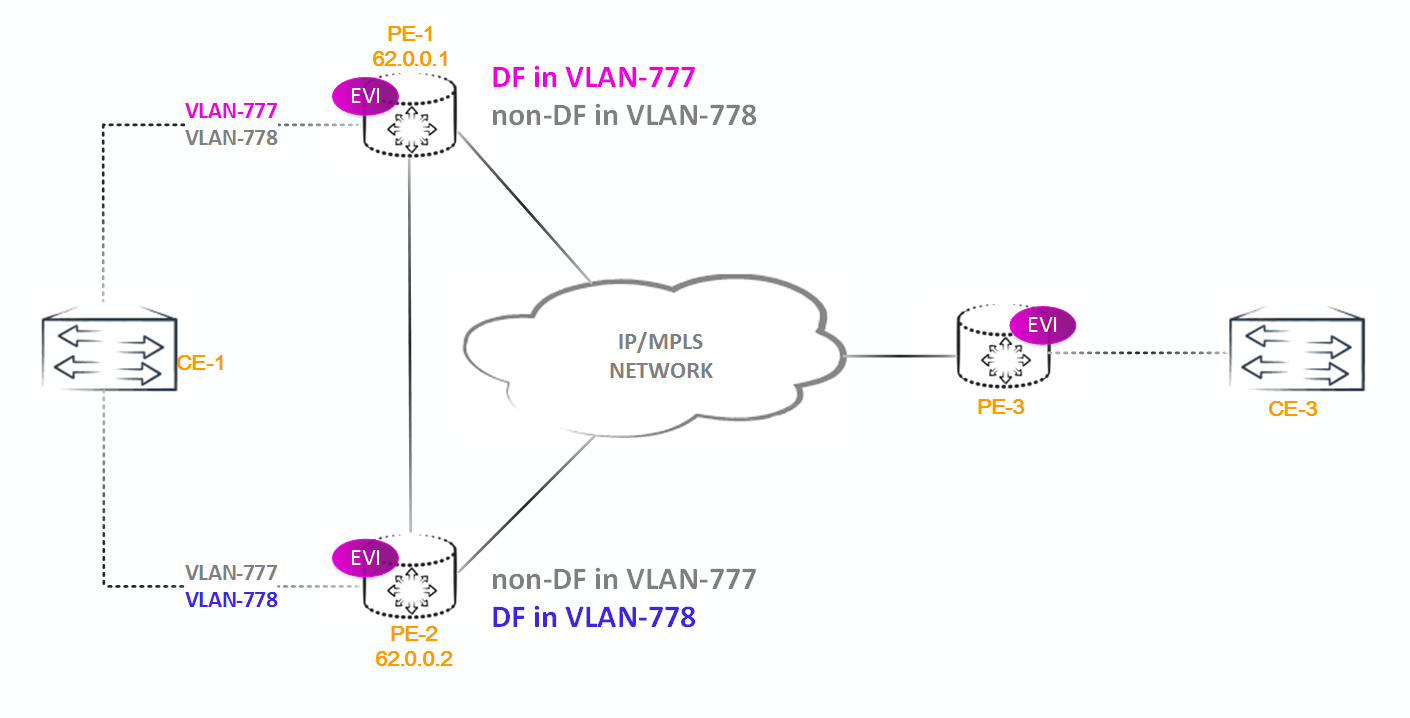
Для примера посмотрим, кто в указанной выше схеме будет DF при vlan-id 777:
bormoglotx@RZN-PE-2# run show evpn instance RZN-VPN-3 extensive | match "vlan|forward" VLAN ID: 777 Designated forwarder: 62.0.0.2 Backup forwarder: 62.0.0.1
Теперь поменяем номер влана на 778 и посмотрим, изменится ли DF:
bormoglotx@RZN-PE-2# run show evpn instance RZN-VPN-3 extensive | match "vlan|forward" VLAN ID: 778 Designated forwarder: 62.0.0.1 Backup forwarder: 62.0.0.2
Как видите механизм работает.
L3-функционал в evpn
В данный момент мы разобрались, какие существуют маршруты в EVPN и как будет передаваться трафик внутри одного bridge-домена. Это конечно хорошо, но ведь данная технология предназначена для соединения датацентров, а в них, как правило, не один влан, как у обычного клиента, и логично, что между ними (вланами) должен ходить трафик. Да и связь датацентра с внешним миром тоже необходима. Сейчас мы будем разбирать, как же работает маршрутизация пакетов между разными вланами (bridge-доменами).
IRB synchronization
Но перед тем, как нырнуть с головой в странный но интересный мир интегрированной в EVPN маршрутизации, осветим очень важный пункт — синхронизация дефолтных шлюзов. Мы ведь до сих пор не знаем, зачем же к анонсам IRB-интерфейсов добавляется default-gateway community. Не для красоты же. Думаю, что исходя из названия данного пункта, вы уже догадались что это необходимо для синхронизации дефолтных шлюзов. Что такое синхронизация, как она происходит и зачем нужна? Давайте разбираться.
Для начала посмотрим все MAC-адреса на PE1,2 и 3, которые навешены на их IRB-интерфейсы. По порядку, PE1:
bormoglotx@RZN-PE-1> show interfaces irb.777 | match mac MAC: 02:00:00:00:07:77 bormoglotx@RZN-PE-1> show interfaces irb.1777 | match mac MAC: 02:00:00:00:17:77
На PE1 mac адреса irb интрефейсов сконфигурированы вручную. Теперь перейдем к PE2:
bormoglotx@RZN-PE-2> show interfaces irb.777 | match mac MAC: 02:00:00:02:07:77 bormoglotx@RZN-PE-2> show interfaces irb.1777 | match mac MAC: 02:00:00:02:17:77
И тут я позволил себе самостоятельно назначить адреса на IRB-интерфейсы. Ну и посмотрим на PE3:
bormoglotx@RZN-PE-3> show interfaces irb | match curr Current address: 00:05:86:71:96:f0, Hardware address: 00:05:86:71:96:f0
Тут MAC пострашнее, так как его я оставил таким, каким он зашит в оборудование.
Все PE маршрутизаторы анонсируют MAC+IP маршрут до своего или своих дефолтных шлюзов (irb.777 и irb.1777). Когда PE маршрутизатор получает маршрут MAC+IP, помеченный default-gateway community, то он начинает воспринимать полученный MAC-адрес удаленного IRB-интерфейса, как свой собственный адрес. Ведь если есть интерфейсы, на которых несколько IP-адресов и один MAC, то почему не может быть обратного — один IP и несколько MAC-адресов? Синхронизация дефолтных шлюзов бывает двух видов: автоматическая и ручная. Автоматическую синхронизацию мы сейчас рассмотрим, к ручной вернемся чуть позже.
Посмотреть какие адреса используются PE маршрутизатором можно следующей командой (проверим на PE1):
bormoglotx@RZN-PE-1> show bridge evpn peer-gateway-macs Routing instance : RZN-VPN-1 Bridging domain : VLAN-1777, VLAN : 1777 Installed GW MAC addresses: 02:00:00:02:17:77 Bridging domain : VLAN-777, VLAN : 777 Installed GW MAC addresses: 00:05:86:71:96:f0 02:00:00:02:07:77
На PE1 два bridge-домена, для каждого каждого из которых синхронизация дефолтных шлюзов производится индивидуально. В отличии от PE1, на PE3 только один bridge-домен и один IRB-интерфейс. Соответственно синхронизация производится только для bridge-домена VLAN-777:
bormoglotx@RZN-PE-3> show evpn peer-gateway-macs Routing instance : RZN-VPN-1 Bridging domain : __RZN-VPN-1__, VLAN : 777 Installed GW MAC addresses: 02:00:00:00:07:77 02:00:00:02:07:77
В итоге получается следующая картина — irb.777 на PE1 должен отзываться на три MAC-адреса:
- 00:05:86:71:96:f0 (PE3)
- 02:00:00:02:07:77 (PE2)
- 02:00:00:00:07:77 (native PE1)
И, естественно, мы сейчас проверим, что IRB-интерфейс будет отвечать на пакеты, адресованные не на его собственный MAC. Сделаем это по-деревенски — просто пропишем статическую arp запись на CE маршрутизаторе на нужный нам MAC-адрес. Так как CE1-1 подключен к PE1 в bridge-домен VLAN-777, то при резолве MAC-адреса irb.777 он получает нативный MAC-адрес irb.777- 02:00:00:00:07:77. Мы же создадим на CE1-1 статическую arp запись, которая будет указывать, что MAC-адрес irb.777 на PE1 не 02:00:00:00:07:77, а 02:00:00:02:07:77 (который в действительности принадлежит irb.777 на PE2):
RZN-CE1-SW1#sh start | i arp arp 10.0.0.254 0200.0002.0777 ARPA RZN-CE1-SW1#show arp | i 10.0.0.254 Internet 10.0.0.254 - 0200.0002.0777 ARPA
Логично предположить, что трафик пойдет на PE2, так как указанный на CE1-1 MAC-адрес соответствует irb.777 на PE2. Для того, чтобы проверить куда же пойдет трафик, навесим на IRB-интерфейсы PE-шек такие фильтры:
[edit] bormoglotx@RZN-PE-2# show | compare [edit interfaces irb unit 777 family inet] + filter { + input irb777-counter; + } [edit interfaces IRB unit 1777 family inet] + filter { + input irb1777-counter; + } [edit] + firewall { + family inet { + filter irb777-counter { + term 1 { + then { + count irb777; + accept; + } + } + } + filter irb1777-counter { + term 1 { + then { + count irb1777; + accept; + } + } + } + } + }
Как вы можете заметить, фильтры просто считают, что попало на IRB-интерфейс и пропускают весь трафик. В данный момент времени и на PE1 и на PE2 счетчики по нулям.
На PE1:
bormoglotx@RZN-PE-1> show firewall filter irb777-counter counter irb777 Filter: irb777-counter Counters: Name Bytes Packets irb777 0 0
На PE2:
bormoglotx@RZN-PE-2> show firewall filter irb777-counter counter irb777 Filter: irb777-counter Counters: Name Bytes Packets irb777 0 0
Итак, запустим 33 icmp запроса до 10.0.0.254 с CE1-1 (почему 33? Чтобы никто не догадался!):
RZN-CE1-SW1#ping 10.0.0.254 repeat 33 Type escape sequence to abort. Sending 33, 100-byte ICMP Echos to 10.0.0.254, timeout is 2 seconds: !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Success rate is 100 percent (33/33), round-trip min/avg/max = 1/2/6 ms
Как вы помните, CE1-1 считает, что MAC-адрес шлюза по умолчанию не локальный мак irb.777 PE1, а MAC irb.777 PE2, это очень важно.
Смотрим что у нас с счетчиком на PE1:
bormoglotx@RZN-PE-1> show firewall filter irb777-counter counter irb777 Filter: irb777-counter Counters: Name Bytes Packets irb777 3300 33
Опа, все 33 пакета были приняты локальным IRB-интерфейсом. Давайте посмотрим, что у нас творится со счетчиком на PE2:
bormoglotx@RZN-PE-2> show firewall filter irb777-counter counter irb777 Filter: irb777-counter Counters: Name Bytes Packets irb777 0 0
Все по нулям. Трафик туда просто не отправлялся и обрабатывался локальным IRB-интерфейсом PE1.
Приведу пару скринов из Wireshark-а. Вот пакет от CE1-1 к PE1:
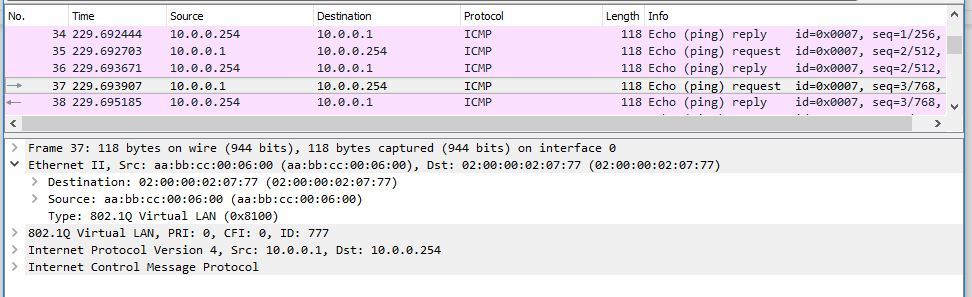
Как destination указан не MAC локального интерфейса irb.777 на PE1, а MAC-адрес irb.777 PE2. Но вот что примечательно: посмотрим, с какого адреса прилетает ответ от PE1 на CE1-1:
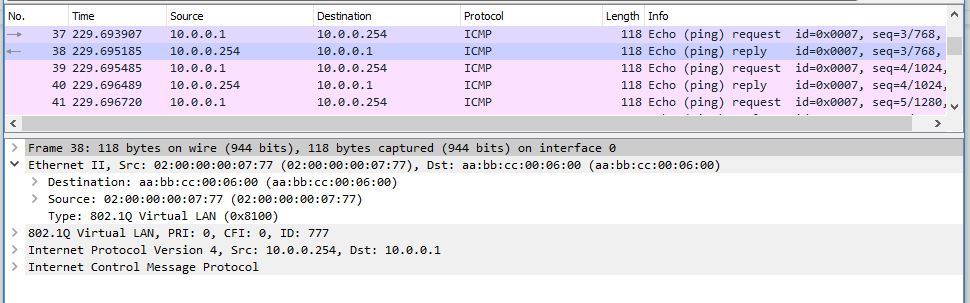
Ответ все таки PE1 шлет с нативного MAC-адреса irb.777. То есть, как вы понимаете, irb.777 только принимает пакеты, адресованные на MAC-адреса других интерфейсов irb.777 (PE2 и PE3), но как сорс адрес при отправке какого-либо пакета чужие MAC-адреса PE1 не использует. Это очень важно, так как, например, при резолве адреса дефолтного шлюза, IRB-интерфейс будет отвечать и указывать только свой нативный MAC-адрес.
Для чистоты эксперимента укажем CE1-1, что теперь MAC-адрес irb.777 равен MAC-адресу интерфейса irb.777 на PE3:
RZN-CE1-SW1#sh start | i arp arp 10.0.0.254 0005.8671.96f0 ARPA RZN-CE1-SW1#show arp | i 10.0.0.254 Internet 10.0.0.254 - 0005.8671.96f0 ARPA
Естественно, на irb.777 PE3 я также навесил данный фильтр. Запускаем пинг и проверяем:
RZN-CE1-SW1#ping 10.0.0.254 repeat 27 Type escape sequence to abort. Sending 27, 100-byte ICMP Echos to 10.0.0.254, timeout is 2 seconds: !!!!!!!!!!!!!!!!!!!!!!!!!!! Success rate is 100 percent (27/27), round-trip min/avg/max = 1/2/5 ms
Заглянем в WIreshark, чтобы удостовериться, что пакет с CE был отправлен с необходимым нам destination MAC-адресом:
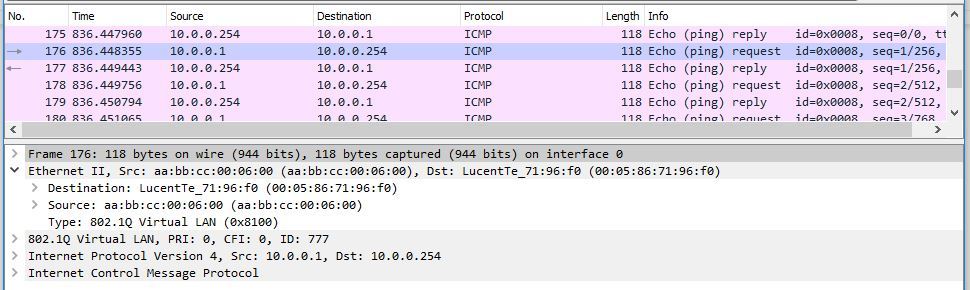
Смотрим счетчик на PE1:
bormoglotx@RZN-PE-1> show firewall filter irb777-counter counter irb777 Filter: irb777-counter Counters: Name Bytes Packets irb777 6000 60
irb.777 на PE1 обработал еще 27 пакетов, в то время, как на PE3 счетчик так и стоит на нуле:
bormoglotx@RZN-PE-3> show firewall filter irb777-couter counter irb777 Filter: irb777-couter Counters: Name Bytes Packets irb777 0 0
Это мы рассмотрели механизм автоматической синхронизации. Теперь перейдем к ручной синхронизации.
Вообще ручная синхронизация — это просто отключение автоматической синхронизации, вследствие того, что она просто не нужна. Почему? Мы сейчас конфигурили на всех PE-ках одинаковые IP-адреса на IRB-интерфейсах, но разные MAC-и. Второй способ настройки IRB-интерфейсов в EVPN (он же и рекомендованный) — одинаковые IP и MAC-адреса на всех IRB-интерфейсах одного и того же bridge-домена. При таком раскладе IRB-интерфейсы уже синхронизированы, так как везде одинаковые MAC. Поэтому можно дать команду default-gateway do-not-advertise и тем самым запретить генерацию маршрутов MAC+IP для IRB-интерфейсов.
Большим плюсом синхронизации дефолтных шлюзов является то, что это позволяет нам перемещать виртуальные машины между датацентрами без перерыва сервиса (при выполнении определенных условий, таких как, задержка менее 100мс между точками А (откуда перемещается машина) и Z (куда перемещается машина) и т д). После перемещения виртуальной машины она может продолжать отправлять пакеты во внешнюю сеть на адрес дефолтного шлюза, который находится в ее arp — то есть даже очищать arp кэш нам не придется. Естественно, будет сгенерирован новый BGP Update о том, что теперь данный MAC в другом месте. Вообще по теме VM Mobility в EVPN необходимо писать отдельную немаленькую статью и, поэтому, освещать её сейчас мы не будем.
Надеюсь, что все вышесказанное отложилось в памяти, так как без этого не будет понятен механизм работы L3 интерфейсов в EVPN. Теперь перейдем непосредственно к передаче пакетов между bridge-доменами.
Маршрутизация пакетов между bridge-доменами
Берем за основу то, что внутри одного bridge-домена пакеты коммутируются, а между разными bridge-доменами (или при выходе во внешнюю сеть) маршрутизируются. Чтобы трафик мог маршрутизироваться, нам надо добавить в наши instance роутинговые интерфейсы. В JunOS роутинговым интерфейсом является IRB (Integrated Routing and Bridging). Данный интерфейс не является тегированным, и с попадающего на него трафика снимается vlan тег. Как и обычный интерфейс на JunOS, IRB имеет юниты. Номер юнита в IRB-интерфейсе (как, собственно, и номера юнитов на физических интерфейсах) не значит, что этот интерфейс относится к какому-то определенному влану. Например, интерфейс irb.777 не обязательно должен относиться к влану 777. Но всё же удобнее читать конфигурационные файлы, когда номер влана и номер IRB юнита в одном bridge-домене одинаковы.
Для тестирования будем использовать ту же лабу, что и до этого, но добавим в неё роутинговые интерфейсы и пару CE маршрутизаторов, как это указано на схеме:

Для простоты в статье я не буду указывать хостнеймы, как они указаны на схеме, а буду использовать сокращения:
RZN-CE1-SW1 ⇒ CE1-1
RZN-CE1-SW2 ⇒ CE1-2
RZN-CE2-SW1 ⇒ CE2-1
RZN-CE2-SW2 ⇒ CE2-2
RZN-CE2-SW1 ⇒ CE3
Схема на первый взгляд имеет, мягко говоря, странный вид — на всех PE маршрутизаторах одинаковые IRB-интерфейсы. Думаю, что у вас должны возникнуть как минимум два вопроса — как это работает и зачем это нужно. Давайте попробуем ответить на эти вопросы.
Итак, поехали. Для начала вспомним как работает основной (или дефолтный, кому как нравится) шлюз в уже нами изученном VPLS. У нас есть какой-то PE маршрутизатор, на котором мы создаем IRB-интерфейс. Этот же IRB-интерфейс мы добавляем в какой-нибудь VRF или выпускаем в GRT, если есть такая необходимость. Возможно, что у нас таких маршрутизаторов более одного, и мы используем vrrp для резервирования основного шлюза, но мастером все равно будет кто-то один. То есть в VPLS у нас есть только один выход во внешнюю сеть, расположенный на каком-то PE маршрутизаторе, входящем в VPLS-домен. Весь трафик, направленный наружу, со всех остальных PE маршрутизаторов будет идти через данную PE-ку, так как она является единственным выходом во внешнюю сеть (это, если не применять костыли в виде намеренно сломанного vrrp). Минусы данной схемы очевидны — PE-ке, на которой будет находится дефолтный шлюз, придется переваривать весь исходящий трафик VPLS-домена, направленный во внешнюю сеть и весь входящий в VPLS домен трафик из внешнего мира. А уж, если эта PE-ка откажет, и у нас не собран VRRP, то мы вообще будем отрезаны от других сетей или внешнего мира. Как ни странно, но у данной схемы есть и плюсы — это простота. Любому инженеру описанное выше решение будет понятно и в плане конфигурирования и в плане траблшутинга, чего я не могу сказать про решение, используемое в EVPN.
Помимо описанных выше недостатков, есть еще один важный нюанс — в описанной выше схеме мы никак не можем оптимизировать L3 трафик, идущий внутрь VPLS-домена или выходящий из него.
EVPN предлагает нам совершенно иную схему использования L3 интерфейсов. Если CE маршрутизатор хочет иметь выход во внешнюю сеть, другие вланы или интернет, то на PE-ке, к которой подключен данный CE маршрутизатор, должен быть сконфигурирован дефолтный шлюз в виде L3 интерфейса. Естественно, на каждый влан должен быть свой шлюз.
Примечательно то, что в RFC явно не написано, что каждый PE маршрутизатор должен иметь IRB-интерфейс для возможности выхода во внешнюю сеть. А вот в документации Juniper по настройке EVPN есть вот такие строки:
Initially when EVPN and Layer 3 gateway functionality were conceived, some basic assumptions were made, and RFC requirements were to be followed.
These were:
1. All PE’s for an EVPN instance must have an IRB configured.
2. All PE’s should have the same IP address for the GW. From the RFC, if there is a discrepancy between the GW IP addresses, an error is logged. Though it must be noted that different addresses can still be configured as both MAC/IP for advertisement to remote provider edge (PE) devices and are installed on all participating PE devices.
В итоге, если вы используете EVPN/MPLS, то конфигурировать L3 интерфейс на каждом PE маршрутизаторе обязательно, иначе этот сайт просто не выйдет из влана. А вот для EVPN/VXLAN данного требования нет (это, кстати, является существенным отличием EVPN/VXLAN от EVPN/MPLS)
Вернемся к нашей схеме. У нас два bridge-домена — это домен VLAN-777 и VLAN-1777. Во влане 1777 у нас два CE маршрутизатора — это CE1-2 и CE2-2, во влане 777 три маршрутизатора: CE1-1, CE2-1 и CE3. Естественно, я хочу иметь связность между всеми CE маршрутизаторами, указанными на схеме.
Но чтобы связать несколько bridge-доменов между собой одного добавления L3 интерфейса в routing-instance EVPN недостаточно. Необходимо еще создать на каждом PE маршрутизаторе routing-instance с типом VRF (которая используется для L3VPN), в которую необходимо поместить наши L3 интерфейсы. Таким образом мы свяжем два инстанса: VRF и EVPN (или virtual-switch):

Примечание: можно выпустить наш EVPN и в GRT, но, мне кажется, что это не очень хорошая идея. Во всяком случае это поддерживается, а уж реализовывать этот функционал или нет — решает каждый сам.
Как было сказано выше, нам необходимо сконфигурировать routing instance с типом VRF и связать ее с EVPN. Ниже представлена конфигурация с PE2 — virtual switch и связанный с ним VRF:
bormoglotx@RZN-PE-2> show configuration routing-instances RZN-VPN-1 instance-type virtual-switch; interface ge-0/0/2.0; interface ge-0/0/3.0; route-distinguisher 62.0.0.2:1; vrf-import VPN-1-IMPORT; vrf-export VPN-1-EXPORT; protocols { evpn { extended-vlan-list [ 777 1777 ]; } } bridge-domains { VLAN-1777 { vlan-id 1777; routing-interface irb.1777; } VLAN-777 { vlan-id 777; routing-interface irb.777; } } bormoglotx@RZN-PE-2> show configuration routing-instances VRF-VPN-1 instance-type vrf; interface irb.777; interface irb.1777; route-distinguisher 62.0.0.2:10002; vrf-target { import target:6262:10001; export target:6262:10001; } vrf-table-label;
Такие же VRF поднимаются на остальных PE маршрутизаторах, за исключением того, что в VRF на PE3 нет интерфейса irb.1777.
Мы уже знаем, что маршрут типа 2 может опционально содержать IP-адрес хоста. Сам маршрут MAC+IP мы уже видели: если помните, то при добавлении в EVPN IRB-интерфейса у нас генерировались два маршрута: просто MAC-адрес IRB-интерфейса, чтобы можно было до него добраться внутри bridge-домена не прибегая к маршрутизации и MAC+IP, к которому прикреплялось комьюнити default gateway. Второй маршрут был необходим для роутинга и является arp записью. Но MAC+IP маршрут генерируется не только для дефолтного шлюза. Такой маршрут до какого либо хоста будет появляться в том случае, если это хост попытается выйти во внешнюю сеть или другой влан.
Что надо хосту, чтобы выйти из влана? Верно — необходимо отправить пакет на шлюз по умолчанию. В нашем случае роль шлюза для bridge-домена играет IRB-интерфейс PE маршрутизатора. А чтобы послать пакет на IRB-интерфейс, хосту надо знать MAC-адрес этого IRB-интерфейса. Поэтому, для начала хост отправляет arp запрос на резолв MAC-адреса IRB-интерфейса. В тот момент, когда IRB-интерфейс получает arp запрос от хоста (в нашем случае CE маршрутизатора), который к данному PE маршрутизатору непосредственно подключен*, он и генерирует два маршрута типа 2: только MAC-адрес и MAC+IP — и рассылает их по BGP в виде EVPN маршрутов. Помимо этого, так как этот же маршрут в виде обычного IPv4 префикса с маской /32 появится еще и в связанном с EVPN VRF-е как локальный маршрут, то по BGP отправляется еще и vpnv4 маршрут до данного хоста (зачем нужно второе — поймете позже). Собственно, вышеописанное — это главный принцип работы EVPN при маршрутизации между вланами, который и позволяет оптимизировать прохождение трафика между разными bridge-доменами или между EVPN и внешними сетями.
Саму таблицу arp записей можно посмотреть на каждом PE маршрутизаторе. Для примера на PE2:
bormoglotx@RZN-PE-2> show bridge evpn arp-table INET MAC Logical Routing Bridging address address interface instance domain 10.0.1.2 aa:bb:cc:00:0a:00 irb.1777 RZN-VPN-1 VLAN-1777 10.0.1.22 aa:bb:cc:00:0a:00 irb.1777 RZN-VPN-1 VLAN-1777 10.0.1.222 aa:bb:cc:00:0a:00 irb.1777 RZN-VPN-1 VLAN-1777 10.0.0.2 aa:bb:cc:00:07:00 irb.777 RZN-VPN-1 VLAN-777
*10.0.1.22 и 10.0.1.222 — это secondary адреса CE2-2, навешенные в ходе тестирования для снятия дампов.
В выводе указывается, с какого интерфейса был сделан arp запрос, в каком bridge-домене и routing instance. Эта информация будет полезна, так как один и тот же MAC-адрес может быть в разных вланах или, как в представленном выше выводе — на одном физическом интерфейсе может быть несколько адресов, и, естественно, у них будет один MAC-адрес. Ко всем этим хостам вы обязательно найдете маршрут в VRF:
bormoglotx@RZN-PE-2> show route table VRF-VPN-1.inet.0 active-path | match "(10.0.0.2\/)|(10.0.1.2{1,3}\/)" 10.0.0.2/32 *[EVPN/7] 00:09:38 10.0.1.2/32 *[EVPN/7] 09:11:03 10.0.1.22/32 *[EVPN/7] 02:02:40 10.0.1.222/32 *[EVPN/7] 01:54:26
Теперь перейдем от теории к практике: разберем, как трафик будет идти от CE3 к CE1-2. Первый находится во влане 777 и имеет адрес 10.0.0.3, второй во влане 1777 и имеет адрес 10.0.1.1. Напоминаю, что на PE3 нет локального интерфейса irb.1777.
Итак, CE3 хочет отправить пакет на CE1-2, который находится в другой сети. CE3 не знает мак адрес основного шлюза, поэтому делает arp запрос на резолв адреса 10.0.0.254, который для данного CE маршрутизатора является основным шлюзом в другие сети. Естественно, на CE3 (да и на всех остальных CE-маршрутизаторах прописан дефолтный маршрут в сторону IRB-интерфейса). Так как PE3 получает arp запрос от CE3, адресованный его локальному IRB-интерфейсу, то PE3 генерирует MAC+IP маршрут и отправляет его на остальные PE-ки. Помимо этого, так как маршрут 10.0.0.3/32 появился в VRF в виде локального маршрута, то PE3 анонсирует еще и BGP vpnv4 маршрут:
bormoglotx@RZN-PE-3> show route advertising-protocol bgp 62.0.0.255 | match 10.0.0.3 * 10.0.0.3/32 Self 100 I 2:62.0.0.3:1::777::aa:bb:cc:00:05:00::10.0.0.3/304
Примечание: как правило, маршрут типа 2, содержащий только MAC-адрес, бывает уже сгенерирован раннее. В таком случае данный маршрут повторно не генерируется, дабы избежать флапов. PE маршрутизатор просто генерирует только MAC+IP анонс. Это не сложно увидеть на практике, посмотрев время жизни этих маршрутов — оно, как правило, будет разным.
Двигаемся далее. CE3 теперь знает MAC-адрес дефолтного шлюза, а значит знает, куда надо слать пакет, адресованный CE1-1 (имеется в виду MAC-адрес L2 заголовка). CE3 формирует пакет и в L3 заголовке адресом назначения указывает адрес CE1-1 (10.0.1.1), исходящим адресом указывает собственный адрес CE3 (10.0.0.3). В L2 заголовке адресом назначения указывает мак адрес irb.777, а исходящим адресом — собственный MAC-адрес (адрес интерфейса в сторону PE маршрутизатора).
Пакет прилетает на PE3. Так как MAC-адрес назначения — локальный интерфейс irb.777, то PE3 снимает L2 заголовок и делает IP lookup в таблице маршрутизации VRF, которая связана с нашей EVPN-instance. В настоящий момент в данной таблице четыре активных маршрута:
bormoglotx@RZN-PE-3> show route table VRF-VPN-1.inet.0 active-path VRF-VPN-1.inet.0: 4 destinations, 9 routes (4 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 10.0.0.0/24 *[Direct/0] 00:20:05 > via irb.777 10.0.0.3/32 *[EVPN/7] 00:00:06 > via irb.777 10.0.0.254/32 *[Local/0] 04:04:34 Local via irb.777 10.0.1.0/24 *[BGP/170] 02:19:20, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 16, Push 299776(top)
10.0.0.0/24 и 10.0.0.3/32 локальны для PE3 (второй как раз был сгенерирован при arp-запросе на irb.777), а вот маршрут до сети 10.0.1.0/24 мы получаем по BGP от PE1 и PE2.
Так как на PE1 и PE2 создан такой же VRF, как и на PE3 (с одинаковыми RT), то PE3 принимает все анонсы от PE1 и PE2. На них (PE1 и PE2), в свою очередь в данный VRF добавлен интерфейс irb.1777, а значит они будут анонсировать маршут до сети 10.0.1.0/24 по BGP в виде обычного vpnv4 маршрута, который и будет импортирован в таблицу маршрутизации VRF на PE3. В выводе выше показаны только активные маршруты, поэтому мы видим только один анонс, всего их, естественно, два — один получен от PE1, второй — от PE2. Лучшим выбран маршрут от PE1, так как он имеет меньший router-id, а все остальные параметры маршрутов, полученных от обоих PE-шек полностью идентичны. Какой маршрут будет выбран лучшим — от PE1 или PE2 — абсолютно неважно (к примеру если у нас будет 10 сайтов, то мы будем получать 9 маршрутов к одной сети, но выберется все равно только один), так как все равно при получении BUM трафика из bridge-домена VLAN-777, PE1 будет флудить его во все интерфейсы bridge-домена VLAN-1777. Почему — выясним далее.
В ходе IP lookup-а, PE3 поимает, что префикс 10.0.1.0/24 находится на PE1, поэтому PE3 отправляет пакет через L3VPN на PE1:
bormoglotx@RZN-PE-3> show route table VRF-VPN-1.inet.0 10.0.1.0/24 active-path VRF-VPN-1.inet.0: 4 destinations, 9 routes (4 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 10.0.1.0/24 *[BGP/170] 02:23:12, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 16, Push 299776(top)
Возможен вариант, когда на PE3 будет включена балансировка трафика по эквивалентным путям (ECMP) и в FIB будет установлено два маршрута, а значит трафик может пойти и на PE2, но это, как я написал выше, не важно — главное чтобы пакет попал на PE маршрутизатор, на котором есть локальный bridge-домен VLAN-1777 (по-другому быть и не может, если, конечно, у вас не настроен какой-нибудь жесткий ликинг между VRF-ми). Если такого bridge-домена на PE-ке не будет, то не будет и от нее анонса до сети 10.0.1.0/24.
PE1 принимает пакет от PE3 в VRF, делает IP lookup и понимает, что пакет предназначен bridge-домену VLAN-1777:
bormoglotx@RZN-PE-1> show route table mpls.0 label 16 mpls.0: 22 destinations, 23 routes (22 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 16 *[VPN/0] 02:25:02 to table VRF-VPN-1.inet.0, Pop
Так как PE1 не знает MAC-адреса хоста 10.0.1.1, то производится флуд arp запроса во все интерфейсы bridge-домена VLAN-1777 на резолв данного адреса. Если быть точнее, одна копия пакета отправляется на CE1-2, а вторая, с inclusive multicast меткой на PE2. А как же функция split horizon? Ведь пакет, полученный от PE маршрутизатора, не должен отправляться на другие PE маршрутизаторы. А тут по факту мы его нарушаем без зазрения совести. Дело в том, что данный пакет пришел, по L3VPN (то есть по сути из какой то внешней сети по отношению к EVPN на PE1), поэтому правило split-horizon тут не работает. Но мы то знаем что пакет прилетел из EVPN — не возникнет ли широковещательного шторма? Пакет хоть и прилетел из evpn, но из другого широковещательного домена (CE3 находится во влане 777, а CE1-2 во влане 1777). Так как это разные bridge-домены, то и широковещательного шторма между ними возникнуть не может — пакеты то между bridge-доменами маршрутизируются.
Так как CE1-2 является хостом назначения и подключен к PE1, то он отвечает на данный arp запрос. Как мы помним, после получения arp-а, адресованного IRB-интерфейсу от какого либо хоста, PE маршрутизатор должен сгенерировать маршрут типа 2 MAC+IP. В связи с этим, PE1 генерирует MAC+IP и vpnv4 маршрут:
bormoglotx@RZN-PE-3> show route table RZN-VPN-1.evpn.0 match-prefix *10.0.1.1* RZN-VPN-1.evpn.0: 19 destinations, 19 routes (19 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 2:62.0.0.1:1::1777::aa:bb:cc:00:09:00::10.0.1.1/304 *[BGP/170] 00:02:46, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 299792 bormoglotx@RZN-PE-3> show route table VRF-VPN-1.inet.0 10.0.1.1/32 VRF-VPN-1.inet.0: 5 destinations, 10 routes (5 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 10.0.1.1/32 *[BGP/170] 00:02:48, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 16, Push 299792(top)
Теперь у PE1 есть маршрут MAC+IP до хоста 10.0.0.3 в таблице маршрутизации EVPN и 10.0.0.3/32 в таблице маршрутизации VRF. Аналогично и со стороны PE3: маршрут до хоста 10.0.1.1/32 есть в таблице маршрутизации epn и VRF. Выходит, что теперь обмену пакетами между CE3 и CE1-2 ничего не препятствует. Но есть один нюанс. Давайте посмотрим таблицу маршрутизации в VRF на PE1:
bormoglotx@RZN-PE-1> show route table VRF-VPN-1.inet.0 10.0.0.3/32 VRF-VPN-1.inet.0: 7 destinations, 15 routes (7 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 10.0.0.3/32 *[EVPN/7] 00:24:37, metric2 1 > to 10.62.0.1 via ge-0/0/0.0, Push 300352, Push 299792(top) [BGP/170] 00:24:37, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.1 via ge-0/0/0.0, Push 16, Push 299792(top)
На PE1 два маршрута до хоста 10.0.0.3/32, в то время как на PE3 есть только один маршрут до 10.0.1.1/32:
bormoglotx@RZN-PE-3> show route table VRF-VPN-1.inet.0 10.0.1.1/32 VRF-VPN-1.inet.0: 6 destinations, 11 routes (6 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 10.0.1.1/32 *[BGP/170] 02:25:44, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 16, Push 299776(top)
В VRF появился какой то странный маршрут с пока что нам неизвестным протоколом EVPN, да еще и преференсом 7, что его делает лучше BGP ( а также предпочтительнее маршрутов ISIS, OSPF и т д). Как то странно, не правда ли. Что это за маршрут? Зачем он нам нужен, ведь и без него все будет работать. Дело в том, что данный маршрут необходим для прямого обмена трафиком между EVPN, минуя L3VPN. Давайте его рассмотрим внимательно:
bormoglotx@RZN-PE-1> show route table VRF-VPN-1.inet.0 10.0.0.3/32 protocol evpn detail VRF-VPN-1.inet.0: 7 destinations, 15 routes (7 active, 0 holddown, 0 hidden) 10.0.0.3/32 (2 entries, 1 announced) *EVPN Preference: 7 Next hop type: Indirect Address: 0x97f5f90 Next-hop reference count: 2 Next hop type: Router, Next hop index: 615 Next hop: 10.62.0.1 via ge-0/0/0.0, selected Label operation: Push 300352, Push 299792(top) Label TTL action: no-prop-ttl, no-prop-ttl(top) Load balance label: Label 300352: None; Label 299792: None; Session Id: 0x1 Protocol next hop: 62.0.0.3 Label operation: Push 300352 Label TTL action: no-prop-ttl Load balance label: Label 300352: None; Composite next hop: 0x95117b8 670 INH Session ID: 0x2 Ethernet header rewrite: SMAC: 02:00:00:00:07:77, DMAC: aa:bb:cc:00:05:00 TPID: 0x8100, TCI: 0x0309, VLAN ID: 777, Ethertype: 0x0800 Indirect next hop: 0x9860990 1048583 INH Session ID: 0x2 State: <Active NoReadvrt Int Ext> Age: 1:09 Metric2: 1 Validation State: unverified Task: RZN-VPN-1-evpn Announcement bits (1): 0-KRT AS path: I
Нам интересны следующие строки этого вывода:
Ethernet header rewrite: SMAC: 02:00:00:00:07:77, DMAC: aa:bb:cc:00:05:00 TPID: 0x8100, TCI: 0x0309, VLAN ID: 777, Ethertype: 0x0800
Это не что иное, как указание, какой надо добавить L2 заголовок, чтобы отправить пакет на CE3! Посмотрим, что за MAC-адрес указан как источник: SMAC: 00:05:86:71:1a:f0. Логично, что если это источник пакета, то он должен быть на PE1. Давайте прикинем, с какого MAC-адреса могут уходить пакеты во влан 777? Логично предположить, что это будет интерфейс irb.777, а значит в L2 заголовке должен быть именно его MAC. Посмотрим, какой в действительности MAC-адрес у irb.777:
bormoglotx@RZN-PE-1> show interfaces irb.777 | match mac MAC: 02:00:00:00:07:77
Все верно, в заголовке указан MAC-адрес локального интерфейса irb.777 на PE1, а значит наши рассуждения были верны. Давайте теперь идентифицируем, кому же принадлежит MAC-адрес назначения: DMAC: aa:bb:cc:00:05:00? Думаю, гадать не стоит — это должен быть MAC CE3. Давайте проверять:
bormoglotx@RZN-PE-1> show route table RZN-VPN-1.evpn.0 match-prefix *10.0.0.3* RZN-VPN-1.evpn.0: 21 destinations, 21 routes (21 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 2:62.0.0.3:1::777::aa:bb:cc:00:05:00::10.0.0.3/304 *[BGP/170] 00:05:18, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.1 via ge-0/0/0.0, Push 299792
Данный MAC принадлежит хосту 10.0.0.3, куда и указывает маршрут. Для достоверности пойдем на CE3 и посмотрим, как MAC на ее интерфейсе в сторону PE:
RZN-CE3-SW1#sh ip int br | i 10.0.0.3 Ethernet0/0.777 10.0.0.3 YES NVRAM up up RZN-CE3-SW1#sh interfaces eth0/0.777 | i Hard Hardware is AmdP2, address is aabb.cc00.0500 (bia aabb.cc00.0500)
Принадлежность адресов мы установили. Теперь поглядим на вторую строку интересующей нас части вывода:
TPID: 0x8100, TCI: 0x0309, VLAN ID: 777, Ethertype: 0x0800
А это значения, которыми необходимо заполнить остальные поля ethernet кадра при отправке на CE3.
То есть данный маршрут нам явно указывает, что если надо отправить ethernet кадр с irb.777 на хост CE3, то надо добавить указанные значения в L2 заголовок, навесить две метки: Push 300352, Push 299792(top) и отправить пакет в интерфейс ge-0/0/0.0. Все просто.
Примечание: данное действие с пакетом подразумевает использование composite next hop. Именно поэтому включение функционала chained-composite-next-hop обязательно на Juniper, при настройке EVPN.
bormoglotx@RZN-PE-1> show configuration routing-options forwarding-table chained-composite-next-hop { ingress { evpn; } }
Откуда же берется данный маршрут? Может быть нам его прислала PE3? Давайте проверим что анонсирует PE3 на рефлектор:
bormoglotx@RZN-PE-3> show route advertising-protocol bgp 62.0.0.255 | match 10.0.0.3 * 10.0.0.3/32 Self 100 I 2:62.0.0.3:1::777::aa:bb:cc:00:05:00::10.0.0.3/304
Ничего криминального, только два маршрута имеют в своем составе адрес 10.0.0.3. Первый — vpnv4 маршрут, второй — EVPN тип 2.
Значит этот маршрут локален для PE-маршрутизатора. Все верно. Данный маршрут генерируется локальным PE маршрутизатором на основе EVPN MAC+IP маршрута. Но тогда почему его нет на PE3? Воспользовавшись методом банальной эрудиции, можно прийти к выводу, что на PE3 нет bridge-домена влан 1777 с интерфейсом irb.1777 (ведь с него должен уходить пакет на CE1-2) и интерфейса irb.1777 нет в связанном VRF. А так как нет локального интерфейса, то какой MAC-адрес указать как source? Не поставишь же адрес другого интерфейса. Вот поэтому данный маршрут и отсутствует на PE3. Давайте проверим эту теорию — деактивируем на PE1 в VRF интерфейс irb.777, с которого должен будет улетать пакет на PE3.
Итак, маршрут на PE1 сейчас есть:
[edit] bormoglotx@RZN-PE-1# run show route table VRF-VPN-1.inet.0 10.0.0.3/32 VRF-VPN-1.inet.0: 8 destinations, 18 routes (8 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 10.0.0.3/32 *[EVPN/7] 00:01:22, metric2 1 > to 10.62.0.1 via ge-0/0/0.0, Push 300352, Push 299792(top) [BGP/170] 00:04:41, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.1 via ge-0/0/0.0, Push 16, Push 299792(top)
Деактивируем интерфейс IRB в VRF на PE1:
[edit] bormoglotx@RZN-PE-1# show | compare [edit routing-instances VRF-VPN-1] ! inactive: interface irb.777 { ... }
И проверяем, что у нас с маршрутом до 10.0.0.3/32:
[edit] bormoglotx@RZN-PE-1# run show route table VRF-VPN-1.inet.0 10.0.0.3/32 VRF-VPN-1.inet.0: 7 destinations, 13 routes (7 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 10.0.0.3/32 *[BGP/170] 00:05:47, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.1 via ge-0/0/0.0, Push 16, Push 299792(top)
Ну и проверим, а пройдет ли пинг?
RZN-CE1-SW2#ping 10.0.0.3 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 10.0.0.3, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 11/14/21 ms
Естественно, пинг прошел, но теперь трафик идет через L3VPN в обе стороны. Но хочется сказать, что даже в таком сценарии маршрут трафика оптимизирован. Тоже самое произойдет, если вывести bridge-домен VLAN-777 из конфигурации (в этом случае irb.777 еще будет в VRF, но в состоянии down, так как для того, чтобы IRB-интерфейс был в up, необходим хотя бы один физический интерфейс в состоянии up в bridge-домене, в котором находится IRB-интерфейс).
Но мы остановились на том, что пакет от CE3 дошел до CE1-2.Теперь CE1-2 хочет ответить на данный пакет. Здесь мы уже обойдемся без выводов из CLI.
Итак, CE1-2 отправляет пакет на адрес основного шлюза, адрес которого он уже знает. PE1 принимает пакет в bridge-домене VLAN-1777. Так как в пакете в L2 заголовке адресом назначения указан irb.1777, то PE1 снимает L2 заголовок и делает IP lookup в таблице маршрутизации VRF. В таблице маршрутизации есть маршрут до хоста 10.0.0.3/32, причем, как показано выше, маршрутов два и лучший EVPN. PE1 просто меняет L2 заголовок, навешивает метки и отправляет пакет на PE3.
PE3 получает пакет, видит метку, которая указывает на то, что необходимо сделать L2 lookup в MAC-таблице bridge-домена VLAN-777, и, согласно информации в ней, переслать пакет на CE3.
Собственно, вот мы и рассмотрели весь процесс, происходящий с пакетом, при его движении от CE3 к CE1-2 и обратно. Но мы рассмотрели процесс в момент, когда еще не было трафика между данными узлами и PE маршрутизаторы не знали MAC-адресов CE1-2 и CE3. После того, как адреса стали известны и маршруты разлетелись по всем PE-кам, трафик пойдет несколько иначе. Давайте вкратце рассмотрим, как конечном итоге будет идти трафик:
От CE3 к CE1-2:
- Пакет от CE3 попадает в bridge-домен влан 777 на PE3.
- PE3 делает IP lookup в звязанном VRF и видит специфичный маршрут до хоста 10.0.1.1/32. Так как на PE3 нет локального bridge-домена влан 1777, то и нет и EVPN маршрута. Значит трафик идет через L3VPN на PE1.
- PE1 принимает пакет в VRF, снимает с него метку и видит, что он предназначен bridge-домену влан 1777.
- PE1 отправляет пакет на CE2-1 согласно MAC-таблице bridge-домена влан 1777.
Теперь пакет в обратном направлении От CE1-2 к CE3:
- CE1-2 отправляет ответный пакет на PE1.
- PE1 делает IP lookup в VRF и видит маршрут к хоста 10.0.0.3/32, причем лучший маршрут — это маршрут EVPN.
- PE1 навешивает новый L2 заголовок и добавляет стек из двух меток, согласно информации, содержащейся в EVPN в маршруте в связанном VRF.
- PE3 принимает пакет от PE1, снимает метку и видит, что необходимо сделать L2 lookup в MAC-таблице bridge-домена VLAN-777.
- Далее PE3 пересылает пакет на CE3.
Как видите, в обратную сторону пакет летит несколько иначе — это называется ассиметричным форвардингом. Возникает резонный вопрос — почему асимметричным? Дело в том, что ingress PE делает IP lookup в VRF и отправляет пакет на основании имеющегося в VRF EVPN маршрута, а вот egress PE уже принимает пакет не в VRF, а в EVPN-инстанс. Если сравнить две последние схемы, то будет хорошо видна симметричность и асимметричность трафика. Думаю, что все поняли как это работает.
Схема, которую мы разобрали, называется схемой с симметричным использованием IRB-интерфейсов (разные вендоры могут по разному называть данную схему, указанный термин взят из мануалов по настройке EVPN на Brocade). Асимметричной схемой будет являться схема, когда на всех PE маршрутизаторах будут одинаковые IRB-интерфейсы, даже при условии того что указанного влана на данном PE маршрутизаторе нет. Плюсом асимметричной схемы будет то, что во всех VRF будут маршруты протокола EVPN ([EVPN/7]) и ваш трафик не будет проходить в одну сторону через L3VPN, а обратно напрямую в EVPN. В нашем случае, если мы добавим в схему irb.1777 на PE3, то мы получим асимметричную схему.
Но есть еще одно но, которое надо осветить.
Как вы знаете, ARP запрос отправляется на бродкастный адрес, а ответ на него форвардится назад по указанному в заголовке MAC-адресу отправителя.
В рассмотренном выше случае CE1-2 был непосредственно подключен к PE1 и все работало штатно: PE1 отправлял arp запрос, и CE1-2 ему отвечал — собственно, никаких проблем. Но, если бы CE3 отправлял пакет на CE2-2, то события развивались несколько иначе. Сначала все так же, как и описано ранее:
- PE3 смотрит в таблицу маршрутизации VRF и видит маршрут к сети 10.0.1.0/24, полученный от PE1.
- У PE3 нет других вариантов, кроме как отправить пакет через L3VPN на PE1.
- PE1 принимает пакет, делает L3 lookup и переправляет его в bridge-домен VLAN-1777. Так как irb.1777 еще не знает MAC-адрес CE2-2, то он инициирует arp запрос на резолв адреса CE2-2 (10.0.1.2), отправляя пакет на CE1-2 и PE2.
- CE1-2 дропает пакет, так как адрес 10.0.1.2 ему не принадлежит. PE2 пересылает полученный запрос на CE2-2.
- CE2-2 принимает arp запрос и отвечает на него юникастом на MAC-адрес, принадлежащий irb.1777 на PE1.
Но получит ли irb.1777 на PE1 ответ от CE2-2? Вспоминаем про синхронизацию MAC-адресов между дефолтными шлюзами. Вспомнили? Значит понимаете, что irb.1777 на PE2 примет пакет, направленный на MAC-адрес irb.1777 PE1. В итоге PE1 не получит ответа на свой запрос, сколько бы он их ни отправлял, а значит не разрезолвит IP-адрес назначения и не сможет отправить пакет на CE2-2. Все было бы так, если бы это был бы не EVPN.
Так как irb.1777 на PE2 принял arp от CE2-2, то он генерирует маршрут типа 2 (MAC и MAC+IP), а также vpnv4 префикс. Как понимаете PE1 уже не нужен ответ на его arp запрос, так как теперь он получил MAC-адрес CE2-2 по BGP и может переслать ему пакет, который находился в буфере. Получается, что трафик на CE2-2, который живет на PE2 идет с PE3 петлей через PE1? Не совсем так. Петлей прилетел только пакет (или пакеты), который PE3 уже успел отправить и которые находились в очереди на отправку на PE1. Но так как и на PE3 появился в VRF более специфичый маршрут до CE2-2, то в дальнейшем трафик уже пойдет не через PE1 по маршруту 10.0.1.0/24, а напрямую на PE2 (по маршруту 10.0.1.2/32, который появится в таблице маршрутизации VRF).
В рассмотренном нами случае у всех IRB-интерфейсов были разные MAC-адреса, что подразумевало необходимость в синхронизации дефолтных шлюзов. Рекомендуемый вариант использования IRB-интерфейсов — использовать одинаковые MAC и IP-адреса на всех PE маршрутизаторах одного bridge-домена. Как вы понимаете, когда везде MAC-адреса будут одинаковы и все будет работать так, как я описал выше, только синхронизации дефолтных шлюзов, по сути, не надо.
В конечном счете, при любом раскладе, как бы вы ни использовали IRB-интерфейсы:
с одинаковыми IP, но разными MAC-адресами;
с одинаковыми IP и MAC-адресам,
все равно все PE маршрутизаторы в EVPN-домене получат маршрут MAC+IP и BGP vpnv4 префикс, а значит при отправке пакета с другого CE маршрутизатора не потребуется снова отправлять arp запрос на резолв данного адреса. Это позволяет существенно сократить arp флудинг по сети провайдера.
Выход в другие VRF и внешние сети
Выше мы разобрали, как трафик будет идти между вланами. Но как быть с доступом из других VRF, никак не связанных evpn?
Давайте попробуем достучаться до например хоста 10.0.1.1/32 из VRF, который не связан ни с одной EVPN. Делать новый VRF мне не хочется, поэтому я поступлю проще: на PE3 деактивируем instance evpn, а в VRF деактивируем irb.777 и добавим новый интерфейс irb.0 (20.0.0.1/24):
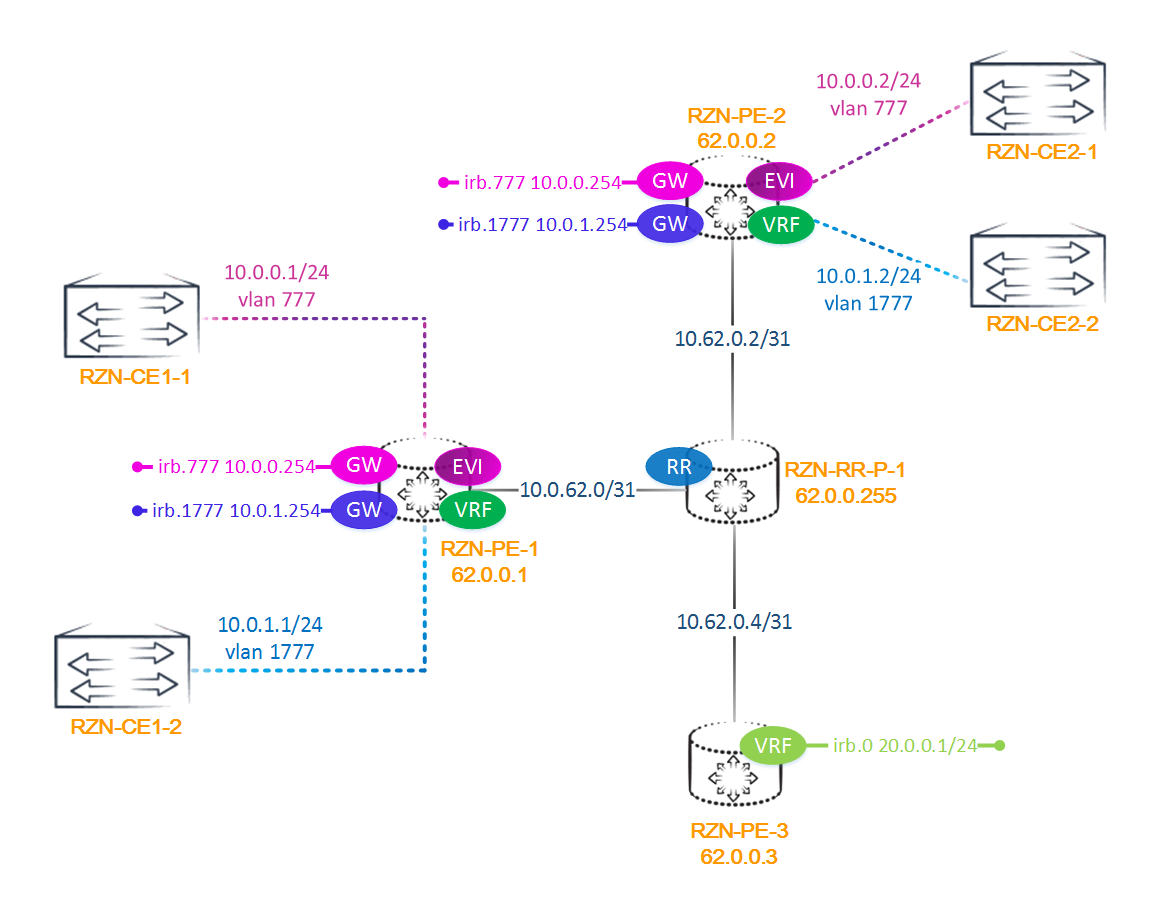
[edit] bormoglotx@RZN-PE-3# show routing-instances RZN-VPN-1 ## ## inactive: routing-instances RZN-VPN-1 ## instance-type evpn; vlan-id 777; interface ge-0/0/2.777; routing-interface irb.777; route-distinguisher 62.0.0.3:1; vrf-import VPN-1-IMPORT; vrf-export VPN-1-EXPORT; protocols { evpn { interface ge-0/0/2.777; } } [edit] bormoglotx@RZN-PE-3# show routing-instances VRF-VPN-1 instance-type vrf; interface irb.0; inactive: interface irb.777; route-distinguisher 62.0.0.3:10003; vrf-target { import target:6262:10001; export target:6262:10001; } vrf-table-label; [edit] bormoglotx@RZN-PE-3# show interfaces irb.0 family inet { address 20.0.0.1/24;
Смотрим, что у нас в таблице маршрутизации:
bormoglotx@RZN-PE-3> show route table VRF-VPN-1.inet.0 active-path VRF-VPN-1.inet.0: 7 destinations, 9 routes (7 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 10.0.0.0/24 *[BGP/170] 00:00:03, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 16, Push 299776(top) 10.0.1.0/24 *[BGP/170] 00:00:03, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 16, Push 299776(top) 10.0.1.1/32 *[BGP/170] 00:00:03, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 16, Push 299776(top) 10.0.1.2/32 *[BGP/170] 00:00:03, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 16, Push 299792(top) 10.0.1.22/32 *[BGP/170] 00:00:03, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 16, Push 299792(top) 20.0.0.0/24 *[Direct/0] 00:00:03 > via irb.0 20.0.0.1/32 *[Local/0] 00:00:03 Local via irb.0
Я специально деактивировал данный VRF, чтобы показать, что маршруты /32 сразу прилетят в виде vpnv4 префиксов и встанут в таблицу маршрутизации (как видите время жизни маршрута в таблице у всех префиксов одинаково и равно трем секундам).
Теперь запустим пинг с нашего IRB-интерфейса (20.0.0.1) на CE1-2 (10.0.1.1), который живет за PE1:
bormoglotx@RZN-PE-3> ping rapid routing-instance VRF-VPN-1 source 20.0.0.1 10.0.1.1 PING 10.0.1.1 (10.0.1.1): 56 data bytes !!!!! --- 10.0.1.1 ping statistics --- 5 packets transmitted, 5 packets received, 0% packet loss round-trip min/avg/max/stddev = 5.828/7.872/10.368/1.655 ms
А теперь до хоста CE2-2 10.0.1.2, который живет на PE2:
bormoglotx@RZN-PE-3> ping rapid routing-instance VRF-VPN-1 source 20.0.0.1 10.0.1.2 PING 10.0.1.2 (10.0.1.2): 56 data bytes !!!!! --- 10.0.1.2 ping statistics --- 5 packets transmitted, 5 packets received, 0% packet loss round-trip min/avg/max/stddev = 5.443/6.713/7.342/0.656 ms
Теперь снова вернемся к маршрутам и посмотрим, разными ли путями идут пакеты:
bormoglotx@RZN-PE-3> show route table VRF-VPN-1.inet.0 10.0.1.1/32 VRF-VPN-1.inet.0: 7 destinations, 9 routes (7 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 10.0.1.1/32 *[BGP/170] 00:03:50, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 16, Push 299776(top)
bormoglotx@RZN-PE-3> show route table VRF-VPN-1.inet.0 10.0.1.2/32 VRF-VPN-1.inet.0: 7 destinations, 9 routes (7 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 10.0.1.2/32 *[BGP/170] 00:03:52, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 16, Push 299792(top)
Итак, до 10.0.1.1 транспортная метка 299776, а до 10.0.1.2 — 299792. Смотрим, что это за LSP:
Метка 299776 — транспортная метка до 62.0.0.1 (PE1):
bormoglotx@RZN-PE-3> show route 62.0.0.1/32 table inet.3 inet.3: 3 destinations, 3 routes (3 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 62.0.0.1/32 *[LDP/9] 03:36:41, metric 1 > to 10.62.0.5 via ge-0/0/0.0, Push 299776
Метка 299776 — транспортная метка до 62.0.0.2 (PE2):
bormoglotx@RZN-PE-3> show route 62.0.0.2/32 table inet.3 inet.3: 3 destinations, 3 routes (3 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 62.0.0.2/32 *[LDP/9] 03:36:45, metric 1 > to 10.62.0.5 via ge-0/0/0.0, Push 299792
Как видите, даже из VRF, абсолютно ничего не знающего про EVPN, трафик идет оптимальным путем. Обратный трафик из EVPN в VRF до сети 20.0.0.0/24 идет по маршруту, полученному по BGP:
bormoglotx@RZN-PE-2> show route table VRF-VPN-1.inet.0 20.0.0.0/24 active-path VRF-VPN-1.inet.0: 10 destinations, 16 routes (10 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 20.0.0.0/24 *[BGP/170] 00:06:44, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.3 via ge-0/0/0.0, Push 16, Push 299808(top)
Путь пакета из VRF (irb.0 20.0.0.1) в EVPN (CE1-2 10.0.1.1):
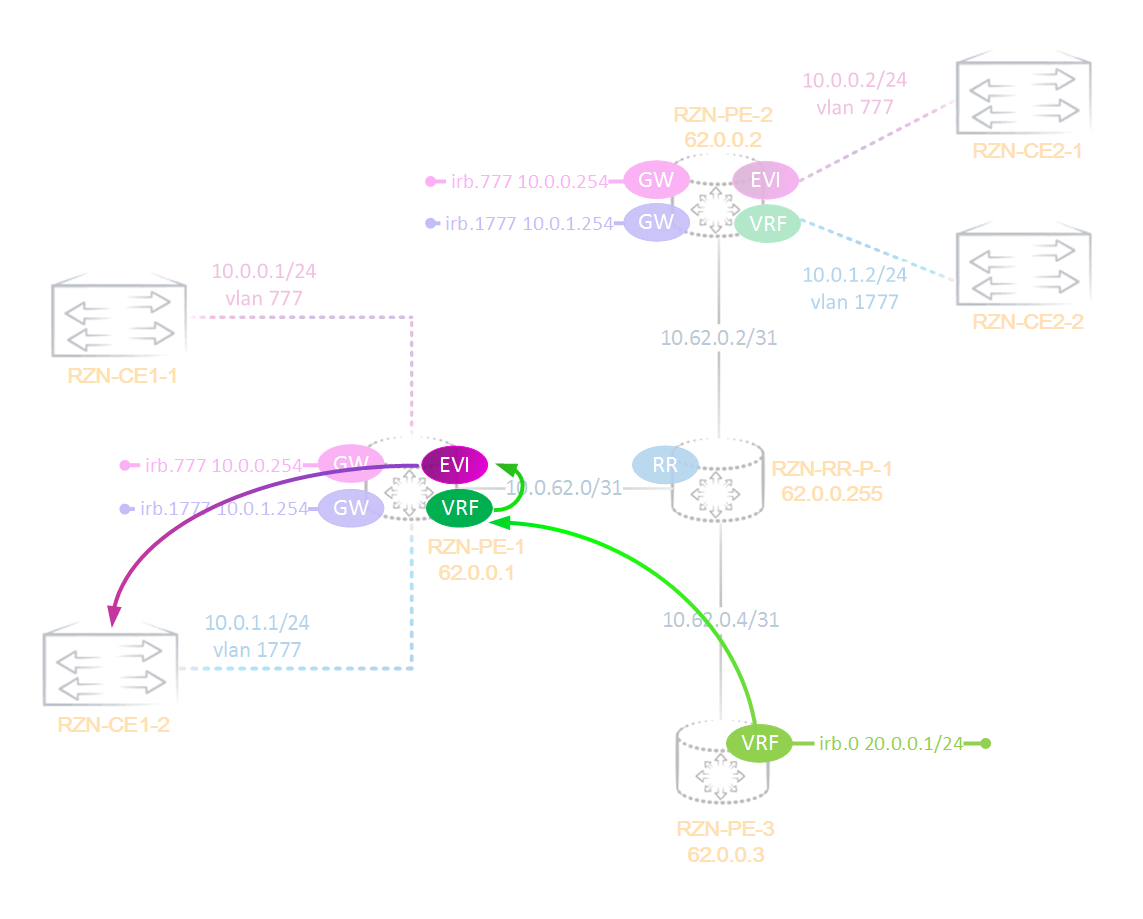
Маршрут прохождения обратного трафика:

Но представленный случай прост — маршруты до хостов 10.0.1.1 и 10.0.1.2 уже были в таблице маршрутизации. Как быть, если маршрута до хоста нет? Тут все работает так же, как при в первом случае (когда на PE маршрутизаторе нет bridge-домена, в котором живет хост назначения). Давайте достучимся например до 10.0.0.2, специфичного маршрута до которого у нас в данный момент нет:
bormoglotx@RZN-PE-3> show route table VRF-VPN-1.inet.0 10.0.0.2/32 bormoglotx@RZN-PE-3>
Маршрута и правда нет, но зато у нас есть маршрут до 10.0.0.0/24:
bormoglotx@RZN-PE-3> show route table VRF-VPN-1.inet.0 10.0.0.0/24 | match \/24 10.0.0.0/24 *[BGP/170] 00:13:14, localpref 100, from 62.0.0.255
Логично, что трафик пойдет по этому маршруту. Запустим пинг и проверим, что все работает:
bormoglotx@RZN-PE-3> ping rapid routing-instance VRF-VPN-1 source source 20.0.0.1 10.0.0.2
PING 10.0.0.2 (10.0.0.2): 56 data bytes !!!!! --- 10.0.0.2 ping statistics --- 5 packets transmitted, 5 packets received, 0% packet loss round-trip min/avg/max/stddev = 6.135/7.206/7.806/0.663 ms
Пинг успешно прошел, а в VRF у нас появился маршрут до хоста 10.0.0.2/32:
bormoglotx@RZN-PE-3> show route table VRF-VPN-1.inet.0 10.0.0.2/32 VRF-VPN-1.inet.0: 9 destinations, 11 routes (9 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 10.0.0.2/32 *[BGP/170] 00:00:06, localpref 100, from 62.0.0.255 AS path: I, validation-state: unverified > to 10.62.0.5 via ge-0/0/0.0, Push 16, Push 299792(top)
Надеюсь, вы поняли как это работает.
Зачем это все таки нужно?
Один из моих знакомых окрестил данную технологию — наркоманией. Возможно, что алгоритм использования IRB-интерфейса слишком запутан и сложен для понимания и не только в плане работы, но и в плане того, зачем оно вообще нужно. Но вспомните, когда вы первый раз услышали про MPLS — разве эта технология вам была полностью понятна? Думаю, что вряд ли.
Но почему нельзя было сделать так же как и в VPLS — один выход из всего домена? Давайте подумаем, какую проблему решает описанное выше использование L3 интерфейсов. EVPN по своей сути предназначалась для соединения датацентров. Из датацентра идет очень приличное количество трафика, в отличии от простого клиентского VPLS. Поэтому рассмотрим вот такой случай:
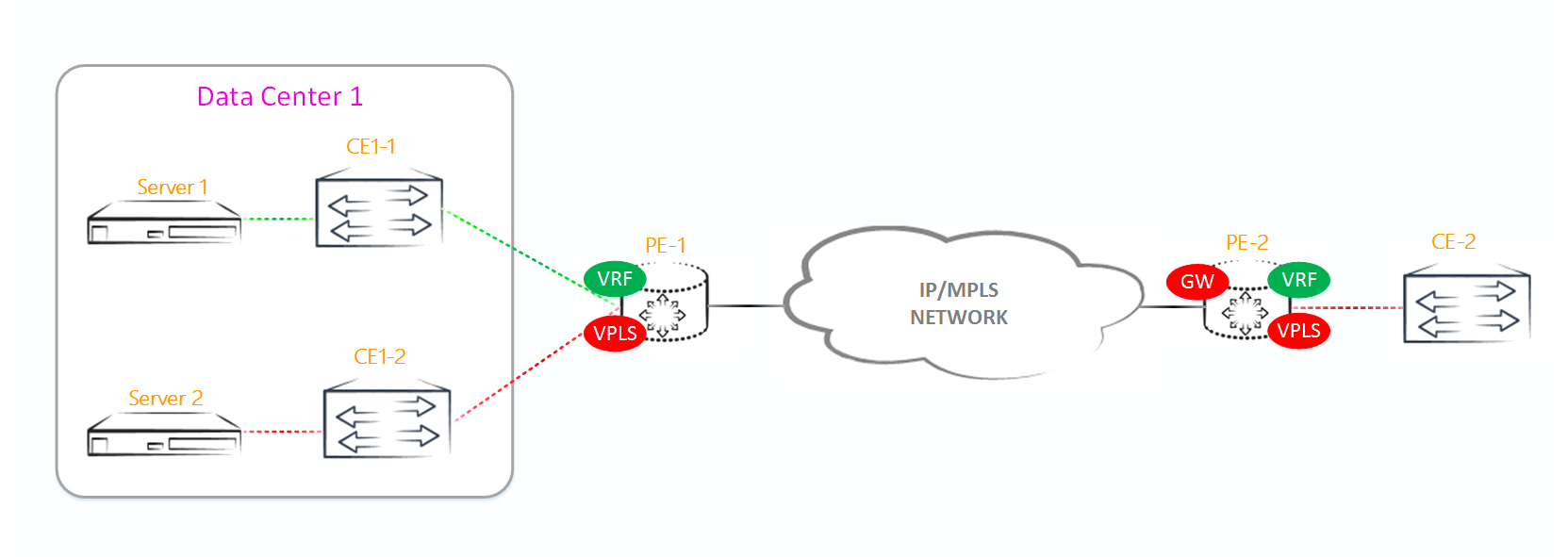
У нас одна точка выхода из VPLS, расположенная на PE2, и предположим, что CE1 подключен к L3VPN, а CE2 к VPLS домену. Важным тут является то, что обе эти сетки будут жить в одном и том же датацентре, но вот ходить трафик между ними будет по такой петле:
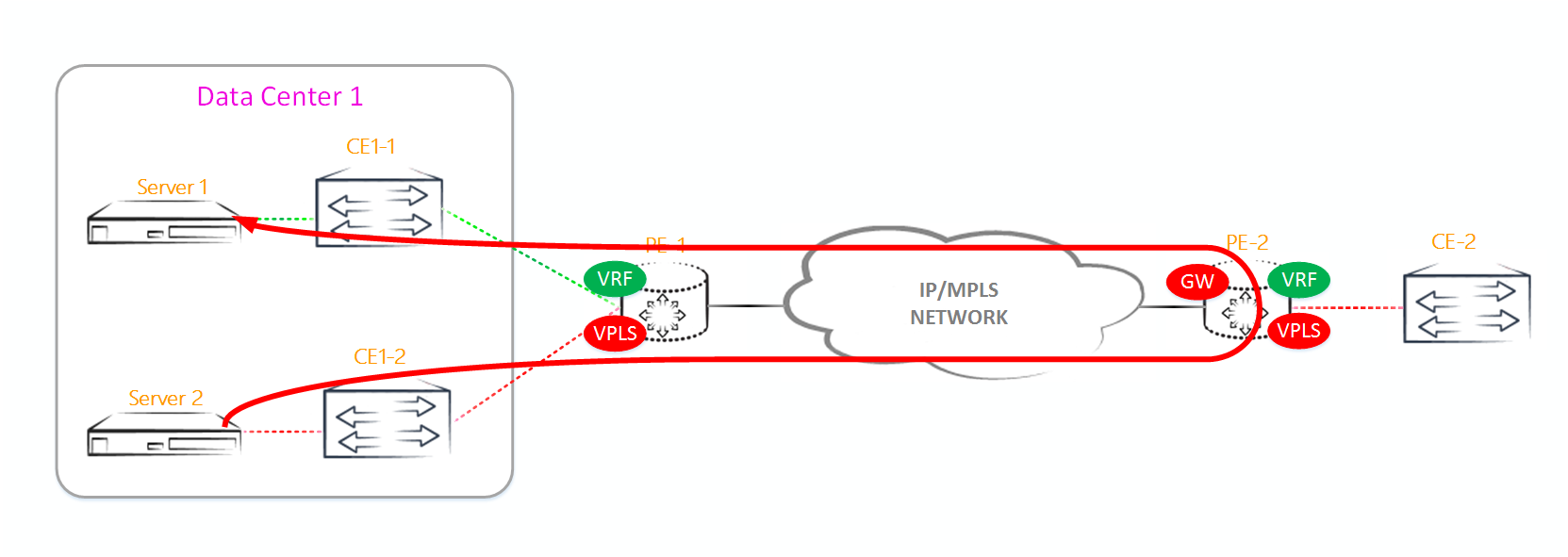
Сначала трафик от Server 2 идет к выходу из VPLS домена, который находится на PE2, и с PE2, через L3VPN возвращается обратно на PE1. Возможно, что даже эти два серверы будут включены в одни и тот же коммутатор и/или стоят в одном и том же стативе в датацентре. Да, если это какой то малый объем трафика, то пусть он так и идет — скорее всего, тут игра не стоит свеч. Но, если это потоковое видео, загрузка какого либо контента с FTP-server-а и т д? Тогда весь этот объем трафика дважды пройдет по ядру сети, просто забивая полосу пропускания по сути “паразитным” трафиком. Именно эту задачу решает L3 функционал EVPN. Генерируя /32 маршрут к хосту и передавая его в VRF, EVPN оптимизирует прохождение трафика между разными сетями. Если в представленной выше схеме использовать EVPN, то PE1 сгенерировал бы /32 маршрут к server1, и трафик пошел бы локально через PE1, а не петлей через все ядро:
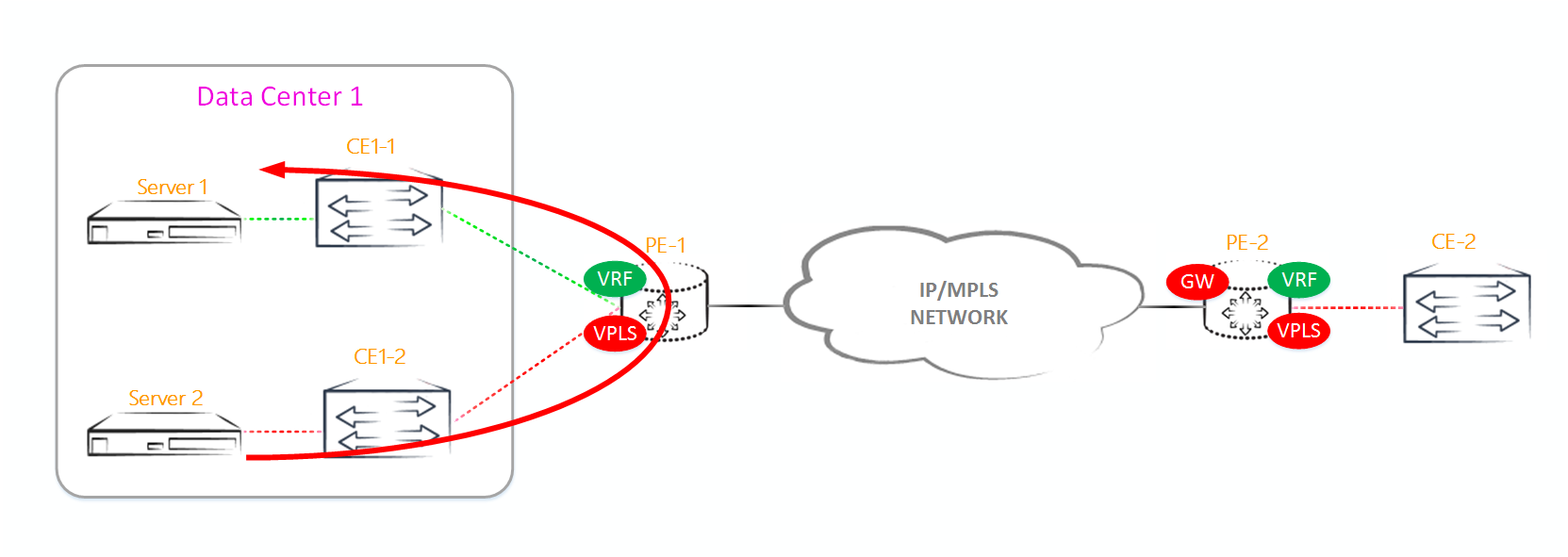
И это только один пример…
Заключение
Как видите, EVPN является не просто технологией 2-го уровня. В данную технологию глубоко интегрирован и роутинг и свитчинг. Причем использовать вышеописанную схему с интеграцией в VRF не обязательно, если вы прокидываете просто клиентский L2 сервис.
Но за всё в этом мире надо платить и EVPN не исключение. То что технология сложна и запутана — это не проблема, надо просто в ней разобраться (ведь когда то и VPLS казался темным лесом — а сейчас кажется, что вроде все логично и понятно (во всяком случаем мне)). Одной из проблем может стать большое количество /32 и большое количество маршрутов типа 2, разобраться в которых порой будет нереально. Давайте прикинем, что у нас например 4 сети, размером /24 — грубо говоря, это сети на 250 хостов. Если мы хотим, чтобы все хосты общались друг с другом, то мы получим 1000 маршрутов /32 (по 250 маршрутов /32 и типа 2 на каждую сеть /24). А если таких доменов будет 10? Тогда уже 10 000 маршрутов с маской /32 будут летать по нашей сети, нагружая control plane. Причем эти цифры в реалиях современных датацентров с их системами виртуализации будут на 2-3 порядка выше описанных в статье. Мы знаем, что роутрефлектор отправляет своим нейборам все маршруты, разрешенные групповой экспортной политикой. Если, для примера, в нашу топологию добавить маршрутизатор PE4, который будет иметь vpnv4 сессию с рефлектором, то он будет получать от рефлектора все наши 10 000 маршрутов, которые ему то особо не нужны. Естественно, PE4 будет смотреть на RT и отбрасывать анонс, но эта работа тоже будет нагружать процессор RE. В RFC нет никаких рекомендаций по этому поводу. Juniper же рекомендует использовать семейство адресов route-target, дабы получать только нужные анонсы. Но в своей практике от данного семейства адресов я получал пока что только проблемы.
Ко всему прочему ответим на простой вопрос: почему MAC-адреса не используются для роутинга? Ведь в отличии от IPv4 адресов, MAC-адресов больше, они глобально уникальны, есть как бродкастные, так и мультикастные адреса, есть даже приватные (точнее назначенные вручную администраторами вне зависимости от производителя оборудования) MAC-адреса. Используй — не хочу! Но почему-то используется IP со всеми его костылями типа NAT и т д. Одной из самых важных причин является то, что MAC-адреса, в отличии от IP-адресов, не агрегируются в подсети, так как первая их часть отвечает не за географическое расположение адреса или организацию, которой этот блок адресов выдан, а за принадлежность оборудования к тому или иному производителю. В итоге получается что теоретически MAC-адреса поддаются агрегации, но практически на живой сети это сделать нереально, так как например MAC-адрес 04:01:00:00:01:01 принадлежит железке, расположенной где нибудь на побережье Флориды, а железка с MAC-адресом 04:01:00:00:01:02 например уже в Рязани.
Сегодня FV насчитывает более 600 000 агрегированных маршрутов. Представьте размер таблицы маршрутизации, если бы для роутинга использовались исключительно /32 адреса. Зачем я об этом пишу? Дело в том, что если у вас соединены 5-6 датацентров, в которых порядка 100к MAC-адресов, то представьте какая нагрузка ляжет на control plane по распределению только EVPN маршрутов (о практически таком же количестве /32 я молчу). У данной проблемы есть решения, например, использование PBB, но, как говорится, это уже совсем другая история…
Если кому то интереснее покопаться глубже, то вот некоторые ссылки на информацию по данной тематике:
→ Непосредственно сам RFC 7432 со всей историей изменений;
→ Juniper EVPN;
→ Juniper EVPN IRB;
→ Cisco EVPN PBB;
→ Cisco EVPN VXLAN;
→ Brocade EVPN.
Ссылки на все предыдущие выпуски СДСМ:
12. Сети для самых матёрых. Сети для самых матёрых. Часть двенадцатая. MPLS L2VPN
11.1. Сети для самых маленьких. Микровыпуск №6. MPLS L3VPN и доступ в Интернет
11. Сети для самых маленьких. Часть Одиннадцатая. MPLS L3VPN
10. Сети для самых маленьких. Часть десятая. Базовый MPLS
9. Сети для самых маленьких. Часть девятая. Мультикаст
8.1 Сети для Самых Маленьких. Микровыпуск №3. IBGP
8. Сети для самых маленьких. Часть восьмая. BGP и IP SLA
7. Сети для самых маленьких. Часть седьмая. VPN
6. Сети для самых маленьких. Часть шестая. Динамическая маршрутизация
5. Сети для самых маленьких: Часть пятая. NAT и ACL
4. Сети для самых маленьких: Часть четвёртая. STP
3. Сети для самых маленьких: Часть третья. Статическая маршрутизация
2. Сети для самых маленьких. Часть вторая. Коммутация
1. Сети для самых маленьких. Часть первая. Подключение к оборудованию cisco
0. Сети для самых маленьких. Часть нулевая. Планирование
11.1. Сети для самых маленьких. Микровыпуск №6. MPLS L3VPN и доступ в Интернет
11. Сети для самых маленьких. Часть Одиннадцатая. MPLS L3VPN
10. Сети для самых маленьких. Часть десятая. Базовый MPLS
9. Сети для самых маленьких. Часть девятая. Мультикаст
8.1 Сети для Самых Маленьких. Микровыпуск №3. IBGP
8. Сети для самых маленьких. Часть восьмая. BGP и IP SLA
7. Сети для самых маленьких. Часть седьмая. VPN
6. Сети для самых маленьких. Часть шестая. Динамическая маршрутизация
5. Сети для самых маленьких: Часть пятая. NAT и ACL
4. Сети для самых маленьких: Часть четвёртая. STP
3. Сети для самых маленьких: Часть третья. Статическая маршрутизация
2. Сети для самых маленьких. Часть вторая. Коммутация
1. Сети для самых маленьких. Часть первая. Подключение к оборудованию cisco
0. Сети для самых маленьких. Часть нулевая. Планирование
От автора
На написание статьи, тестирование различных функций, чтение RFC и другой доступной литературы различных вендоров (не ограничиваясь только Cisco и Juniper) ушло более 2-х месяцев. Как видите, тесты проводились исключительно на Juniper, и у других вендоров реализация какого то функционала может несколько отличаться от описанного выше. Надеюсь изложенное в статье будет понятно и полезно читателям. Если нашли в статье опечатки или какие-то косяки — пишите в личку. Ну, и спасибо за внимание...
