Т.к. мой классификатор из прошлого поста таки работает (впрочем, параметры «из коробки» не всегда удачны, потому я вынес возможность слегка настроить Conv1d-слои и скрытый слой) — я решил прикрутить его к боту. Да, запоздал я на этот хайп ) Кстати, заранее уточню, что прикрутить русский я пока таки не пробовал, хотя это не должно стать проблемой — в nltk поддерживаются нужные фичи, обучение word2vec концептуально не отличается от английского, да и предобученные модели вроде бы имеются.
Ну и сходу возникают вопросы:
Понадобятся:
За данными (структура и дамп postgres-й БД, word2vec, конфиг обученного бота) — сюда.
В моём случае сценарий бота может быть описан как дерево (ну, на самом деле — с учётом «goto» — скорее граф), узел которого может содержать условия:
Кроме дерева в сценарии указаны:
Например
Переключение из 1 состояния в другое (а заодно — извлечение сущностей) в другое происходит так:
Ужасный код на bitbucket. Для начала — выделил такие сущности:
Теперь возможно такое:
Уже можно пытаться что-нибудь запустить, но я пошёл дальше.
Ещё более ужасный код на bitbucket. Опять делим сущности:
Как-то так:
Пример кода:
Ну и в результате:
Последняя запись пуст��, т.к. в сценарии нет узла по которому можно перейти в этом случае.
В конфигурации — следующие опции:
Теперь у нас вроде бы есть все средства для более или менее адекватного хранения роботов, их состояний и вспомогательных данных. И — возможность прикручивать их к различным мессенджерам (да и не только), прикрутив соответсвующую обёртку.
Перед просмотром кода рекомендуется запастись успокоительными. Обёртка добавляет к моделям ещё пару полей (telegram_chat_id в Conversation, telegram_bot_id в Robot). Ну и многопоточность во все поля.
Вот пример:
И диалог полученный при тесте
Ну и сходу возникают вопросы:
- под какие платформы его пилить — пока решил остановиться на telegram. В теории — конструкция позволяет легко дописать обертки для других платформ (как будто он кому-то понадобится )
- как описывать «сценарий». Навелосипедил свою структуру с классами и сущностями поверх YAML
- ну и неплохо бы хранить ботов/состояние в какой-нибудь БД
Требования
Понадобятся:
- pynlc. Инструкции по установке вспомогательных средств (keras, nlkt, gensim и их зависимости) — в моём прошлом посте
- robot
- robotframework. Понадобится поставить sqlalchemy
- robotframework_telegram. Потребуется python-telegram-bot
К чёрту подробности, давай пример
Код на python
import logging
from robotframework_telegram import RobotFrameworkTelegram
from config import config
if __name__ == '__main__':
bots = RobotFrameworkTelegram({
'DATABASE_URI': 'URI',
'KEEP_WORD_VECTORS': 3,
'ROBOT_CONFIGURATIONS': 'robot_configurations',
'KEEP_ROBOTS': 5,
'OUTPUT_HANDLERS': {},
'TOKENS': [
# Your tokens here
],
'NO_ANSWER_MESSAGE': 'Sorry, I can\'t answer now.',
'NO_INSTANCE_MESSAGE': 'Sorry, robot not instantiated yet. ' + \
'You\'ll get answer after instantiation - it can take few minutes',
'TELEGRAM_WORKERS_PER_BOT': 1,
'WORKER_COUNT': 2,
'WORKER_SLEEP_TIME': 0.2,
'LOGGER': logging,
})
bots.start_polling()
За данными (структура и дамп postgres-й БД, word2vec, конфиг обученного бота) — сюда.
Описание сценария
В моём случае сценарий бота может быть описан как дерево (ну, на самом деле — с учётом «goto» — скорее граф), узел которого может содержать условия:
- о классе пользовательского текста
- о используемых типах сущностей
Кроме дерева в сценарии указаны:
- данные для обучения классификатора
- типы сущностей (условное {«city»: [«Moscow»,«Tokeyo»,«Ottava»]})
- их синонимы (не менее условное {«Moscow»: [«Default city»]})
- (опционально) дополнительные параметры классификатора. Например, в случае моего «погодного» примера конфигурация сети, которая будет выстроена по стандартным параметрам — лютейший оверкилл, потому я снизил количество размеров фильтров и нейронов выходного слоя.
Например
куча yaml
script:
text: Hello. I'm weather robot. How can I help you?
name: main
children:
-
name: city_conditions
text: "Conditions in {%print $city%} is next."
conditions:
class: conditions
entity_variables:
city: $city
-
name: city_temperature
text: "Temperature in {%print $city%} is next."
conditions:
class: temperature
entity_variables:
city: $city
-
name: conditions
text: Okay, type city name.
conditions:
class: conditions
children:
-
name: conditions_city_selected
text: "{%goto city_conditions%}"
conditions:
entity_variables:
city: $city
-
name: temperature
text: Okay, type city name.
conditions:
class: temperature
children:
-
name: temperature_city_selected
text: "{%goto city_temperature%}"
conditions:
entity_variables:
city: $city
entities:
city:
- Moscow
- Tokyo
- Ottava
synonyms:
Moscow:
- default city
- DC
classes:
temperature:
- How hot is it today?
- Is it hot outside?
- Will it be uncomfortably hot?
- Will it be sweltering?
- How cold is it today?
- Is it cold outside?
- Will it be uncomfortably cold?
- Will it be frigid?
- What is the expected high for today?
- What is the expected temperature?
- Will high temperatures be dangerous?
- Is it dangerously cold?
- When will the heat subside?
- Is it hot?
- Is it cold?
- How cold is it now?
- Will we have a cold day today?
- When will the cold subside?
- What highs are we expecting?
- What lows are we expecting?
- Is it warm?
- Is it chilly?
- What's the current temp in Celsius?
- What is the temperature in Fahrenheit?
conditions:
- Is it windy?
- Will it rain today?
- What are the chances for rain?
- Will we get snow?
- Are we expecting sunny conditions?
- Is it overcast?
- Will it be cloudy?
- How much rain will fall today?
- How much snow are we expecting?
- Is it windy outside?
- How much snow do we expect?
- Is the forecast calling for snow today?
- Will we see some sun?
- When will the rain subside?
- Is it cloudy?
- Is it sunny now?
- Will it rain?
- Will we have much snow?
- Are the winds dangerous?
- What is the expected snowfall today?
- Will it be dry?
- Will it be breezy?
- Will it be humid?
- What is today's expected humidity?
- Will the blizzard hit us?
- Is it drizzling?
classifier_params:
filter_sizes: [1]
hidden_size: 100
nb_filter: 150
min_class_confidence: 0.8
Переключение из 1 состояния в другое (а заодно — извлечение сущностей) в другое происходит так:
- классифицируем ввод. Извлекаем класс с наибольшим «сходством». Дописываем его имя перед пользовательским текстом. Например — «How cold in Moscow now?» преобразуется в «temperature How cold in Moscow now?»
- получаем дочерние узлы текущего узла (по умолчанию — main)
- для каждого потомка (по порядку):
- если он накладывает ограничения на класс — проверяем вхождение в класс, если не входит — переходим к следующему потомку
- если есть типы сущностей, упоминания которых нужно сохранить — проверяем вхождения всех возможных сущностей (и их синонимов) этого типа и сохраняем в словаре под соответствующим именем. Если найдены не все типы — переходим к следующему потомку. В процессе по «шаблону» {«city»: "$city"} из «what temperature expected in Moscow and Ottava» извлечется {"$city": [«Moscow», «Ottava»]}
Под капотом, часть 1
Ужасный код на bitbucket. Для начала — выделил такие сущности:
- Классификатор. С ним, вероятно, вроде всё понятно
- Сценарий. Содержит полные сведения о сценарии — дерево, список классов, список типов сущностей, список их эквивалентных наименований, etc. robot/script.py
- Узел дерева сценария. Содержит данные о 1 узле — шаблон текста, условия (включая класс и сущности), дочерние элементы. robot/script.py
- Состояние робота. Включает название текущего узла и выделенные из пользовательского ввода переменные. robot/robot_state.py
- Обработчик вывода. Может применяться, например для вывода значения переменной (print), перехода к другому узлу (goto). robot/output_processing.py
- Робот. Собственно, соединяет классификатор, сценарий и обработчик вывода. На входе имеет своё прошло состояние и текст, на выходе — новое состояние. robot/robot.py
Теперь возможно такое:
script = Script.load(os.path.join(os.path.dirname(__file__), "script.yaml"))
text_processor = TextProcessor("english",
[["turn", "on"], ["turn", "off"]],
Word2Vec.load_word2vec_format(
os.path.join(os.path.dirname(__file__), "100d.txt")
))
robot = Robot(script, text_processor)
state, output = robot.output()
self.assertEqual(output, "Hello. I'm weather robot. How can I help you?")
self.assertIsNotNone(state)
self.assertEqual(state.stage, "main")
self.assertEqual(state.variables, {})
state, output = robot.answer(state, "How cold it'll be in Moscow today?")
self.assertIsNotNone(state)
self.assertEqual(state.stage, "city_temperature")
self.assertEqual(state.variables, {"$city": ["Moscow"]})
self.assertEqual(output, "Temperature in Moscow is next.")
Уже можно пытаться что-нибудь запустить, но я пошёл дальше.
Обёртка вокруг robot и sqlalchemy. Пока без telegram
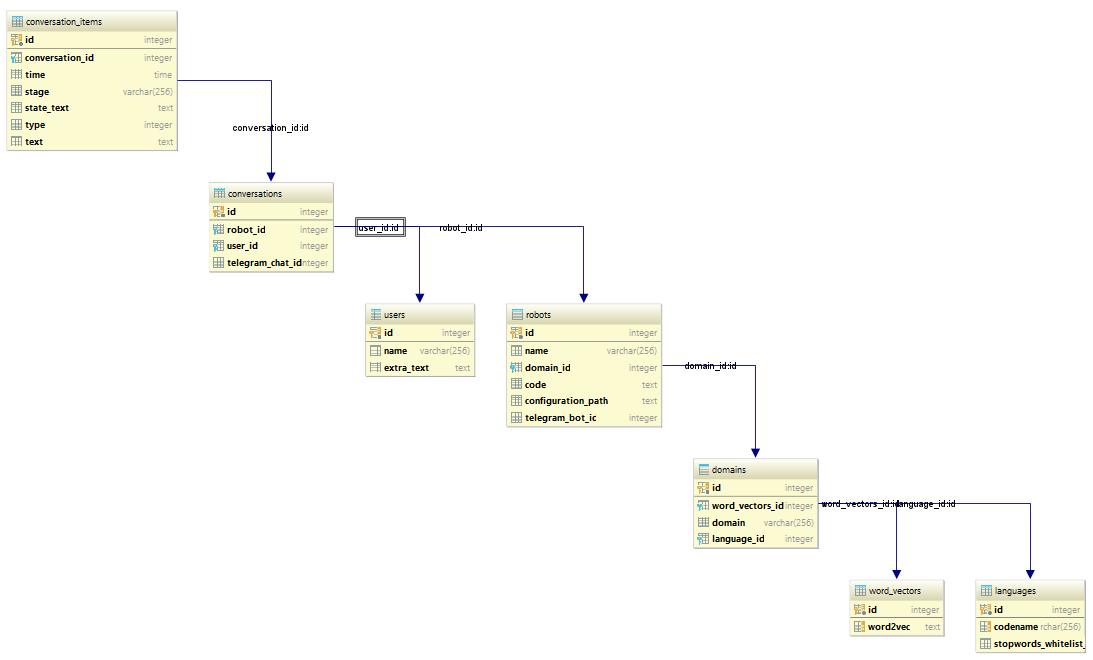
Ещё более ужасный код на bitbucket. Опять делим сущности:
- Язык. Содержит имя для nltk и набор исключений для вырезания стопслов. robotframework/models/language.py
- Предметная область. Содержит ссылку на язык и word2vec, который обучен на текстах нужной предметной области на этом языке (будет загружен в память при первом обращении и выгружен в случае, если уже загружено более заданного количества word2vec-в). robotframework/models/domain.py
- Робот. Содержит ссылку на предметную область, сценарий и ссылку на конфиг классификатора (опять же — классификатор ��удет создан по первому обращению. Если же классификатор не обучен — он будет предварительно обучен и сохранён. Выгрузится по превышении соответствующего параметра). robotframework/models/robot.py
- Пользователь. Всё что от него надо здесь — быть однозначно идентифицируемым. robotframework/models/user.py
- Диалог. Просто ссылается на юзера и робота. robotframework/models/conversation.py
- Запись диалога. Содержит свой источник (робот/пользователь), текст и состояние робота. robotframework/models/conversation_item.py
- Приложение — синглтон с всяческой технической функциональностью. Сейчас — инициализирует sqlalchemy
Как-то так:
Пример кода:
from robotframework import *
from sqlalchemy import select
app = Application({
'DATABASE_URI': '',
'KEEP_WORD_VECTORS': 4
})
robot = Robot.filter(lambda query: query.where(Robot.id == 1))[0]
user = User.filter(lambda query: query.where(User.id == 1))[0]
conversation = robot.converse(user)
#print(robot.instance)
items = lambda: print([str(item) for item in conversation.items])
items()
conversation.output()
conversation.answer('How hot it\'ll be in Moscow today?')
conversation.answer('Okay, turn off')
items()
Ну и в результате:
[]
["Hello. I'm weather robot. How can I help you?", "How hot it'll be in Moscow today", "Temperature in Moscow is next", ""]Последняя запись пуст��, т.к. в сценарии нет узла по которому можно перейти в этом случае.
В конфигурации — следующие опции:
{
'DATABASE_URI' : '', # URI для подлючения sqlalchemy к СУБД
'KEEP_WORD_VECTORS': 3, # одновременно хранится не более заданного числа "словарей" word2vec, иначе будет выгружен тот, к которому (относительно) давно не было обращений
'KEEP_ROBOTS': 3, # число хранимых одновременно роботов
'ROBOT_CONFIGURATIONS': 'robot_configurations', # директория, где хранятся конфигурации обученных роботов,
'OUTPUT_HANDLERS': {}
}
Теперь у нас вроде бы есть все средства для более или менее адекватного хранения роботов, их состояний и вспомогательных данных. И — возможность прикручивать их к различным мессенджерам (да и не только), прикрутив соответсвующую обёртку.
Telegram
Перед просмотром кода рекомендуется запастись успокоительными. Обёртка добавляет к моделям ещё пару полей (telegram_chat_id в Conversation, telegram_bot_id в Robot). Ну и многопоточность во все поля.
Вот пример:
import logging
from robotframework_telegram import RobotFrameworkTelegram
from config import config
if __name__ == '__main__':
bots = RobotFrameworkTelegram({
'DATABASE_URI': 'URI',
'KEEP_WORD_VECTORS': 3,
'ROBOT_CONFIGURATIONS': 'robot_configurations',
'KEEP_ROBOTS': 5,
'OUTPUT_HANDLERS': {},
'TOKENS': [
# Your tokens here
],
'NO_ANSWER_MESSAGE': 'Sorry, I can\'t answer now.',
'NO_INSTANCE_MESSAGE': 'Sorry, robot not instantiated yet. ' + \
'You\'ll get answer after instantiation - it can take few minutes',
'TELEGRAM_WORKERS_PER_BOT': 1,
'WORKER_COUNT': 2,
'WORKER_SLEEP_TIME': 0.2,
'LOGGER': logging,
})
bots.start_polling()
И диалог полученный при тесте
[7:14:55 AM] #:
/start
[7:14:56 AM] robotframework_demo_weather:
Sorry, robot not instantiated yet. You'll get answer after instantiation — it can take few minuutes
Hello. I'm weather robot. How can I help you?
[7:16:07 AM] #:
It's cold?
[7:16:08 AM] robotframework_demo_weather:
Okay, type city name.
[7:16:11 AM] #:
Moscow
[7:16:11 AM] robotframework_demo_weather:
Temperature in Moscow is next.
[7:40:25 AM] #:
/start
[7:40:26 AM] robotframework_demo_weather:
Hello. I'm weather robot. How can I help you?
[7:40:48 AM] #:
What is your destination, robot? Seems like you mustn't answer
[7:40:48 AM] robotframework_demo_weather:
Sorry, I can't answer now.

