Мне периодически приходится объяснять разным людям некоторые аспекты архитектуры Intel® IA-32, в том числе замысловатость системы адресации данных в памяти, которая, похоже, реализовала почти все когда-то придуманные идеи. Я решил оформить развёрнутый ответ в этой статье. Надеюсь, что он будет полезен ещё кому-нибудь.
При исполнении машинных инструкций считываются и записываются данные, которые могут находиться в нескольких местах: в регистрах самого процессора, в виде констант, закодированных в инструкции, а также в оперативной памяти. Если данные находятся в памяти, то их положение определяется некоторым числом — адресом. По ряду причин, которые, я надеюсь, станут понятными в процессе чтения этой статьи, исходный адрес, закодированный в инструкции, проходит через несколько преобразований.
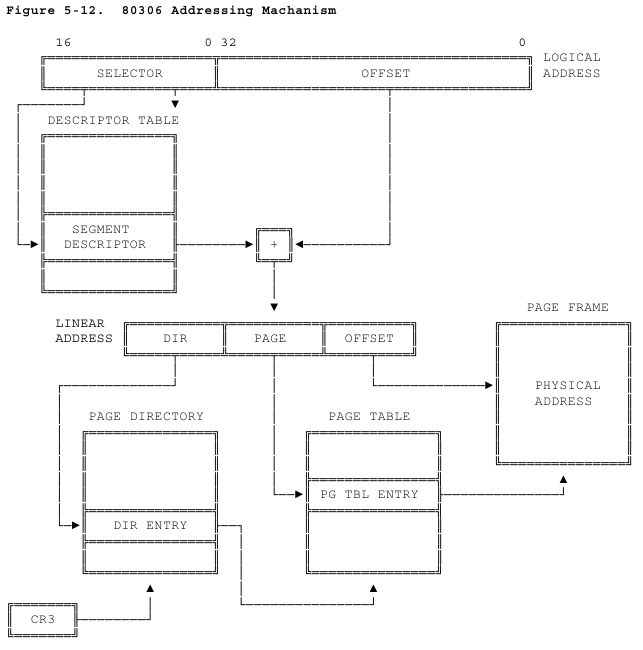
На рисунке — сегментация и страничное преобразование адреса, как они выглядели 27 лет назад. Иллюстрация из Intel 80386 Programmers's Reference Manual 1986 года. Забавно, что в описании рисунка есть аж две опечатки: «80306 Addressing Machanism». В наше время адрес подвергается более сложным преобразованиям, а иллюстрации больше не делают в псевдографике.
Начнём немного с конца — с цели всей цепочки преобразований.
Конечный результат всех преобразований других типов адресов, перечисленных далее в этой статье — физический адрес. На нём кончается работа внутри центрального процессора по преобразованию адресов.
Эффективный адрес — это начало пути. Он задаётся в аргументах индивидуальной машинной инструкции, и вычисляется из значений регистров, смещений и масштабирующих коэффициентов, заданных в ней явно или неявно.
Например, для инструкции (ассемблер в AT&T-нотации)
эффективный адрес операнда-назначения будет вычислен по формуле:
Без знания номера и параметров сегмента, в котором указан эффективный адрес, последний бесполезен. Сам сегмент выбирается ещё одним числом, именуемым селектором. Пара чисел, записываемая как
Здесь обычно у тех, кто столкнулся с этими понятиями впервые, голова начинает идти кругом. Несколько упростить (или усложнить) ситуацию помогает тот факт, что почти всегда выбор селектора (и связанного с ним сегмента) делается исходя из «смысла» доступа. По умолчанию, если в кодировке машинной инструкции не сказано иного, для получения адресов кода используются логические адреса с селектором CS, для данных — с DS, для стека — с SS.
Эффективный адрес — это смещение от начала сегмента — его базы. Если сложить базу и эффективный адрес, то получим число, называемое линейным адресом:
Преобразование логический → линейный не всегда может быть успешным, так как при его исполнении проверяется несколько условий на свойства сегмента, записанных в полях его дескриптора. Например, проверяется выход за границы сегмента и права доступа.
Сегментация была модной на некотором этапе развития вычислительной техники. В настоящее она почти всюду была заменена другими механизмами, и используется только для специфических задач. Так, в режиме IA-32e (64-битном) только два сегмента могут иметь ненулевую базу. Для остальных четырёх в этом режиме всегда линейный адрес == эффективный.
В литературе и в документации других архитектур встречается ещё один термин — виртуальный адрес. Он не используется в документации Intel на IA-32, однако встречается, например, в описании Intel® Itanium, в котором сегментация не используется. Можно смело считать, что для IA-32 виртуальный == линейный.
В советской литературе по вычислительной технике этот вид адресов также именовался математическим.
Следующее после сегментации преобразование адресов: линейный → физический — имеет множество вариаций в своём алгоритме, в зависимости от того, в каком режиме (32-битном, PAE или 64-битном) находится процессор.
Однако общая идея всегда одна и та же: линейный адрес разбивается на несколько частей, каждая из которых служит индексом в одной из системных таблиц, хранящихся в памяти. Записи в таблицах — это адреса начала таблицы следующего уровня или, для последнего уровня — искомая информация о физическом адресе страницы в памяти и её свойствах. Самые младшие биты не преобразуются, а используются для адресации внутри найденной страницы. Например, для режима PAE с размером страниц 4 кбайт преобразование выглядит так:

В разных режимах процессора различается число и ёмкость этих таблиц. Преобразование может завершиться неудачей, если очередная таблица не содержит валидных данных, или права доступа, хранящиеся в последней из них, запрещают доступ к странице; например, при записи в регионы, помеченные как «только для чтения», или попытке чтения памяти ядра из непривилегированного процесса.
До введения возможностей аппаратной виртуализации в процессорах Intel страничное преобразование было последним в цепочке. Когда же на одной системе работают несколько виртуальных машин, то физические адреса, получаемые в каждой из них, приходится транслировать ещё один раз. Это можно делать программным образом, или же аппаратно, если процессор поддерживает функциональность EPT (англ. Extended Page Table). Адрес, раньше называвшийся физическим, был переименован в гостевой физический для того, чтобы отличать его от настоящего физического. Они связаны с помощью EPT-преобразования. Алгоритм последнего схож с ранее описанным страничным преобразованием: набор связанных таблиц с общим корнем, последний уровень которых определяет, существует ли физическая страница для указанной гостевой физической.
Я попытался собрать все преобразования адреса в одну иллюстрацию. В ней преобразования обозначены стрелками, типы адресов обведены в рамки.

Как уже было сказано выше, каждое из преобразований может вернуть ошибку для адресов, не имеющих представления в следующем по цепочке виде. Устранение подобных проблем — это задача операционных систем и мониторов виртуальных машин, реализующих абстракцию виртуальной памяти.
Эволюция, что в природе, что в технике — странная вещь. Она порождает неожиданные структуры, необъяснимые с точки зрения рационального проектирования. Её творения полны атавизмов, правила их поведения иногда почти полностью состоят из исключений. Для того, чтобы понять работу такой системы, часто требуется прокрутить её эволюцию с самого начала, и под нагромождениями всех слоёв найти истину в виде принципа: «ничего не выбрасывать». Я склонен считать архитектуру IA-32 замечательным примером эволюционного развития.
Спасибо за внимание!
При исполнении машинных инструкций считываются и записываются данные, которые могут находиться в нескольких местах: в регистрах самого процессора, в виде констант, закодированных в инструкции, а также в оперативной памяти. Если данные находятся в памяти, то их положение определяется некоторым числом — адресом. По ряду причин, которые, я надеюсь, станут понятными в процессе чтения этой статьи, исходный адрес, закодированный в инструкции, проходит через несколько преобразований.
На рисунке — сегментация и страничное преобразование адреса, как они выглядели 27 лет назад. Иллюстрация из Intel 80386 Programmers's Reference Manual 1986 года. Забавно, что в описании рисунка есть аж две опечатки: «80306 Addressing Machanism». В наше время адрес подвергается более сложным преобразованиям, а иллюстрации больше не делают в псевдографике.
Начнём немного с конца — с цели всей цепочки преобразований.
Физический адрес
Конечный результат всех преобразований других типов адресов, перечисленных далее в этой статье — физический адрес. На нём кончается работа внутри центрального процессора по преобразованию адресов.
Конечный результат?!
На самом деле, легко понять, что это ещё не конец. В платформе, которая должна обработать запрос данных от процессора, может быть несколько чипов DRAM, имеющих собственную структуру разбиения на блоки, а также различные периферийные устройства, отображённые на общее пространство физической памяти. Дальнейший путь транзакции с некоторым физическим адресом будет зависеть от конфигурации нескольких декодеров, находящихся на её пути внутри устройств платформы.
Эффективный адрес
Эффективный адрес — это начало пути. Он задаётся в аргументах индивидуальной машинной инструкции, и вычисляется из значений регистров, смещений и масштабирующих коэффициентов, заданных в ней явно или неявно.
Например, для инструкции (ассемблер в AT&T-нотации)
addl %eax, 0x11(%ebp, %edx, 8)
эффективный адрес операнда-назначения будет вычислен по формуле:
eff_addr = EBP + EDX * 8 + 0x11
Логический адрес
Без знания номера и параметров сегмента, в котором указан эффективный адрес, последний бесполезен. Сам сегмент выбирается ещё одним числом, именуемым селектором. Пара чисел, записываемая как
selector:offset, получила имя логический адрес. Так как активные селекторы хранятся в группе специальных регистров, чаще всего вместо первого числа в паре записывается имя регистра, например, ds:0x11223344.Здесь обычно у тех, кто столкнулся с этими понятиями впервые, голова начинает идти кругом. Несколько упростить (или усложнить) ситуацию помогает тот факт, что почти всегда выбор селектора (и связанного с ним сегмента) делается исходя из «смысла» доступа. По умолчанию, если в кодировке машинной инструкции не сказано иного, для получения адресов кода используются логические адреса с селектором CS, для данных — с DS, для стека — с SS.
Линейный адрес
Эффективный адрес — это смещение от начала сегмента — его базы. Если сложить базу и эффективный адрес, то получим число, называемое линейным адресом:
lin_addr = segment.base + eff_addr
Преобразование логический → линейный не всегда может быть успешным, так как при его исполнении проверяется несколько условий на свойства сегмента, записанных в полях его дескриптора. Например, проверяется выход за границы сегмента и права доступа.
Реальный режим
Описанное выше верно при включенной сегментации. В 16-битном реальном режиме смысл селекторов другой, они хранят только базу, а преобразование не осуществляет сегментных проверок. Фактически, обозначения CS, DS, FS, GS, ES, SS имеют совершенно разный смысл в этих двух режимах, что добавляет путаницы.
Сегментация была модной на некотором этапе развития вычислительной техники. В настоящее она почти всюду была заменена другими механизмами, и используется только для специфических задач. Так, в режиме IA-32e (64-битном) только два сегмента могут иметь ненулевую базу. Для остальных четырёх в этом режиме всегда линейный адрес == эффективный.
Что такое виртуальный адрес?
В литературе и в документации других архитектур встречается ещё один термин — виртуальный адрес. Он не используется в документации Intel на IA-32, однако встречается, например, в описании Intel® Itanium, в котором сегментация не используется. Можно смело считать, что для IA-32 виртуальный == линейный.
В советской литературе по вычислительной технике этот вид адресов также именовался математическим.
Страничное преобразование
Следующее после сегментации преобразование адресов: линейный → физический — имеет множество вариаций в своём алгоритме, в зависимости от того, в каком режиме (32-битном, PAE или 64-битном) находится процессор.
Что влияет на paging
Примечательно, сколько различных бит из разных системных регистров процессора влияют на процесс страничного преобразования в настоящее время. Я просмотрел свежую сентябрьскую редакцию Intel SDM [1], и вот полный список: CR0.WP, CR0.PG, CR4.PSE, CR4.PAE, CR4.PGE, CR4.PCIDE, CR4.SMEP, CR4.SMAP, IA32_EFER.LME, IA32_EFER.NXE, EFLAGS.AC.
Однако общая идея всегда одна и та же: линейный адрес разбивается на несколько частей, каждая из которых служит индексом в одной из системных таблиц, хранящихся в памяти. Записи в таблицах — это адреса начала таблицы следующего уровня или, для последнего уровня — искомая информация о физическом адресе страницы в памяти и её свойствах. Самые младшие биты не преобразуются, а используются для адресации внутри найденной страницы. Например, для режима PAE с размером страниц 4 кбайт преобразование выглядит так:
В разных режимах процессора различается число и ёмкость этих таблиц. Преобразование может завершиться неудачей, если очередная таблица не содержит валидных данных, или права доступа, хранящиеся в последней из них, запрещают доступ к странице; например, при записи в регионы, помеченные как «только для чтения», или попытке чтения памяти ядра из непривилегированного процесса.
Гостевой физический
До введения возможностей аппаратной виртуализации в процессорах Intel страничное преобразование было последним в цепочке. Когда же на одной системе работают несколько виртуальных машин, то физические адреса, получаемые в каждой из них, приходится транслировать ещё один раз. Это можно делать программным образом, или же аппаратно, если процессор поддерживает функциональность EPT (англ. Extended Page Table). Адрес, раньше называвшийся физическим, был переименован в гостевой физический для того, чтобы отличать его от настоящего физического. Они связаны с помощью EPT-преобразования. Алгоритм последнего схож с ранее описанным страничным преобразованием: набор связанных таблиц с общим корнем, последний уровень которых определяет, существует ли физическая страница для указанной гостевой физической.
Полная картина
Я попытался собрать все преобразования адреса в одну иллюстрацию. В ней преобразования обозначены стрелками, типы адресов обведены в рамки.
Как уже было сказано выше, каждое из преобразований может вернуть ошибку для адресов, не имеющих представления в следующем по цепочке виде. Устранение подобных проблем — это задача операционных систем и мониторов виртуальных машин, реализующих абстракцию виртуальной памяти.
Заключение
Эволюция, что в природе, что в технике — странная вещь. Она порождает неожиданные структуры, необъяснимые с точки зрения рационального проектирования. Её творения полны атавизмов, правила их поведения иногда почти полностью состоят из исключений. Для того, чтобы понять работу такой системы, часто требуется прокрутить её эволюцию с самого начала, и под нагромождениями всех слоёв найти истину в виде принципа: «ничего не выбрасывать». Я склонен считать архитектуру IA-32 замечательным примером эволюционного развития.
P.S. Всё как у всех
Вскоре после завершения написания этой статьи я натолкнулся на презентацию об архитектуре IBM System z, которая примечательна в том числе своей долгой и интересной историей поддержки виртуализации. В этом документе нашлось перечисление всех типов адресов памяти, используемых в System z:
Как можно заметить, их тоже пять.
- Virtual: Translated by dynamic address translation (DAT) to real addresses
- Real: Translated to absolute addresses using the prefix register
- Absolute: After applying the prefix register
- Logical: The address seen by the program (this can either be a virtual or a real address)
- Physical: translated to absolute addresses by the Config Array
Как можно заметить, их тоже пять.
Спасибо за внимание!
Литература
- Intel Corporation. Intel® 64 and IA-32 Architectures Software Developer’s Manual. Volumes 1–3, 2014. www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html

