В первой части статьи мы рассмотрели основные отличия архитектуры потока данных (dataflow) от архитектуры потока управления (controlflow), совершили экскурсию в 1970-е, когда появились первые аппаратные dataflow-машины и сравнили статическую и динамическую потоковые модели вычислений. Сегодня я продолжу вас знакомить с dataflow-архитектурами. Добро пожаловать под кат!
В дополнение к вышесказанному: реализация циклов в динамических потоковых системах
Рассмотрим более подробно работу контекста на примере организации циклов. Напомню, контекст — это поле в структуре токена, однозначно определяющее экземпляр узла dataflow-графа. В случае с циклами контекстом будет являться номер итерации.
Пример 1. Числа Фибоначчи
Вычисление чисел Фибоначчи является класическим примером цикла с зависимостью итераций по данным. N-ное число равно сумме (N-1)-го и (N-2)-го:
int fib [MAX_I]; fib [0] = 1; fib [1] = 1; for (i = 2; i < MAX_I; i++) { fib [i] = fib [i-1] + fib [i-2]; }
Построим потоковый граф вычислений:
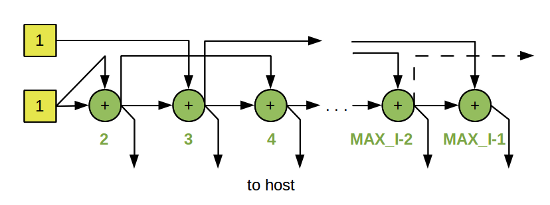
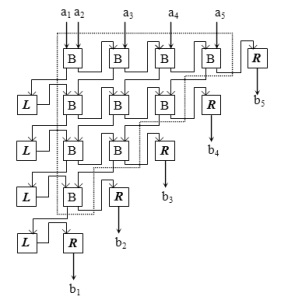
Легко видеть, что граф состоит из (MAX_I-2) одинаковых узлов, отличающихся только значениями контекста (цифры под изображением узла). Логика работы узла (в псевдокоде) будет выглядеть так:
узел fib (входы: токен A, токен B) переменная i = поле_контекста(A); переменная result = поле_данных(A) + поле_данных(B); отправить_токен (данное: result, метка: host, контекст: i); если (i < MAX_I-1) отправить_токен (данное: result, метка: fib, контекст: i+1); отправить_токен (данное: result, метка: fib, контекст: i+2); конец если конец узел fib
Для старта программы требуется отправисть три токена:
отправить_токен (данное: 1, метка: fib, контекст: 2); отправить_токен (данное: 1, метка: fib, контекст: 2); отправить_токен (данное: 1, метка: fib, контекст: 3);
В результате выполнения потоковой программы на хост будет отправлен набор токенов, каждый из которых в поле контекста будет нести номер числа Фибоначчи, а в поле данных — само число. Обратите внимание, еще один токен (отмечен на графе пунктирной линией) посылается «в никуда», точнее, никогда не запускает выполнения узла по причине отсутствия парного ему токена. Избавиться от него можно либо добавив еще одну проверку условия (i < MAX_I-2) в коде узла, либо организовав программный или аппаратный «сборщик мусора».
Пример 2. Сложение матриц
Рассмотрим теперь пример, где нет зависимости между итерациями по данным: сложение матриц
int A [MAX_I][MAX_J]; int B [MAX_I][MAX_J]; int C [MAX_I][MAX_J]; GetSomeData (A, B); for (i = 0; i < MAX_I; i++) for (j = 0; j < MAX_J; j++) { C[i,j] = A[i,j] + B[i,j]; }
Все (MAX_I*MAX_J) итераций могут быть выполнены одновременно. Вот так выглядит граф сложения матриц:

Контекст в данном случае представляет собой структуру из двух координат {i; j}. C учетом этого узел графа будет выглядеть так:
узел add (входы: токен A, токен B) переменная {i, j} = поле_контекста(A); переменная result = поле_данных(A) + поле_данных(B); отправить_токен (данное: result, метка: host, контекст: {i, j}); конец узел add
Обратите внимание, никаких проверок границ здесь нет! Число итераций автоматически выбирается исходя из размерности входных данных. Входные данные, кстати, должны поступать в таком виде:
отправить_токен (данное: A[0, 0], метка: add, контекст: {0, 0}); отправить_токен (данное: B[0, 0], метка: add, контекст: {0, 0}); отправить_токен (данное: A[0, 1], метка: add, контекст: {0, 1}); отправить_токен (данное: B[0, 1], метка: add, контекст: {0, 1}); ... отправить_токен (данное: A[MAX_I-1, MAX_J-1], метка: add, контекст: {MAX_I-1, MAX_J-1}); отправить_токен (данное: B[MAX_I-1, MAX_J-1], метка: add, контекст: {MAX_I-1, MAX_J-1});
Dataflow-системы очень эффективны для обработки разреженных данных, так как фактически пересылаются и обрабатываются только значимые элементы.
Гибридные dataflow-архитектуры
«Чистые» потоковые архитектуры, подобные описанным MIT Static Dataflow Machine и Manchester Dataflow Machine, к сожалению, имели много слабых мест:
- Dataflow-машины давали огромные возможности для параллелизма выполнения. Обратной стороной этого преимущества было то, что на последовательных участках вычислительного графа они показывали резкое падение производительности.
- Загрузка исполнительных устройств была далека от максимально возможной. Большая часть машинного времени тратилась на поиск соответствия операндов, выборку инструкций, а исполнительное устройство все это время простаивало, выполняя лишь по одной инструкции на каждую пару токенов.
- Трудным было конструирование устройств сопоставления. Ассоциативная память сложнее, дороже, медленнее, занимает больше места и потребляет больше энергии, по сравнению с обычной оперативной памятью такого же объема.
- Сам принцип управления потоком данных не позволял организовать эффективный конвейер. Почти все устройства работали асинхронно, требовались буферы и очереди в линиях связи.
- По сравнению с классической многопроцессорной архитектурой, в dataflow-машинах значительно выше была нагрузка на коммутационную сеть. Ведь фактически, каждая операция требовала пересылки двух токенов.
В попытках решить перечисленные проблемы стали появляться гибридные архитектуры, сочетающие в себе элементы как архитектур потока данных, так и потока управления.
Threaded dataflow
Этому термину нет вообще никакого адекватного перевода на русский. Суть данного подхода состоит в том, чтобы последовательные участки вычислительного графа, которые невозможно распараллелить, заменить тредами (threads) — наборами последовательно выполняемых инструкций. Сразу исчезают «лишние» промежуточные токены, и растет загрузка исполнительных устройств. Принципы threaded dataflow были воплощены «в железе» в процессоре Epsilon [21] в 1989 году.
Крупнозернистая архитектура потока данных
Дальнейшим развитием threaded dataflow стали так назыаемые крупнозернистые потоковые архитектуры (large-grain dataflow). Когда стало ясно, что параллелизм «чистого» dataflow во многих случаях избыточен, возникло решение строить потоковый граф не из отдельных операторов, а из блоков. Таким образом, в крупнозернистой архитектуре каждый узел представляет собой не одну инструкцию, а классическую последовательную программу. Взаимодействие между узлами по-прежнему осуществляется по принципу потока данных. Одним из преимуществ такого подхода стала возможность использовать в качестве исполнительных устройств обычные фон-неймановские процессоры. Следует отметить, что несмотря на название «крупнозернистая», блоки, на которые разбивается задача, все равно намного мельче, чем, скажем, в кластерных системах. Типичный размер блока составляет 10-100 инструкций и 16-1К байт данных.
Векторная dataflow-архитектура
В векторных потоковых системах токен содержит не одно значение, а сразу множество. Соответственно, и операции выполняются не над парами операндов, а над парами векторов. В качестве примера такой системы можно привести машину SIGMA-1 (1988) [22]. Иногда векторный режим поддерживается только частью исполнительных устройств системы. Часто также применяются гибридные архитектуры, объединяющие сразу несколько подходов, например крупнозернистая архитектура с возможностью выполнения векторных операций.
Реконфигурируемые системы
Развитие технологий ПЛИС сделало возможным принципиально новый подход к архитектуре dataflow. Что, если собрать машину, ориентированную на решение одной конкретной задачи? Если реализовать непосредственно на схемотехническом уровне нужный вычислительный граф, можно добиться потрясающих результатов. Вместо устройств сложных и медленных сопоставления можно использовать безусловное перенаправление данных от одного функционального модуля к другому. Сами исполнительные устройства тоже можно «заточить» под нужную задачу: выбрать тип арифметики, разрядность, нужный набор поддерживаемых операций.
Разумеется, подобная машина будет очень узкоспециализированной, но ведь достоинство ПЛИС как раз в возможности неоднократного перепрограммирования. Таким образом, под каждую отдельную задачу собирается нужная архитектура. Некоторые системы позволяют даже осуществлять перенастройку прямо в процессе работы. Реконфигурируемые системы на базе FPGA-микросхем в настоящее время выпускаются серийно в самых разных форматах — от блока «ускорителя» для ПК до системы производительностью порядка нескольких Тфлопс [31].
Из недостатков реконфигурируемых архитектур можно выделить следующие:
- Принципиальная однозадачность. Для запуска новой задачи требуется остановка системы и перепрограммирование ПЛИС, входящих в ее состав.
- Сложность программирования. Программирование каждой задачи включает в себя синтез всей вычислительной архитектуры под данную задачу.
- Избыточная аппаратная сложность. Обратной стороной гибкости ПЛИС является наличие на кристалле большого процента элементов, которые непосредственно не участвуют в вычислениях, а служат только для реконфигурации. Тем не менее, эти элементы потребляют энергию и выделяют тепло во время работы, что ухудшает энергетические показатели эффективности системы (Гфлопс/Вт).
Программирование под dataflow-архитектуры
Программирование в парадигме dataflow существенно отличается от привычного структурного, а ближе скорее к функциональному. Здесь нет переменных, массивов и других именованных областей памяти, нет вызываемых процедур и функций в привычном смысле этого слова. Потоковое программирование использует принцип однократного присваивания. Каждая единица данных (как правило, это токен) получает значение только один раз, при создании, и в дальнейшем может быть только прочитана. Этот принцип отражает однонаправленность ветвей вычислительного графа.
В dataflow, к сожалению, так и не выработался какой-либо стандарт программирования. Обычно под каждую архитектуру разрабатывается свой язык. Расскажу о нескольких наиболее известных.
VAL
VAL (Value-oriented Algorithmic Language)[41] был разработан в Массачусетском технологическом институте (MIT) в 1979 году специально для MIT Dataflow Machine. Вот как выглядит, к примеру, вычисление факториала на VAL:
for Y:integer := 1; P:integer := N; do if P ~= 1 then iter Y := Y*P; P := P-1; enditer; else Y endif endfor
SISAL
SISAL (Streams and Iteration in a Single Assignment Language)[42], появившийся в 1983 году, является дальнейшим развитием VAL. В отличие от VAL, SISAL позволяет использовать рекурсию.
Вычисление факториала:
function factorial( n : integer returns integer ) if n <=1 then 1 else n * factorial( n - 1 ) end if end function
Вариант без рекурсии от хабраюзера middle:
function factorial (n : integer returns integer) for i in 1, n returns value of prod i end for end function
Id
Id [43] — параллельный язык общего назначения, создан в конце 1970-х — начале 1980-х годов в MIT. Дальнейшая работа над Id привела к развитию языка pH — параллельного диалекта Haskell'а.
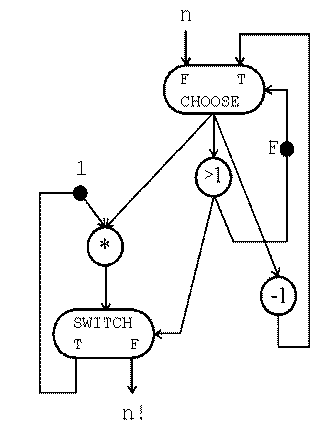
Факториал на Id:
( initial j <- n; k <- 1 while j > 1 do new j <- j - 1; new k <- k * j; return k )
А граф вычислений для данной программы будет выглядеть так:
Lucid
Язык Lucid [44][45] разработан в 1976 Биллом Уэйджем (Bill Wadge) и Эдом Эшкрофтом (Ed Ashcroft). Оперирует понятиями потоков значений (аналог переменных) и фильтров, или преобразователей (аналог функций).
Факториал на Lucid:
fac where n = 0 fby (n + 1); fac = 1 fby ( fac * (n + 1) ); end
Quil
Quil (2010) [46] — язык, основанный на Lucid, в настоящее время работа над ним продолжается. На сайте языка есть онлайн-интерпретатор, так что написать вычисление факториала на Quil оставляю как самостоятельное задание читателям.
Заключение
«Бум» потоковых архитектур пришелся на 1970-80-е годы, потом интерес к dataflow постепенно угасал. В наши дни элементы потоковых вычислителей можно встретить в архитектуре DSP (сигнальных процессоров), сетевых маршрутизаторов и графических процессоров. Но постепенно все большее число специалистов вновь обращаются к парадигме dataflow в рамках высокопроизводительных вычислений. Вероятно, это можно связать с тем, что сегодня фон-неймановская архитектура подходит к своему пределу масштабируемости, и для дальнейшего повышения производительности требуются новые подходы.
Несколько особняком стоят реконфигурируемые архитектуры, в которых постепенно стирается грань между программной и аппаратной частью. За какой технологией будущее? Вопрос остается открытым.
Bonus Game. Самым любознательным из читателей предлагаю попытаться определить, графы каких алгоритмов изображены на «картинках для привлечения внимания» в заголовке каждой части статьи. Удачи!
Литература
Нумерация источников продолжается с первой части.
Гибридные dataflow-системы
[21] — The Epsilon dataflow processor, V.G. Grafe, G.S. Davidson and others.
[22] — Efficient vector processing on dataflow supercomputer SIGMA-1, K. Hiraki, S. Sekiguchi, T. Shimada.
Реконфигурируемые системы
[31] — Семейство многопроцессорных вычислительных систем с динамически перестраиваемой архитектурой, Н.Н. Дмитриенко, И.А. Каляев и другие.
[32] — Dynamically Reconfigurable Dataflow Architecture for High-Performance Digital Signal Processing on Multi-FPGA Platforms, Voigt, S.-O., Teufel, T.
Языки программирования dataflow-систем
[41] — VAL — A Value-oriented Algorithmic Language
[42] — Sisal Language Tutorial
[43] — ID Language Reference Manual, Rishiyur S. Nikhil, 1991
[44] — LUCID, the dataflow programming language, Academic Press Professional, Inc. San Diego, CA, USA 1985 ISBN:0-12-729650-6
[45] — Fluid Programming in Lucid
[46] — The Quil Language

