На Хабре было мало постов про Форт, и впечатленный недавней великолепной работой Мура, расскажу о другом форт-процессоре — J1.
Это, наверное, самый минималистичный процессор, которому можно найти практическое применение.
Его можно сделать самому на FPGA, но я, как человек далекий от электроники, попробую написать его эмулятор. И, чтобы добавить ненормальности посту, писать эмулятор буду на языке Go.
Процессор 16-разрядный, может адресовать до 32Кб памяти (почему не 64Кб поймете ниже). Код и данные находятся в разных областях памяти, максимальный размер программы, выполняемой на этом процессоре — тоже до 32Кб.
Архитектура стековая, ни одного регистра (к которым можно было бы явно обратиться) процессор не содержит. Зато содержит два стека:
— стек с данными — предназначен для вычислений
— стек вызовов — предназначен для сохранения адреса возврата при вызове функций. Иногда используется как временное хранилище.
Оба стека неглубокие, по 33 элемента. Стеки разумеется тоже 16-разрядные.
Это все. Вместо портов ввода-вывода предлагается использовать memory-mapped I/O. Для этого рекомендуют зарезервировать верхние 16Кб памяти.
Я не претендую на идеологически правильный код на Go, но постараюсь чтобы людям даже незнакомым с языком было понятно о чем речь.
Опишем структуру процессора:
Итого, у нашего эмулируемого процессора внутри есть счетчик инструкций pc, стек данных s, стек вызовов r, указатели на вершины этих стеков sp и rp соответственно и внутренняя память (память кстати тоже только 16-разрядная, т.к. к байту обратиться нельзя).
Напишем функцию-конструктор для типа J1Cpu:
В конструкторе выделяем памяти столько, сколько указано, и инициализируем стеки.
У процессора 5 инструкций:
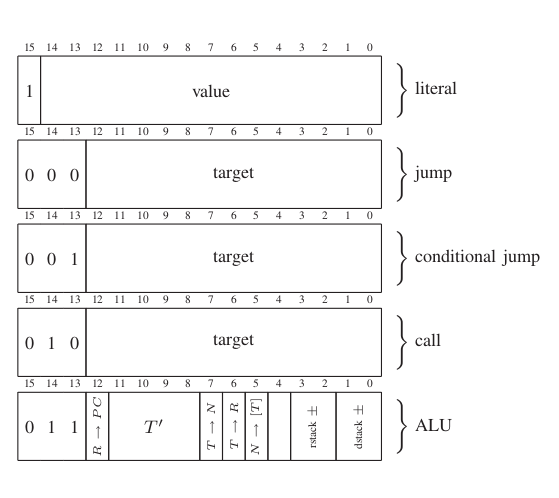
Работают они следующим образом:
LIT X: положить на вершину стека s значение X. Поскольку 1-й бит указывает на то, что это литерал, то на значение отводится только 15 бит. Отсюда 15-битная адресация кода и данных.
JMP X: перейти к адресу X
JZ X: если на вершине стека s находится значение 0, то перейти к адресу Х
CALL X: положить на вершину стека r значение PC+1 (следующая инструкция), и перейти к адресу X.
ALU: тут немного сложнее, о ней расскажу ниже.
Реализуем выполнение этих инструкций в методе Exec:
Изменяя указатели на вершину стека я использую пре-инкремент и пост-декремент. Однако, в Go нельзя их использовать как в C (stack[++sp] = x;… x = stack[sp--]). Потому что указывать такие штуки нужно явно.
Осталось реализовать метод execAlu — и дело сделано!
Это самая мощная инструкция. Давайте сначала определимся с символами, которые используют авторы процессора.
T — элемент на вершине стека вначале выполнения инструкции
N — элемент, следующий за T вначале выполнения инструкции
T' — результат арифметических действий
R — элемент на вершине стека вызовов вначале выполнения инструкции
PC — значение счеткика инструкций процессора
[T] — косвенное обращение к памяти по адресу T
Арифметических инструкций всего 16:
0: T' = T
1: T' = N
2: T' = T + N
3: T' = T and N
4: T' = T or N
5: T' = T xor N
6: T' = ~T (побитовое инвертирование)
7: T' = (T == N)
8: T' = (N < T)
9: T' = N >> T (сдвиг вправо на T бит)
10: T' = T-1
11: T' = R
12: T' = [T]
13: T' = N << T
14: T' = depth (глубина стека данных)
15: T' = (N < T), на этот раз беззнаковое сравнение (unsigned)
Вот как будет выглядеть реализация этих операций:
Функция получилась такой большой потому я не очень оптимально разбираю параметры команды. В общих словах работает она просто — получает текущие значения T, N, R, вычисляет новое значение T', смещает указатели на вершину стеков и устанавливает новое значение T.
Вот теперь это точно все что умеет процессор.
Например, сложение двух чисел — это три комманды
LIT 5 (на стеке — 5)
LIT 7 (на стеке — 5 7)
ALU OP=2(сложение), DS=-1 (т.е. сложить и указатель стека уменьшить на 1. На стеке — 12).
Интересно то, что для выхода из функции не требуется отдельной инструкции. Просто в последней инструкции добавляется флаг «R->PC». Это по словам разработчиков сокращает объем кода примерно на 7%.
Дело в том, что этот набор инструкций оптимизирован именно для языка Форт. Большая часть слов этого языка соответствуют одиночным инструкциям J1. Но краткое введение в Форт применительно к процессору J1 будет в следующей статье, а сейчас оставлю ссылку на полные исходники эмулятора.
Кто уже знает форт — кросс-компилатор для J1 можно найти здесь (crossj1.fs).
Это, наверное, самый минималистичный процессор, которому можно найти практическое применение.
Его можно сделать самому на FPGA, но я, как человек далекий от электроники, попробую написать его эмулятор. И, чтобы добавить ненормальности посту, писать эмулятор буду на языке Go.
Аппаратные особенности
Процессор 16-разрядный, может адресовать до 32Кб памяти (почему не 64Кб поймете ниже). Код и данные находятся в разных областях памяти, максимальный размер программы, выполняемой на этом процессоре — тоже до 32Кб.
Архитектура стековая, ни одного регистра (к которым можно было бы явно обратиться) процессор не содержит. Зато содержит два стека:
— стек с данными — предназначен для вычислений
— стек вызовов — предназначен для сохранения адреса возврата при вызове функций. Иногда используется как временное хранилище.
Оба стека неглубокие, по 33 элемента. Стеки разумеется тоже 16-разрядные.
Это все. Вместо портов ввода-вывода предлагается использовать memory-mapped I/O. Для этого рекомендуют зарезервировать верхние 16Кб памяти.
Эмулятор
Я не претендую на идеологически правильный код на Go, но постараюсь чтобы людям даже незнакомым с языком было понятно о чем речь.
Опишем структуру процессора:
type J1Stack [33]uint16
type J1Cpu struct {
pc uint16
r J1Stack
s J1Stack
rp int
sp int
mem []uint16
}
Итого, у нашего эмулируемого процессора внутри есть счетчик инструкций pc, стек данных s, стек вызовов r, указатели на вершины этих стеков sp и rp соответственно и внутренняя память (память кстати тоже только 16-разрядная, т.к. к байту обратиться нельзя).
Напишем функцию-конструктор для типа J1Cpu:
func NewJ1Cpu(memSize int) (j1 *J1Cpu) {
j1 = new(J1Cpu)
j1.mem = make([]uint16, memSize)
j1.sp, j1.rp = -1, -1
return j1
}
В конструкторе выделяем памяти столько, сколько указано, и инициализируем стеки.
Инструкции
У процессора 5 инструкций:
Работают они следующим образом:
LIT X: положить на вершину стека s значение X. Поскольку 1-й бит указывает на то, что это литерал, то на значение отводится только 15 бит. Отсюда 15-битная адресация кода и данных.
JMP X: перейти к адресу X
JZ X: если на вершине стека s находится значение 0, то перейти к адресу Х
CALL X: положить на вершину стека r значение PC+1 (следующая инструкция), и перейти к адресу X.
ALU: тут немного сложнее, о ней расскажу ниже.
Реализуем выполнение этих инструкций в методе Exec:
const (
J1_OP = (7 << 13)
J1_ARG = 0x1fff
J1_JMP = (0 << 13)
J1_JZ = (1 << 13)
J1_CALL = (2 << 13)
J1_ALU = (3 << 13)
J1_LIT = (4 << 13)
J1_LIT_MASK = 0x7fff
)
func (j1 *J1Cpu) Exec(op uint16) {
if op & J1_LIT != 0 {
j1.sp++
j1.s[j1.sp] = op & J1_LIT_MASK
j1.pc++
return
}
arg := op & J1_ARG
switch op & J1_OP {
case J1_JMP:
j1.pc = arg
case J1_JZ:
if j1.s[j1.sp] == 0 {
j1.pc = arg
}
j1.sp--
case J1_CALL:
j1.rp++
j1.r[j1.rp] = j1.pc + 1
j1.pc = arg
case J1_ALU:
j1.execAlu(arg)
}
}
Изменяя указатели на вершину стека я использую пре-инкремент и пост-декремент. Однако, в Go нельзя их использовать как в C (stack[++sp] = x;… x = stack[sp--]). Потому что указывать такие штуки нужно явно.
Осталось реализовать метод execAlu — и дело сделано!
J1 ALU
Это самая мощная инструкция. Давайте сначала определимся с символами, которые используют авторы процессора.
T — элемент на вершине стека вначале выполнения инструкции
N — элемент, следующий за T вначале выполнения инструкции
T' — результат арифметических действий
R — элемент на вершине стека вызовов вначале выполнения инструкции
PC — значение счеткика инструкций процессора
[T] — косвенное обращение к памяти по адресу T
Арифметических инструкций всего 16:
0: T' = T
1: T' = N
2: T' = T + N
3: T' = T and N
4: T' = T or N
5: T' = T xor N
6: T' = ~T (побитовое инвертирование)
7: T' = (T == N)
8: T' = (N < T)
9: T' = N >> T (сдвиг вправо на T бит)
10: T' = T-1
11: T' = R
12: T' = [T]
13: T' = N << T
14: T' = depth (глубина стека данных)
15: T' = (N < T), на этот раз беззнаковое сравнение (unsigned)
Вот как будет выглядеть реализация этих операций:
func (j1 *J1Cpu) execAlu(op uint16) {
var res, t, n, r uint16
if j1.sp >= 0 {
t = j1.s[j1.sp]
}
if j1.sp > 0 {
n = j1.s[j1.sp-1]
}
if j1.rp > 0 {
r = j1.r[j1.rp-1]
}
j1.pc++
code := (op & (0xf << 8)) >> 8
switch code {
case 0:
res = t
case 1:
res = n
case 2:
res = t + n
case 3:
res = t & n
case 4:
res = t | n
case 5:
res = t ^ n
case 6:
res = ^t
case 7:
if n == t {
res = 1
}
case 8:
if int16(n) < int16(t) {
res = 1
}
case 9:
res = n >> t
case 10:
res = t - 1
case 11:
res = j1.r[r]
case 12:
res = j1.mem[t]
case 13:
res = n << t
case 14:
res = uint16(j1.sp + 1)
case 15:
if n < t {
res = 1
}
}
ds := op & 3
rs := (op & (3 << 2)) >> 2
if ds == 1 {
j1.sp++
}
if ds == 2 {
j1.sp--
}
if rs == 1 {
j1.rp++
}
if rs == 2 {
j1.rp--
}
if op&(1<<5) != 0 {
println("N->[T]")
j1.mem[t] = n
}
if op&(1<<6) != 0 {
println("T->R")
if j1.rp < 0 {
panic("Call stack underrun")
}
j1.r[j1.rp] = t
}
if op&(1<<7) != 0 {
println("T->N")
if j1.sp > 0 {
j1.s[j1.sp-1] = t
}
}
if op&(1<<12) != 0 {
println("R->PC")
j1.pc = j1.r[r]
}
if j1.sp >= 0 {
j1.s[j1.sp] = res
}
}
Функция получилась такой большой потому я не очень оптимально разбираю параметры команды. В общих словах работает она просто — получает текущие значения T, N, R, вычисляет новое значение T', смещает указатели на вершину стеков и устанавливает новое значение T.
Вот теперь это точно все что умеет процессор.
Например, сложение двух чисел — это три комманды
LIT 5 (на стеке — 5)
LIT 7 (на стеке — 5 7)
ALU OP=2(сложение), DS=-1 (т.е. сложить и указатель стека уменьшить на 1. На стеке — 12).
Интересно то, что для выхода из функции не требуется отдельной инструкции. Просто в последней инструкции добавляется флаг «R->PC». Это по словам разработчиков сокращает объем кода примерно на 7%.
А причем тут собственно Forth?
Дело в том, что этот набор инструкций оптимизирован именно для языка Форт. Большая часть слов этого языка соответствуют одиночным инструкциям J1. Но краткое введение в Форт применительно к процессору J1 будет в следующей статье, а сейчас оставлю ссылку на полные исходники эмулятора.
Кто уже знает форт — кросс-компилатор для J1 можно найти здесь (crossj1.fs).

