Введение
В этом посте мы рассмотрим производительность горутин (goroutine). Горутины — это нечто в роде очень дешевых и легковесных потоков. Больше всего, наверное, они похожи на процессы в Erlang.
Согласно документации мы можем использовать сотни тысяч горутин в наших программах. И цель статьи — проверить и конкретизировать это.
Память
Размер памяти, выделяемой для горутины, не документирован (говорится только, что это несколько килобайт), но тесты на разных машинах и множество подтверждений в интернете позволяет уточнить это число до 4 — 4,5 килобайт. То есть 5 Гб вам с запасом хватит на 1 миллион горутин.
Производительность
Остается определиться с тем, сколько процессорного времени мы теряем, когда выделяем код в горутину. Напомню, что для это только нужно поставить ключевое слово go перед вызовом функции.
go testFunc()Горутины — это в первую очередь средства достижения многозадачности. По умолчанию, если в системе не установлена переменная GOMAXPROCS, программа использует только один поток. Чтобы задействовать все ядра процессора, нужно записать в нее их количество: export GOMAXPROCS=2. Переменная считывается во время исполнения, так что перекомпилировывать программу после каждого её изменения не придётся.
Получается, время затрачивается на создание горутин, переключение между ними, а еще иногда на перемещение в другой поток и передачу сообщений между горутинами в разных потоках. Чтобы избежать последнего, начнём тестирование только с одного потока.
Все действия производятся на неттопе с:
- Atom D525 Dual Core 1.8 GHz
- 4Gb DDR3
- Go r60.3
- Arch Linux x86_64
Методика
Вот генератор исследуемых функций:
func genTest (n int) func (res chan <- interface {}) {
return func(res chan <- interface {}) {
for i := 0; i < n; i++ {
math.Sqrt(13)
}
res <- true
}
}А вот набор полученный функций, вычилсяющих корень из 13 по 1, 10, 100, 1000 и 5000 раз соответственно:
testFuncs := [] func (chan <- interface {}) { genTest(1), genTest(10), genTest(100), genTest(1000), genTest(5000) } Теперь, каждую функцию я запускаю X раз в цикле, а потом в X горутинах. А затем сравниваю затраченное время. Кроме того не стоит забывать про сборку мусора. Чтобы минимизировать влияние на результаты, я явно вызываю её после того, как отработают все горутины и только потом отмечаю конец операции.
Ну и, разумеется, для точности каждый тест проводится много раз. Общее время выполнения программы заняло около 16 часов.
Один поток
export GOMAXPROCS=1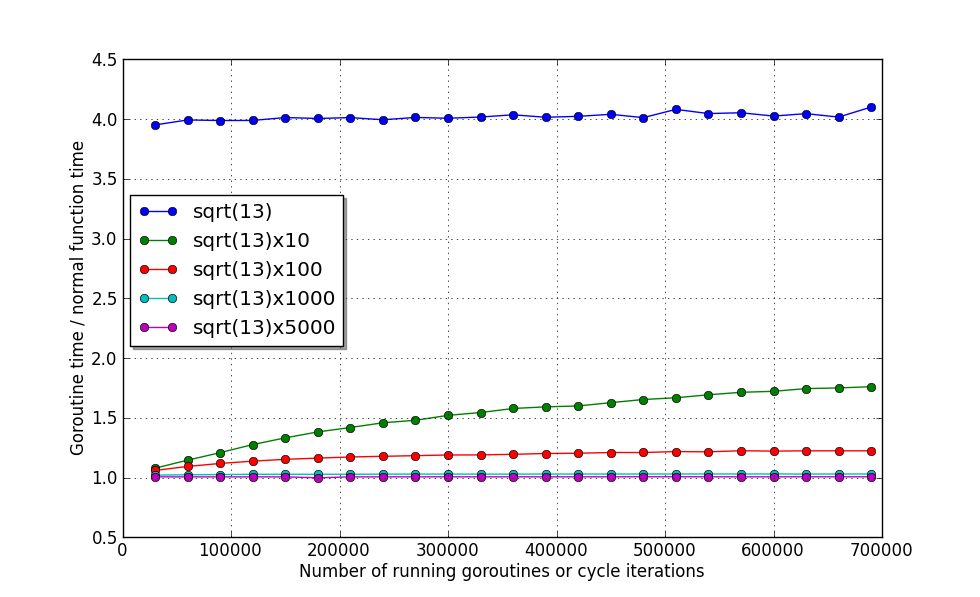
Из графика видно, что функция, время выполнения которой примерно равно вычислению корня, при выделении в горутину потратит примерно в 4 раза больше времени.
Рассмотрим 4 оставшиеся функции по-подробнее:

Видно, что даже при 700 тысячах одновременно работающих горутин производительность не падает больше чем на 80%. Самое классное, что уже при времени работы функции примерно равном вычислению sqrt(13) 1000 раз, оверхед составляет всего лишь ~2%. А при 5000 раз — всего 1%! И эти значения, похоже, практически не зависят от количества работающих горутин! То есть единственное ограничение — память.
Вывод:
Если независимый участок кода будет выполняться (включая время ожидания) больше чем вычисление 10 корней, и вы хотите выполнить его параллельно, то смело выделяйте его в горутину. Хотя если безболезненно удастся собрать вместе 10 или даже 100 таких участков, то потери производительности составят всего 20% или 2% соответственно.
Несколько потоков
Теперь рассмотрим ситуацию, когда мы хотим использовать сразу несколько ядер процессора. В моём случае их всего 2:
export GOMAXPROCS=2Теперь выполним тестирующую программу снова:
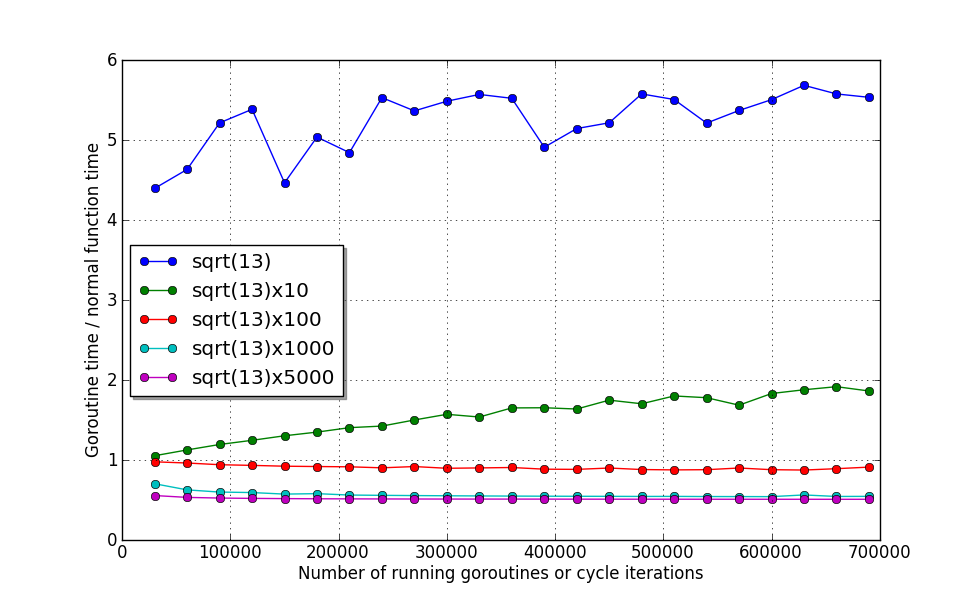
Тут хорошо видно, что несмотря на то, что количество ядер удвоилось, время работы первых двух функций — наоборот ухудшилось! Пускай и незначительно. Это объясняется тем, что затраты на перенос их в другой поток больше, чем на выполнение :)
Пока планировщик не может разруливать подобные ситуации, но авторы Go обещают в будущем исправить такую недоработку.
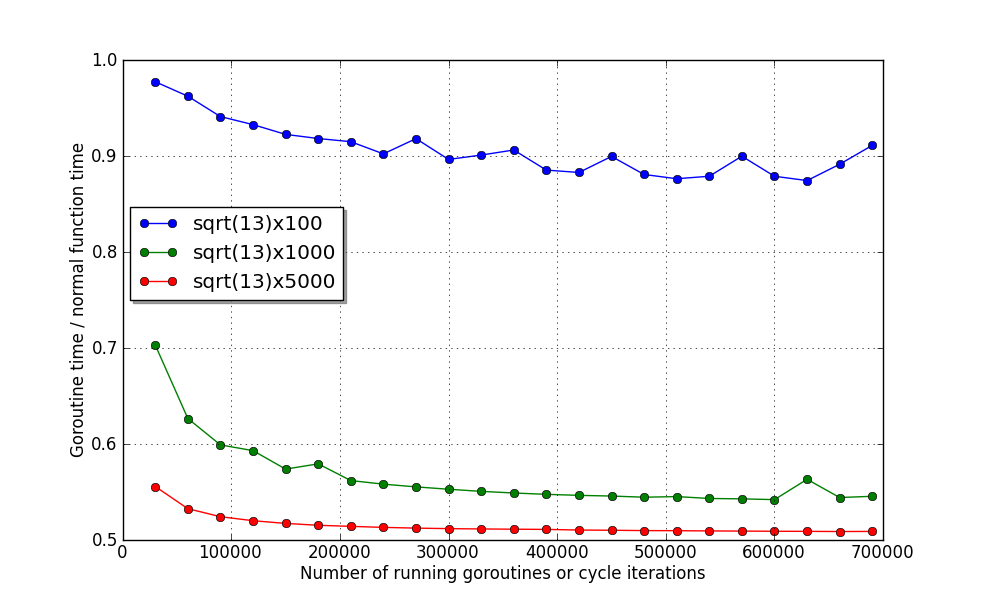
А вот тут можно рассмотреть, что последние две функции используют оба ядра почти на полную катушку. На моём неттопе, каждая отдельная функция выполняется за ~45мкс и ~230мкс соответственно.
Заключение
Даже несмотря на молодость языка и временную недостаточно хорошую реализацию планировщика, производительность очень радует. Особенно в сочетании с простотой использования.
В качестве совета могу предложить стараться не использовать в качестве горутин функции работающие меньше 1 микросекунды. И смело использовать работающие больше 1 миллисекунды :)
P.S. Было бы хорошо увидеть аналогичные тесты на других языках, например на эрланге. Википедия сообщает об успешных попытках запускать на нём до 20 миллионов процессов!
