 Для определения страны по IP необходимы специальные базы данных, состоящие из диапазонов IP адресов и соответствующих им стран. Обычно такие базы данных распространяются в виде CSV или SQL файлов для использования в СУБД, либо бинарных файлов специального формата.
Для определения страны по IP необходимы специальные базы данных, состоящие из диапазонов IP адресов и соответствующих им стран. Обычно такие базы данных распространяются в виде CSV или SQL файлов для использования в СУБД, либо бинарных файлов специального формата.Для проведения тестирования была выбрана февральская база GeoLite Country, бесплатная версия GeoIP Country от MaxMind.
В тестировании приняли участие несколько популярных решений и мой «велосипед» на эту тему.
Участники тестирования
MySQL
В качестве подопытной СУБД будет использоваться MySQL. В которой создана таблица, состоящая из IP-диапазонов и номеров стран, IP преобразованы в integer и по ним построены индексы. Структура таблицы выглядит так:
CREATE TABLE `ip2country ` ( `ipn1` INT(10) UNSIGNED NOT NULL, `ipn2` INT(10) UNSIGNED NOT NULL, `num` TINYINT(3) UNSIGNED NOT NULL, PRIMARY KEY (`ipn1`), INDEX `ipn2` (`ipn2`) ) ENGINE=MyISAM;
Для MySQL будут протестированы 3 запроса.
- Simple.
SELECT `num` FROM `ip2country` WHERE `ipn1` <= INET_ATON(' IP ') AND `ipn2` >= INET_ATON('IP') - Between.
SELECT num FROM `ip2country` WHERE INET_ATON('IP') BETWEEN `ipn1` AND `ipn2` - Subselect.
SELECT num FROM (SELECT * FROM ip2country WHERE `ipn1` <= INET_ATON('IP') ORDER BY `ipn1` DESC LIMIT 1) AS t WHERE `ipn2` >= INET_ATON('IP')
GeoIP API
Для GeoIP будет использоваться родное API для PHP, и база данных в бинарном формате. Тестироваться он будет в двух режимах:- Standart — режим по умолчанию.
- Memory — кэширование базы в памяти.
SxGeo v2
Немного слов о моем «велосипеде». Лет 6 назад, после изучения доступных на тот момент решений определения страны по IP, был впечатлен скоростью бинарного формата GeoIP. Но у него, как мне показалось, был недостаток в большом количестве перемещений по файлу для нахождения нужного IP. Появилась интересная идея по поводу своей реализации. Которая довольно быстро была реализована и, на удивление, оказалась значительно быстрее, чем я ожидал. Долгое время Sypex Geo использовался в своих проектах.На днях решил реализовать еще некоторые идеи по оптимизации. В итоге появилась версия Sypex Geo 2 (сокращено SxGeo). Файл с базой данных стал на 25% меньше, чем у первой версии, и при этом скорость увеличилась в 1,7-2 раза.
Основные преимущества перед GeoIP и другими решениями.
- Маленький размер базы чуть больше 4 байт на диапазон. К примеру, бинарная база GeoIP весит 1,2 МБ, у SxGeo 2 – 0.62 МБ.
- Очень высокая скорость обработки (смотрим результаты тестирования).
- Минимальное количество чтений с диска (3 + 1*N, где N – количество IP).
- Дополнительные режимы для пакетной обработки.
- File – обычный режим, рекомендуемый для одиночной обработки IP.
- Batch – режим пакетной обработки, предназначен для обработки множества IP адресов за раз.
- Batch + Memory – в этом режиме дополнительно используется кэш базы в памяти. Самый быстрый режим, но требует больше памяти, т.к. весь файл с базой загружается в память.
Geobaza
Также вне конкурса был протестирован алгоритм Geobaza. Вне конкурса, потому что использовался родной бинарный файл, со значительно большим количеством диапазонов. Geobaza показала около 2000-3000 IP/сек, был очень большой разброс по результатам. Если создатели Geobaza прочитают эту статью и пришлют файл, сгенерированный по февральскому GeoLite Country, то с удовольствием добавлю в тестирование.Тестирование
Для тестирования был написан PHP-скрипт, в котором при каждом запуске генерился массив из 10000 случайных IP-адресов. После чего все алгоритмы проверялись на этом массиве. Такой метод тестирования был выбран для того, чтобы алгоритмы были в равных условиях.
Тестилось на серваке под управлением FreeBSD 8 и PHP 5.2.17. Также тестилось на локалке Win 7 x64, PHP 5.3.9, пропорции примерно те же, поэтому в таблицах представлены только результаты FreeBSD.
Тест прогонялся 10 раз, усредненные данные приведены на графике.
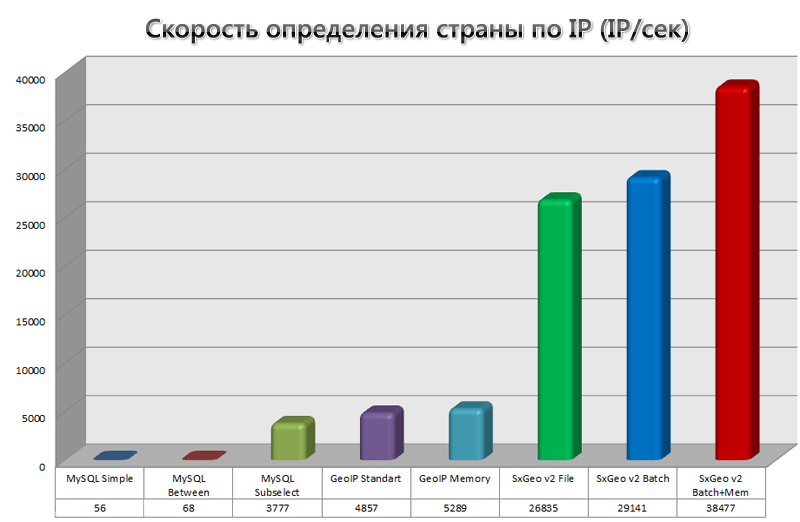
Самыми медленными оказались простые запросы MySQL. Причина столь медленной работы становится очевидной, если посмотреть EXPLAIN этих запросов.
EXPLAIN SELECT num FROM `ip2country` WHERE ipn1 <= INET_ATON('88.88.88.88') AND ipn2 >= INET_ATON('88.88.88.88') LIMIT 1;
id select_type table type possible_keys key key_len ref rows Extra 1 SIMPLE ip2country range PRIMARY PRIMARY 4 NULL 51059 Using where 1 SIMPLE ip2country range PRIMARY PRIMARY 4 NULL 53852 Using where 1 SIMPLE ip2country range PRIMARY,ipn2 PRIMARY 4 NULL 51587 Using where
Первый результат простого индекса PRIMARY KEY (`ipn1`), второй для составного индекса PRIMARY KEY (`ipn1`, `ipn2`), третий для двух индексов PRIMARY KEY (`ipn1`), INDEX `ipn2` (`ipn2`). Как видим для составного индекса строк для последующего перебора больше, чем в других случаях. Я же тестил без LIMIT 1, и в этом случае EXPLAIN пишет, что индекс не используется, хотя реально работает такой вариант быстрее, чем с LIMIT.
Вариант с вложенным SELECT — значительно быстрее. Запрос показывает, что индексы в MySQL, когда они нормально используются, работают очень быстро, приближаясь к специализированным бинарным форматам.
GeoIP показал, что его всё же использовать предпочтительнее, чем MySQL. Меня смутило, что использование кэширования в памяти дает столь малый прирост, меньше 10%. Поковырявшись в geoip.inc, нашел виновника. Им оказался следующий код:
if ($gi->flags & GEOIP_MEMORY_CACHE) { // workaround php's broken substr, strpos, etc handling with // mbstring.func_overload and mbstring.internal_encoding $enc = mb_internal_encoding(); mb_internal_encoding('ISO-8859-1'); $buf = substr($gi->memory_buffer, 2 * $gi->record_length * $offset, 2 * $gi->record_length); mb_internal_encoding($enc); }
Если закомментировать строки с mb_internal_encoding то в итоге скорость поднимется до 6600 IP/сек — уже более ощутимый прирост от использования кэширования в памяти. Кодировки в данном случае нас не волнуют, возможно были какие-то глюки с GeoIP City.
Что касается SxGeo, то тут думаю, комментарии излишни. Он и в обычном режиме работает очень быстро, а в режиме Batch + Memory позволяет получить прибавку еще 40%.
Желающие могут скачать и потестить SxGeo 2. Пожелания и багрепорты приветствуются.
UPD. Потестил еще запросы в разных комбинациях индексов, оказалось, что если в первые 2 запроса добавить LIMIT 1, то MySQL начинает очень тупить, где-то в 3-5 раз медленнее.

