Всем привет!
В одном из моих проектов используется нечто, немного похожее на частное облако. Это несколько серверов для хранения данных и несколько — бездисковых, отвечающих за виртуализацию. На днях я похоже что наконец поставил точку в вопросе выжимания максимальной производительности дисковой подсистемы данного решения. Это было довольно интересно и даже в некоторые моменты — довольно неожиданно. Поэтому и хочу поделиться своей историей с хабрасообществом, которая началась в далёком 2008м году, ещё до появления «Первого облачного провайдера России» и акции по рассылке бесплатных счётчиков воды.
Экспорт виртуальных жёстких дисков осуществляется через отдельную гигабитную сеть по протоколу AoE. Если коротко — это детище компании Coraid, которая предложила реализовать передачу ATA-команд по сети, напрямую. Спецификация протокола занимает всего десяток страниц! Главная особенность — это отсутствие TCP/IP. При передаче данных получается минимальный оверхед, но как плата за простоту — невозможность роутинга.
Почему именно такой выбор? Если опустить перепечатывание официальных источников — в т.ч. и банальный lowcost.
Соответственно, в хранилищах мы использовали обычные SATA-диски с 7200 rpm. Их недостаток известен всем — низкий IOPS.
Самый первый, популярный и очевидный способ решения проблемы скорости случайного доступа. Взяли mdadm в руки, вбили в консоль пару соответствующих команд, поверх подняли LVM (мы же в итоге собираемся раздавать блочные устройства для виртуальных машин) и запустили несколько наивных тестов.
Если честно, проверять IOPS было страшно, вариантов решения проблемы кроме перехода на SCSI или написания собственных костылей всё-равно не было.
Хотя сеть была и гигабитная, с бездисковых серверов скорость чтения немножко не дотягивала до ожидаемых ~100MiB/sec. Естественно, виноватыми оказались драйвера сетевых карт (привет, Debian). Использование свежих драйверов с сайта производителя проблему вроде бы частично устранила…
Во всех мануалах по оптимизации скорости AoE первым пунктом указывается выставление максимального MTU. В тот момент это было 4200. Сейчас это кажется смешным, но по сравнению со стандартными 1500, скорость линейного чтения действительно достигла ~120MiB/sec, круто! И даже при небольшо нагрузке на дисковую подсистему всеми виртуальными серверами, локальные кеши выправляли ситуацию и внутри каждой виртуалки скорость линейного чтения держалась на уровне не менее 50MiB/sec. На самом деле, довольно неплохо! Со временем, мы сменили сетевые карты, свитч — и подняли MTU до максимальных 9К.
Да, какой-то из проектов 24/7 дёргал MySQL, причём и на запись, и на чтение. Выглядело это как-то так:
Безобидно? Как бы не так. Огромный поток мелких запросов, 70% io wait на виртуальном сервере, 20%-я нагрузка на каждый из жёстких дисков (если верить atop) на хранилище и настолько унылая картина на остальных виртуалках:
И это ещё быстро! Зачастую скорость линейного чтения была не более 1-2 MiB/sec.
Думаю все уже догадались, на что мы напоролись. Низкие IOPS SATA-дисков, даже несмотря на RAID10.
Как же вовремя появились эти ребята! Это спасение, это то самое! Жизнь налаживается, мы будем спасены!
Срочная закупка SSD от Intel, включение модуля и утилит flashcache в live-образ серверов СХД, настройка write-back кеша и огонь в глазах. Ага, все счётчики по нулям. Ну, особенности LVM + Flashcache легко гуглятся, проблема быстро решилась.
На виртуальном сервере с MySQL loadavg упал с 20 до 10. Линейное чтение на остальных виртуалках возросло до стабильных 15-20 MiB/sec. Не обманули!
Спустя некоторое время я собрал такую статистику:
read hit percent: 13, write hit percent: 3. Огромное количество uncached reads/writes. Выходит, flashcache работал, но далеко не в полную силу. Всего виртуальных машин было пара десятков, суммарный объём виртуальных дисков не превышал терабайта, дисковая активность была небольшая. Т.е. такой низкий процент попадания в кэш — не из-за активности соседей.
В сотый раз глядя на вот такое:
решил открыть любимыйExcel LibreOffice Calc:
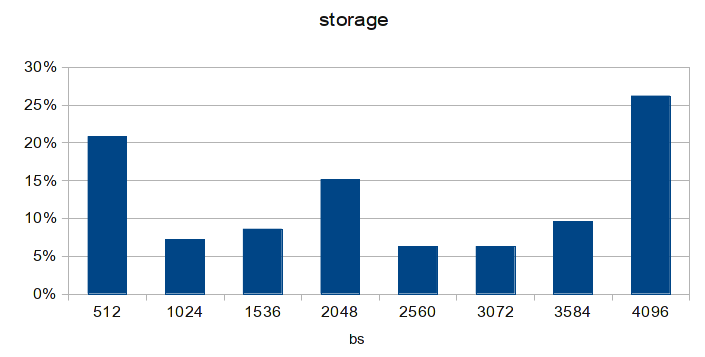
Диаграмма построена по последней строчке, гистрограмме распределения запросов по размерам блоков.
Все мы знаем, что
жёсткие диски обычно оперируют блоками по 512 байт. Ровно как и AoE. Ядро Linux — по 4096 байт. Data block size в flascache — тоже 4096.
Просуммировав количество запросов с размерами блоков отличными от 4096, то увидимо что полученное число подозрительно совпадает с количеством uncached reads + uncached writes из статистики flashcache. Кешируются только блоки размером 4К! Помните, что изначально MTU у нас был 4200? Если вычесть отсюда размер заголовка AoE-пакета, получаем размер дата-блока в 3584. Значит, любой запрос к дисковой подсистеме будет разбит минимум на 2 AoE-пакета: 3584 байт и 512 байт. Что как раз и было отчётливо видно на исходной диаграмме, которую я лицезрел. Даже на диаграмме из статьи заметно преобладание пакетов по 512 байт. И рекомендованый на каждом углу MTU в 9К тоже имеет схожую проблему: размер дата-блока составляет 8704 байта, это 2 блока по 4К и один на 512 байт (что как раз и наблюдается на диаграмме из статьи). Опаньки! Решение, думаю, очевидно всем.
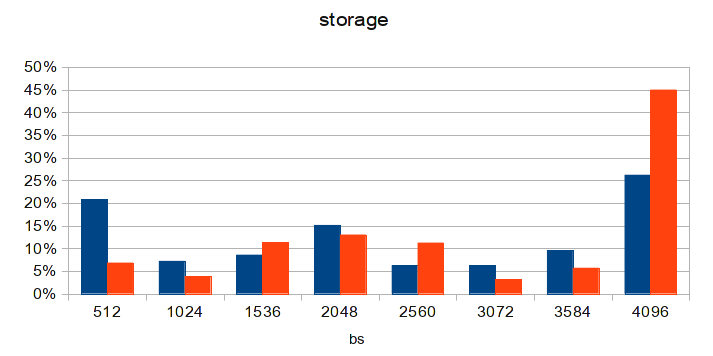
Диаграмма сделана спустя несколько суток после обновления конфигурации на одной из бездисковых нод. После обновления MTU на остальных — ситуация станет ещё лучше. А loadavg на виртуальном сервере с MySQL упал до 3!
Не будучи системными администраторами с 20-ти летним стажем, мы решали проблемы используя «стандартные» и самые популярные подходы, известные в соответствующее время сообществу. Но в реальном мире всегда есть место несовершенствам, костылям и допущениям. На которые мы, собственно, и напоролись.
Вот такая вот история.
В одном из моих проектов используется нечто, немного похожее на частное облако. Это несколько серверов для хранения данных и несколько — бездисковых, отвечающих за виртуализацию. На днях я похоже что наконец поставил точку в вопросе выжимания максимальной производительности дисковой подсистемы данного решения. Это было довольно интересно и даже в некоторые моменты — довольно неожиданно. Поэтому и хочу поделиться своей историей с хабрасообществом, которая началась в далёком 2008м году, ещё до появления «Первого облачного провайдера России» и акции по рассылке бесплатных счётчиков воды.
Архитектура
Экспорт виртуальных жёстких дисков осуществляется через отдельную гигабитную сеть по протоколу AoE. Если коротко — это детище компании Coraid, которая предложила реализовать передачу ATA-команд по сети, напрямую. Спецификация протокола занимает всего десяток страниц! Главная особенность — это отсутствие TCP/IP. При передаче данных получается минимальный оверхед, но как плата за простоту — невозможность роутинга.
Почему именно такой выбор? Если опустить перепечатывание официальных источников — в т.ч. и банальный lowcost.
Соответственно, в хранилищах мы использовали обычные SATA-диски с 7200 rpm. Их недостаток известен всем — низкий IOPS.
RAID10
Самый первый, популярный и очевидный способ решения проблемы скорости случайного доступа. Взяли mdadm в руки, вбили в консоль пару соответствующих команд, поверх подняли LVM (мы же в итоге собираемся раздавать блочные устройства для виртуальных машин) и запустили несколько наивных тестов.
root@storage:~# hdparm -tT /dev/md127
/dev/md127:
Timing cached reads: 9636 MB in 2.00 seconds = 4820.51 MB/sec
Timing buffered disk reads: 1544 MB in 3.03 seconds = 509.52 MB/sec
Если честно, проверять IOPS было страшно, вариантов решения проблемы кроме перехода на SCSI или написания собственных костылей всё-равно не было.
Сеть и MTU
Хотя сеть была и гигабитная, с бездисковых серверов скорость чтения немножко не дотягивала до ожидаемых ~100MiB/sec. Естественно, виноватыми оказались драйвера сетевых карт (привет, Debian). Использование свежих драйверов с сайта производителя проблему вроде бы частично устранила…
Во всех мануалах по оптимизации скорости AoE первым пунктом указывается выставление максимального MTU. В тот момент это было 4200. Сейчас это кажется смешным, но по сравнению со стандартными 1500, скорость линейного чтения действительно достигла ~120MiB/sec, круто! И даже при небольшо нагрузке на дисковую подсистему всеми виртуальными серверами, локальные кеши выправляли ситуацию и внутри каждой виртуалки скорость линейного чтения держалась на уровне не менее 50MiB/sec. На самом деле, довольно неплохо! Со временем, мы сменили сетевые карты, свитч — и подняли MTU до максимальных 9К.
Пока не пришёл MySQL
Да, какой-то из проектов 24/7 дёргал MySQL, причём и на запись, и на чтение. Выглядело это как-то так:
Total DISK READ: 506.61 K/s | Total DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
30312 be/4 mysql 247.41 K/s 11.78 K/s 0.00 % 11.10 % mysqld
30308 be/4 mysql 113.89 K/s 19.64 K/s 0.00 % 7.30 % mysqld
30306 be/4 mysql 23.56 K/s 23.56 K/s 0.00 % 5.36 % mysqld
30420 be/4 mysql 62.83 K/s 11.78 K/s 0.00 % 5.03 % mysqld
30322 be/4 mysql 23.56 K/s 23.56 K/s 0.00 % 2.58 % mysqld
30445 be/4 mysql 19.64 K/s 19.64 K/s 0.00 % 1.75 % mysqld
30183 be/4 mysql 7.85 K/s 7.85 K/s 0.00 % 1.15 % mysqld
30417 be/4 mysql 7.85 K/s 3.93 K/s 0.00 % 0.36 % mysqld
Безобидно? Как бы не так. Огромный поток мелких запросов, 70% io wait на виртуальном сервере, 20%-я нагрузка на каждый из жёстких дисков (если верить atop) на хранилище и настолько унылая картина на остальных виртуалках:
root@mail:~# hdparm -tT /dev/xvda
/dev/xvda:
Timing cached reads: 10436 MB in 1.99 seconds = 5239.07 MB/sec
Timing buffered disk reads: 46 MB in 3.07 seconds = 14.99 MB/sec
И это ещё быстро! Зачастую скорость линейного чтения была не более 1-2 MiB/sec.
Думаю все уже догадались, на что мы напоролись. Низкие IOPS SATA-дисков, даже несмотря на RAID10.
Flashcache
Как же вовремя появились эти ребята! Это спасение, это то самое! Жизнь налаживается, мы будем спасены!
Срочная закупка SSD от Intel, включение модуля и утилит flashcache в live-образ серверов СХД, настройка write-back кеша и огонь в глазах. Ага, все счётчики по нулям. Ну, особенности LVM + Flashcache легко гуглятся, проблема быстро решилась.
На виртуальном сервере с MySQL loadavg упал с 20 до 10. Линейное чтение на остальных виртуалках возросло до стабильных 15-20 MiB/sec. Не обманули!
Спустя некоторое время я собрал такую статистику:
root@storage:~# dmsetup status cachedev
0 2930294784 flashcache stats:
reads(85485411), writes(379006540)
read hits(12699803), read hit percent(14)
write hits(11805678) write hit percent(3)
dirty write hits(4984319) dirty write hit percent(1)
replacement(144261), write replacement(111410)
write invalidates(2928039), read invalidates(8099007)
pending enqueues(2688311), pending inval(1374832)
metadata dirties(11227058), metadata cleans(11238715)
metadata batch(3317915) metadata ssd writes(19147858)
cleanings(11238715) fallow cleanings(6258765)
no room(27) front merge(1919923) back merge(1058070)
disk reads(72786438), disk writes(374046436) ssd reads(23938518) ssd writes(42752696)
uncached reads(65392976), uncached writes(362807723), uncached IO requeue(13388)
uncached sequential reads(0), uncached sequential writes(0)
pid_adds(0), pid_dels(0), pid_drops(0) pid_expiry(0)
read hit percent: 13, write hit percent: 3. Огромное количество uncached reads/writes. Выходит, flashcache работал, но далеко не в полную силу. Всего виртуальных машин было пара десятков, суммарный объём виртуальных дисков не превышал терабайта, дисковая активность была небольшая. Т.е. такой низкий процент попадания в кэш — не из-за активности соседей.
Прозрение!
В сотый раз глядя на вот такое:
root@storage:~# dmsetup table cachedev
0 2930294784 flashcache conf:
ssd dev (/dev/sda), disk dev (/dev/md2) cache mode(WRITE_BACK)
capacity(57018M), associativity(512), data block size(4K) metadata block size(4096b)
skip sequential thresh(0K)
total blocks(14596608), cached blocks(3642185), cache percent(24)
dirty blocks(36601), dirty percent(0)
nr_queued(0)
Size Hist: 512:117531108 1024:61124866 1536:83563623 2048:89738119 2560:43968876 3072:51713913 3584:83726471 4096:41667452
решил открыть любимый

Диаграмма построена по последней строчке, гистрограмме распределения запросов по размерам блоков.
Все мы знаем, что
жёсткие диски обычно оперируют блоками по 512 байт. Ровно как и AoE. Ядро Linux — по 4096 байт. Data block size в flascache — тоже 4096.
Просуммировав количество запросов с размерами блоков отличными от 4096, то увидимо что полученное число подозрительно совпадает с количеством uncached reads + uncached writes из статистики flashcache. Кешируются только блоки размером 4К! Помните, что изначально MTU у нас был 4200? Если вычесть отсюда размер заголовка AoE-пакета, получаем размер дата-блока в 3584. Значит, любой запрос к дисковой подсистеме будет разбит минимум на 2 AoE-пакета: 3584 байт и 512 байт. Что как раз и было отчётливо видно на исходной диаграмме, которую я лицезрел. Даже на диаграмме из статьи заметно преобладание пакетов по 512 байт. И рекомендованый на каждом углу MTU в 9К тоже имеет схожую проблему: размер дата-блока составляет 8704 байта, это 2 блока по 4К и один на 512 байт (что как раз и наблюдается на диаграмме из статьи). Опаньки! Решение, думаю, очевидно всем.
MTU 8700
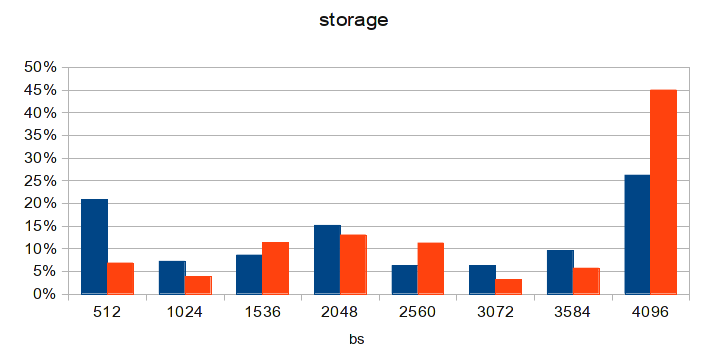
Диаграмма сделана спустя несколько суток после обновления конфигурации на одной из бездисковых нод. После обновления MTU на остальных — ситуация станет ещё лучше. А loadavg на виртуальном сервере с MySQL упал до 3!
Заключение
Не будучи системными администраторами с 20-ти летним стажем, мы решали проблемы используя «стандартные» и самые популярные подходы, известные в соответствующее время сообществу. Но в реальном мире всегда есть место несовершенствам, костылям и допущениям. На которые мы, собственно, и напоролись.
Вот такая вот история.
