Здравствуйте, Хабравчане!
Предлагаю вашему вниманию историю своего участия и победы в финале конкурса по программированию CodeTanks 2012.

Про соревнование я узнал на Хабре, решил выяснить подробнее, пошел на сайт проекта. Обрадовала возможность писать на С++ под Linux без танцев с бубном. Сразу подумалось, что будет выигрыш в производительности по сравнению с участниками, пишущими на языках типа Java/Python. Ну и сам формат соревнования мне понравился: до первого раунда две недели, дальше по неделе перерыва между раундами. Не нужно в жутком цейноте рожать правильно работающий код, а можно относительно спокойно все продумать и запрограммировать. Дальнейшее изучение правил и просмотр боев на сайте только укрепили решение участвовать: мне гораздо более интересно программировать AI в сложном и плохо определенном окружении, чем в полностью формализованном, типа настольных игр.
На прямоугольном поле ездят и стреляют 6 прямоугольных же танков. Сначала каждый сам за себя (раунд 1), потом три команды по два (раунд 2) и две команды по три танка (финал). Поле достаточно маленькое, укрытие появилось только в боях три на три, так что бои превращаются в настоящее мясо. Для движения нужно независимо управлять правой и левой гусеницей, причем физика достаточно сложная, что-то наподобие Box2D (позже реверс-инжиниринг показал, что используется его Java-аналог Phys2D). Танки достаточно неповоротливы, сколь-нибудь быстро могут ехать только прямо, во время поворота практически останавливаются. Для стрельбы у танков есть башня с пушкой, причем скорость вращения башни сильно меньше скорости поворота всего корпуса с помощью гусениц. Скорость полета снарядов также невелика и на больших дистанциях вполне реально уворачиваться.
У танков есть два типа очков жизни: здоровье экипажа и броня танка. Танк считается убитым, если любая из этих двух величин достигает нуля. Урон, наносимый снарядом, определяется его типом, скоростью, стороной танка, в которую пришелся удар, и углом, под которым это произошло. Снаряд может пробить или не пробить броню, во втором случае урон идет только по броне, а в первом еще достается экипажу. Здоровье экипажа — это очень важная характеристика: при низком здоровье в два раза снижается мощность движка, передаваемая на гусеницы, и скорость перезарядки орудия. Восстанавливать здоровье и броню можно собирая бонусы, случайно появляющиеся на карте. Помимо бонусов на восстановление очков жизни есть еще третий вид: коробка с тремя премиумными снарядами. Такие снаряды отличаются от обычных невозможностью рикошета, большим уроном и меньшей скоростью.
Игра ведется до тех пор, пока на поле не останутся только танки одного игрока, либо будет достигнут 5000 тик времени. Причем выжившим не гарантируется победа: ведется подсчет очков за нанесение урона врагу, за добивание танков, за воскрешение своих (это если натолкнуть убитый танк на восстанавливающий бонус), за убивание всех врагов, и места распределяются в соответствии с набранными очками.
Проанализировав поведение танков, решил взять в качестве модели движение по ломаной линии. То есть, танк движется прямо до точки поворота, далее делает поворот на месте и продолжает движение прямо вдоль следующего отрезка. Соответственно, в каждый момент времени необходимо решить, продолжать ли движение дальше по прямой или начать поворот. Для этого я завел массив направлений, где хранил расстояние до препятствия вдоль этого направления. Нулевое направление в массиве соответствовало направлению вперед, остальные равномерно распределялись по окружности. Исходя из расстояния до препятствий, а также наличия/отсутствия бонусов на данном направлении, я оценивал каждое направление и выбирал наилучшее (направление вперед получало дополнительный бонус). Далее, исходя из сектора, в котором находилось наилучшее направление, я включал одну из нескольких дискретных передач на гусеницы.
Локальные тесты сразу показали неадекватность дискретного набора: если танк сначала видел бонус почти прямо по курсу, а подъехав поближе, уже видел его под углом, то резко тормозил и начинал поворачивать. Переделал код так, что в небольшом секторе вокруг направления вперед подача мощности менялась плавно от «полный вперед» (1.0 1.0) до «наибыстрейший поворот» (1.0 -1.0). Танк начал довольно шустро ездить и собирать бонусы. Также попробовал реализовать простейшую систему уклонения от векторов атаки вражеских танков, но не взлетело. Прикрутив ко всему этому систему выбора цели на основании наименьшего времени наведения пушки с учетом вращения корпуса и простейшим упреждением, отправил первую версию стратегии на сайт.
Реальные бои заставили добавить движение задом наравне с движением вперед и учет расстояния до вражеских танков при выборе цели. Также я изменил код для расчета упреждения, добавив точную формулу для времени полета снаряда, но внес баг, который, в итоге, вообще обнулил упреждение. Тем не менее, с этой стратегией я попал на 200-е места в рейтинге, и приступил к реализации более сложного алгоритма, который задумал практически с самого начала соревнования.
Основная идея нового алгоритма состояла в построении «поля опасности» и движении по нему с целью минимизации этой самой «опасности». Степень опасности рассчитывалась на регулярной сетке с квадратными ячейками (размер ячеек в разное время варьировался от 10 до 16 единиц) с учетом расстояния до вражеских танков, их видимости и направления пушки. Также серьезно добавляло опасности нахождение на пути летящего снаряда. Конкретные формулы менялись много раз, в них подгонялись коэффициенты, поэтому приводить их здесь я не буду. Чтобы танк объезжал препятствия, значение степени опасности внутри твердых объектов ставилось равным достаточно большому числу. Полученное поле размывалось круговым фильтром с радиусом около 3.5 ячеек, что примерно соответствовало размеру моего собственного танка.
Для реализации такого функционала пришлось серьезно заняться геометрией. До этого у меня был только класс вектора, скопированный из другого проекта и подправленный. Теперь же я реализовал класс произвольно повернутого прямоугольника и функцию определения перекрытия двух таких прямоугольников. Для проверки видимости из некоторой точки вражеского танка я строил тонкий прямоугольник из этой точки в местоположение танка шириной в диаметр снаряда и проверял его пересечение с другими объектами.
В отличие от многих других участников соревнования, мне было лень прикручивать графический интерфейс к своей стратегии для отладки, поэтому я потратил вечер на изучение возможностей штатного терминала Linux. В нем нашлись команды для задания цветов по фиксированной 256-цветной палитре (xterm-256color), в которой присутствовал черно-белый градиент в 25 градаций. В результате фишкой моей стратегии стала возможность вывода картинки со значениями поля опасности в терминал. Сначала одной ячейке соответствовали два пробела с соответствующим значением цвета фона, потом я заменил пробелы на символ U+2584 (▄) и увеличил в два раза разрешение картинки.
Итоговое поле опасности использовалось для выбора направления движения. Модель движения осталась прежней — вдоль ломаной линии, для выбора оптимального направления использовался только первый отрезок. То есть, я считал, что танк сначала на месте поворачивается на некоторый угол, дальше с постоянной скоростью едет прямо, и останавливается, проехав некоторое расстояние. В первых версиях нового алгоритма была отдельная ветка на случай, если танк уже быстро едет, но она себе не оправдала. Используя выбранную модель движения, я проводил интегрирование поля опасности с весом, линейно спадающим со временем:

где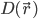 — поле опасности, а
— поле опасности, а 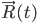 — положение танка в момент времени t, согласно модели движения. Интегрирование проводилось численно, шаг по времени подбирался такой, чтобы соответствующий шаг по пространству был в районе шага сетки поля опасности. Значение поля опасности в произвольных точках считалось с помощью билинейной фильтрации.
— положение танка в момент времени t, согласно модели движения. Интегрирование проводилось численно, шаг по времени подбирался такой, чтобы соответствующий шаг по пространству был в районе шага сетки поля опасности. Значение поля опасности в произвольных точках считалось с помощью билинейной фильтрации.
В программе я выбирал направление движения, рассчитывал время, необходимое на поворот (в приближении постоянной скорости) и записывал в текущее значение интеграла значение поля в начальной точке, умноженное на коэффициент, соответствующий времени поворота. Далее, двигаясь вдоль выбранного направления, обновлял текущее значение интеграла и считал полный интеграл для случая, если произвести остановку в последней рассмотренной точке. Если на пути попадался бонус, отнимал некоторую величину от текущего значения интеграла опасности. Найдя оптимальное расстояние вдоль одного направления, переходил к следующему. Езда по выбранному направлению организовывалась аналогично предыдущим стратегиям.
Поначалу я попытался реализовать сбор бонусов понижая значение поля опасности в их позиции. Это привело к тому, что танк стал стремиться проводить как можно больше времени рядом с бонусами вместо того, чтобы съесть их по-быстрому и продолжить движение. Пришлось организовывать бонусы в массив, сортировать по расстоянию от стартовой позиции танка и учитывать достижение каждого бонуса только один раз.
Хотя танк стал намного более умным, научился прятаться за препятствиями, это не сильно сказалось на рейтинге стратегии. Сделал небольшое уменьшение опасности в зонах, где виден хотя бы один враг, чтобы мой танк не сидел в засаде под конец игры. Тогдашние топы выносили его практически сразу: он выезжал в центр поля и получал сразу несколько попаданий, соответственно попробовал увеличить значение опасности в центре. Изменил весовую функцию при интегрировании опасности: заменил линейный спад на экспоненту. Нашел баг в расчете времени полета снаряда — починил упреждение.
Смена весовой функции на экспоненциальную планировалась с самого начала, но была отложена ввиду сложности реализации: нет максимального времени, после которого вес обнуляется. Пришлось заменить условие остановки цикла на сравнение оценки снизу интеграла опасности с его минимальным значением, найденным к текущему моменту.
После всего этого обратил внимание на проблемы с движением: иногда танк промахивался мимо бонуса и начинал ездить кругами вокруг него. Так как расчет интеграла опасности почти не зависел от модели движения, я решил задействовать приближенную к реальности физику. Поэкспериментировав с local-runner-ом, получил все необходимые константы (тут сильно помогло знание об устройстве физических движков и умение определять экспоненту на глаз по графику). Заменил набор направлений движения на набор пар мощностей, подаваемых на гусеницы. В алгоритме расчета интеграла опасности брал значение поля в координатах, соответствующих предсказанному положению танка. Хотя с прошлых версий осталась мгновенная остановка в конечной точке, это не повлияло на эффективность алгоритма. Новый алгоритм движения стал настоящим прорывом. Я достаточно быстро переместился на 20-30-е места в рейтинге. Уже тогда стало ясно, что ключем к победе является точное моделирование физики.
Хотя стратегия стала гораздо сильнее, против топов этого было мало. Я пробовал уменьшать значение опасности в углах, настраивать различные коэффициенты, убрал мгновенную остановку в расчете интеграла опасности и попытался увеличить глубину рекурсии: моделировать не одну пару мощностей на гусеницы, а сначала применить первую, а через некоторое время — вторую, но на это не хватало процессорного времени.
Тогда я решил улучшить уклонение от снарядов. До этого траектория снаряда давала большой вклад в поле опасности и танк старался отъехать подальше. Но разрешение поля достаточно низкое, а времени на уклонение мало, потому такой метод неэффективен. Но у меня уже было точно предсказанное положение танка в будущие моменты времени (а также функция определения перекрытия прямоугольников), поэтому я мог точно узнать, попадет ли снаряд в мой танк и, если да, то под каким углом. Добавляя соответствующие значения в интеграл опасности для конкретных траекторий, я мог выбрать такую, на которой будет минимальное количество попаданий и они с большей вероятностью будут рикошетами. Это стало вторым прорывом, опять связанным с точной физикой. С такой стратегией я поднялся на 10-20-е места в песочнице и занял 3-е место в первом раунде.
Причем просто определять попадание/непопадание снаряда в танк было недостаточно. Серьезный выигрыш давал учет угла, под которым ударяются снаряды. Именно благодаря нему я стал сводить большую часть попаданий на средних дистанциях к рикошетам. Тогда же я попытался учесть столкновения со стенками, чтобы улучшить уворот от снарядов при нахождении рядом с границами поля, но получил абсурдные с физической точки зрения результаты для переданного при ударе импульса и отложил реализацию этого улучшения.
Неделю до второго раунда я потратил на рефакторинг и оптимизацию кода, на эксперименты с коэффициентами и на систему синхронизации стрельбы нескольких танков. Система синхронизации себя не оправдала, и поэтому впоследствии я постепенно уменьшал коэффициент синхронности, пока не отключил ее полностью. Также сделал учет ориентации вражеского танка при выборе цели, что вывело меня на первые места в песочнице. Однако второй раунд показал, что моя стратегия сравнительно слаба в командном бою.
Для того, чтобы улучшить ситуацию, я модифицировал поле опасности так, чтобы танки старались держаться рядом друг с другом, но не совсем вплотную, а также решил серьезно заняться проблемой выбора оптимальных констант в алгоритмах. Для этого я реализовал систему автоматического запуска стратегий с произвольным набором констант (спасибо ud1 за реверс-инжиниринг local-runner-а и Run.class для запуска стратегий в любых комбинациях) и организовал генетический алгоритм: есть пул стратегий с разными константами, они играют парные бои каждая с каждой и по результатам отбрасывается наихудшая и копируется с мутациями наилучшая. Именно по результатам такой оптимизации моя стратегия стала агрессивно нападать на врага. Также коллективным разумом разобрались с физикой удара о стенки: в движке Phys2D оказалась ошибка и полученное мной абсурдное выражение для переданного импульса реально соответствовало действительности. В результате мой танк стал осмысленней себя вести рядом с границами поля.
Но всего этого было мало, а до финала оставалось все меньше времени. И я решил кардинально улучшить систему стрельбы: сделать учет точной физики вражеских танков при выборе направления на цель. Так как перебрать все варианты не хватит ресурсов, я решил ограничиться случаями, когда танк подает одинаковую мощность на обе гусеницы. Эти случаи включает в себя полный вперед и полный назад, определяющие основной диапазон возможных положений танка в будущем. Так как в этих случаях угловой момент сил отсутствует, то все угловые величины общие, а отличаются только положение и скорость танка. Причем положение можно задать двумя векторами, например позиция для случая «полный вперед» и позиция «полный назад» (у меня позиция при нулевой мощности на гусеницах и вектор смещения позиции «полный вперед» от нулевой). Все остальные положения могут быть получены линейной интерполяцией.
Зная диапазон возможных положений танка в некоторый момент времени, а также положение снаряда в тот же самый момент, я нахожу поддиапазон, в котором происходит попадание, назначаю этому поддиапазону определенное количество очков, зависящее от времени и угла попадания, и перехожу к следующему моменту времени. Интегрируя по полному диапазону возможных положений, нахожу полное количество очков, соответствующих данному снаряду. Перебирая возможные направления выстрела и учитывая время поворота башни, я нахожу оптимальное и, если возможно, стреляю. Это стало третьим прорывом, опять-таки связанным с точной физикой. Обновленная стратегия заняла первое место в первой части финала, а в перерыве я ее еще улучшил, исправив баг с нахождением пересечений, сделав учет очков от уже летящих снарядов с целью перекрыть возможно больший диапазон положений, а также отбрасывание тех положений, в которых вражеский танк оказывается внутри препятствий.
Для реализации всего задуманного мне опять пришлось заняться геометрией, написанного ранее пересечения прямоугольников было недостаточно. Теперь я находил диапазон положений при движении произвольно ориентированного прямоугольника вдоль прямой, при которых этот прямоугольник перекрывает другой стационарный прямоугольник. Также отдельно реализовал частный случай, когда движущийся прямоугольник имеет нулевые размеры, то есть является точкой.
Интегрирование по диапазону возможных положений было не совсем тривиальным. Чтобы танк предпочитал перекрывать незакрытые сектора, а не добавлять плотности огня туда, где уже есть попадание, я усилил влияние на интеграл низких значений количества очков и ослабил влияние больших с помощью степенного преобразования:

Поиск наилучшего направления выстрела я сделал не простым перебором, а алгоритмом, чем-то схожим с методом деления пополам. Проверив несколько равноотстоящих направлений вокруг луча на вражеский танк, я выбирал наилучшее, уменьшал угловой шаг в два раза и проверял направления вокруг найденного. Повторив эту процедуру рекурсивно несколько раз и дополнительно проверив текущее направление пушки, я переходил к другому вражескому танку.
Пожалуй, наиболее важное улучшение, которого мне не хватало, это автоматическое ориентирование танка боком к врагам. Из-за отсутствия этой системы мои танки были относительно слабы в дальнем бою и приходилось устраивать раш, в котором риски были гораздо больше. Мое физическое образование подсказывало заменить скалярное поле опасности на квадрупольное, то есть хранить в каждой точке пять круговых гармоник. Но это привело бы к замедлению более чем в пять раз функции выборки из поля опасности, а мои стратегии и так выполнялись на пределе доступного процессорного времени.
Другая нереализованная возможность — это учет столкновений снарядов в воздухе. Останавливала меня тут невозможность ограничиться простым избеганием других снарядов при стрельбе. Достаточно большой процент вражеских снарядов сбивается своими и если добавить избегание, то придется писать и код для стрельбы по опасным вражеским снарядам.
Смотреть записи боев можно в моем профиле на сайте соревнования.
Исходный код окончательной версии стратегии можно посмотреть тут.
Код оптимизатора констант — здесь.
Предлагаю вашему вниманию историю своего участия и победы в финале конкурса по программированию CodeTanks 2012.
Про соревнование я узнал на Хабре, решил выяснить подробнее, пошел на сайт проекта. Обрадовала возможность писать на С++ под Linux без танцев с бубном. Сразу подумалось, что будет выигрыш в производительности по сравнению с участниками, пишущими на языках типа Java/Python. Ну и сам формат соревнования мне понравился: до первого раунда две недели, дальше по неделе перерыва между раундами. Не нужно в жутком цейноте рожать правильно работающий код, а можно относительно спокойно все продумать и запрограммировать. Дальнейшее изучение правил и просмотр боев на сайте только укрепили решение участвовать: мне гораздо более интересно программировать AI в сложном и плохо определенном окружении, чем в полностью формализованном, типа настольных игр.
Краткое описание игрового мира
На прямоугольном поле ездят и стреляют 6 прямоугольных же танков. Сначала каждый сам за себя (раунд 1), потом три команды по два (раунд 2) и две команды по три танка (финал). Поле достаточно маленькое, укрытие появилось только в боях три на три, так что бои превращаются в настоящее мясо. Для движения нужно независимо управлять правой и левой гусеницей, причем физика достаточно сложная, что-то наподобие Box2D (позже реверс-инжиниринг показал, что используется его Java-аналог Phys2D). Танки достаточно неповоротливы, сколь-нибудь быстро могут ехать только прямо, во время поворота практически останавливаются. Для стрельбы у танков есть башня с пушкой, причем скорость вращения башни сильно меньше скорости поворота всего корпуса с помощью гусениц. Скорость полета снарядов также невелика и на больших дистанциях вполне реально уворачиваться.
У танков есть два типа очков жизни: здоровье экипажа и броня танка. Танк считается убитым, если любая из этих двух величин достигает нуля. Урон, наносимый снарядом, определяется его типом, скоростью, стороной танка, в которую пришелся удар, и углом, под которым это произошло. Снаряд может пробить или не пробить броню, во втором случае урон идет только по броне, а в первом еще достается экипажу. Здоровье экипажа — это очень важная характеристика: при низком здоровье в два раза снижается мощность движка, передаваемая на гусеницы, и скорость перезарядки орудия. Восстанавливать здоровье и броню можно собирая бонусы, случайно появляющиеся на карте. Помимо бонусов на восстановление очков жизни есть еще третий вид: коробка с тремя премиумными снарядами. Такие снаряды отличаются от обычных невозможностью рикошета, большим уроном и меньшей скоростью.
Игра ведется до тех пор, пока на поле не останутся только танки одного игрока, либо будет достигнут 5000 тик времени. Причем выжившим не гарантируется победа: ведется подсчет очков за нанесение урона врагу, за добивание танков, за воскрешение своих (это если натолкнуть убитый танк на восстанавливающий бонус), за убивание всех врагов, и места распределяются в соответствии с набранными очками.
Начальная стратегия
Проанализировав поведение танков, решил взять в качестве модели движение по ломаной линии. То есть, танк движется прямо до точки поворота, далее делает поворот на месте и продолжает движение прямо вдоль следующего отрезка. Соответственно, в каждый момент времени необходимо решить, продолжать ли движение дальше по прямой или начать поворот. Для этого я завел массив направлений, где хранил расстояние до препятствия вдоль этого направления. Нулевое направление в массиве соответствовало направлению вперед, остальные равномерно распределялись по окружности. Исходя из расстояния до препятствий, а также наличия/отсутствия бонусов на данном направлении, я оценивал каждое направление и выбирал наилучшее (направление вперед получало дополнительный бонус). Далее, исходя из сектора, в котором находилось наилучшее направление, я включал одну из нескольких дискретных передач на гусеницы.
Локальные тесты сразу показали неадекватность дискретного набора: если танк сначала видел бонус почти прямо по курсу, а подъехав поближе, уже видел его под углом, то резко тормозил и начинал поворачивать. Переделал код так, что в небольшом секторе вокруг направления вперед подача мощности менялась плавно от «полный вперед» (1.0 1.0) до «наибыстрейший поворот» (1.0 -1.0). Танк начал довольно шустро ездить и собирать бонусы. Также попробовал реализовать простейшую систему уклонения от векторов атаки вражеских танков, но не взлетело. Прикрутив ко всему этому систему выбора цели на основании наименьшего времени наведения пушки с учетом вращения корпуса и простейшим упреждением, отправил первую версию стратегии на сайт.
Реальные бои заставили добавить движение задом наравне с движением вперед и учет расстояния до вражеских танков при выборе цели. Также я изменил код для расчета упреждения, добавив точную формулу для времени полета снаряда, но внес баг, который, в итоге, вообще обнулил упреждение. Тем не менее, с этой стратегией я попал на 200-е места в рейтинге, и приступил к реализации более сложного алгоритма, который задумал практически с самого начала соревнования.
Поле опасности
Основная идея нового алгоритма состояла в построении «поля опасности» и движении по нему с целью минимизации этой самой «опасности». Степень опасности рассчитывалась на регулярной сетке с квадратными ячейками (размер ячеек в разное время варьировался от 10 до 16 единиц) с учетом расстояния до вражеских танков, их видимости и направления пушки. Также серьезно добавляло опасности нахождение на пути летящего снаряда. Конкретные формулы менялись много раз, в них подгонялись коэффициенты, поэтому приводить их здесь я не буду. Чтобы танк объезжал препятствия, значение степени опасности внутри твердых объектов ставилось равным достаточно большому числу. Полученное поле размывалось круговым фильтром с радиусом около 3.5 ячеек, что примерно соответствовало размеру моего собственного танка.
Для реализации такого функционала пришлось серьезно заняться геометрией. До этого у меня был только класс вектора, скопированный из другого проекта и подправленный. Теперь же я реализовал класс произвольно повернутого прямоугольника и функцию определения перекрытия двух таких прямоугольников. Для проверки видимости из некоторой точки вражеского танка я строил тонкий прямоугольник из этой точки в местоположение танка шириной в диаметр снаряда и проверял его пересечение с другими объектами.
В отличие от многих других участников соревнования, мне было лень прикручивать графический интерфейс к своей стратегии для отладки, поэтому я потратил вечер на изучение возможностей штатного терминала Linux. В нем нашлись команды для задания цветов по фиксированной 256-цветной палитре (xterm-256color), в которой присутствовал черно-белый градиент в 25 градаций. В результате фишкой моей стратегии стала возможность вывода картинки со значениями поля опасности в терминал. Сначала одной ячейке соответствовали два пробела с соответствующим значением цвета фона, потом я заменил пробелы на символ U+2584 (▄) и увеличил в два раза разрешение картинки.
Движение по полю опасности
Итоговое поле опасности использовалось для выбора направления движения. Модель движения осталась прежней — вдоль ломаной линии, для выбора оптимального направления использовался только первый отрезок. То есть, я считал, что танк сначала на месте поворачивается на некоторый угол, дальше с постоянной скоростью едет прямо, и останавливается, проехав некоторое расстояние. В первых версиях нового алгоритма была отдельная ветка на случай, если танк уже быстро едет, но она себе не оправдала. Используя выбранную модель движения, я проводил интегрирование поля опасности с весом, линейно спадающим со временем:
где
— поле опасности, а — положение танка в момент времени t, согласно модели движения. Интегрирование проводилось численно, шаг по времени подбирался такой, чтобы соответствующий шаг по пространству был в районе шага сетки поля опасности. Значение поля опасности в произвольных точках считалось с помощью билинейной фильтрации.В программе я выбирал направление движения, рассчитывал время, необходимое на поворот (в приближении постоянной скорости) и записывал в текущее значение интеграла значение поля в начальной точке, умноженное на коэффициент, соответствующий времени поворота. Далее, двигаясь вдоль выбранного направления, обновлял текущее значение интеграла и считал полный интеграл для случая, если произвести остановку в последней рассмотренной точке. Если на пути попадался бонус, отнимал некоторую величину от текущего значения интеграла опасности. Найдя оптимальное расстояние вдоль одного направления, переходил к следующему. Езда по выбранному направлению организовывалась аналогично предыдущим стратегиям.
Поначалу я попытался реализовать сбор бонусов понижая значение поля опасности в их позиции. Это привело к тому, что танк стал стремиться проводить как можно больше времени рядом с бонусами вместо того, чтобы съесть их по-быстрому и продолжить движение. Пришлось организовывать бонусы в массив, сортировать по расстоянию от стартовой позиции танка и учитывать достижение каждого бонуса только один раз.
Хотя танк стал намного более умным, научился прятаться за препятствиями, это не сильно сказалось на рейтинге стратегии. Сделал небольшое уменьшение опасности в зонах, где виден хотя бы один враг, чтобы мой танк не сидел в засаде под конец игры. Тогдашние топы выносили его практически сразу: он выезжал в центр поля и получал сразу несколько попаданий, соответственно попробовал увеличить значение опасности в центре. Изменил весовую функцию при интегрировании опасности: заменил линейный спад на экспоненту. Нашел баг в расчете времени полета снаряда — починил упреждение.
Смена весовой функции на экспоненциальную планировалась с самого начала, но была отложена ввиду сложности реализации: нет максимального времени, после которого вес обнуляется. Пришлось заменить условие остановки цикла на сравнение оценки снизу интеграла опасности с его минимальным значением, найденным к текущему моменту.
Физически точное движение и уклонение
После всего этого обратил внимание на проблемы с движением: иногда танк промахивался мимо бонуса и начинал ездить кругами вокруг него. Так как расчет интеграла опасности почти не зависел от модели движения, я решил задействовать приближенную к реальности физику. Поэкспериментировав с local-runner-ом, получил все необходимые константы (тут сильно помогло знание об устройстве физических движков и умение определять экспоненту на глаз по графику). Заменил набор направлений движения на набор пар мощностей, подаваемых на гусеницы. В алгоритме расчета интеграла опасности брал значение поля в координатах, соответствующих предсказанному положению танка. Хотя с прошлых версий осталась мгновенная остановка в конечной точке, это не повлияло на эффективность алгоритма. Новый алгоритм движения стал настоящим прорывом. Я достаточно быстро переместился на 20-30-е места в рейтинге. Уже тогда стало ясно, что ключем к победе является точное моделирование физики.
Хотя стратегия стала гораздо сильнее, против топов этого было мало. Я пробовал уменьшать значение опасности в углах, настраивать различные коэффициенты, убрал мгновенную остановку в расчете интеграла опасности и попытался увеличить глубину рекурсии: моделировать не одну пару мощностей на гусеницы, а сначала применить первую, а через некоторое время — вторую, но на это не хватало процессорного времени.
Тогда я решил улучшить уклонение от снарядов. До этого траектория снаряда давала большой вклад в поле опасности и танк старался отъехать подальше. Но разрешение поля достаточно низкое, а времени на уклонение мало, потому такой метод неэффективен. Но у меня уже было точно предсказанное положение танка в будущие моменты времени (а также функция определения перекрытия прямоугольников), поэтому я мог точно узнать, попадет ли снаряд в мой танк и, если да, то под каким углом. Добавляя соответствующие значения в интеграл опасности для конкретных траекторий, я мог выбрать такую, на которой будет минимальное количество попаданий и они с большей вероятностью будут рикошетами. Это стало вторым прорывом, опять связанным с точной физикой. С такой стратегией я поднялся на 10-20-е места в песочнице и занял 3-е место в первом раунде.
Причем просто определять попадание/непопадание снаряда в танк было недостаточно. Серьезный выигрыш давал учет угла, под которым ударяются снаряды. Именно благодаря нему я стал сводить большую часть попаданий на средних дистанциях к рикошетам. Тогда же я попытался учесть столкновения со стенками, чтобы улучшить уворот от снарядов при нахождении рядом с границами поля, но получил абсурдные с физической точки зрения результаты для переданного при ударе импульса и отложил реализацию этого улучшения.
Подборка констант
Неделю до второго раунда я потратил на рефакторинг и оптимизацию кода, на эксперименты с коэффициентами и на систему синхронизации стрельбы нескольких танков. Система синхронизации себя не оправдала, и поэтому впоследствии я постепенно уменьшал коэффициент синхронности, пока не отключил ее полностью. Также сделал учет ориентации вражеского танка при выборе цели, что вывело меня на первые места в песочнице. Однако второй раунд показал, что моя стратегия сравнительно слаба в командном бою.
Для того, чтобы улучшить ситуацию, я модифицировал поле опасности так, чтобы танки старались держаться рядом друг с другом, но не совсем вплотную, а также решил серьезно заняться проблемой выбора оптимальных констант в алгоритмах. Для этого я реализовал систему автоматического запуска стратегий с произвольным набором констант (спасибо ud1 за реверс-инжиниринг local-runner-а и Run.class для запуска стратегий в любых комбинациях) и организовал генетический алгоритм: есть пул стратегий с разными константами, они играют парные бои каждая с каждой и по результатам отбрасывается наихудшая и копируется с мутациями наилучшая. Именно по результатам такой оптимизации моя стратегия стала агрессивно нападать на врага. Также коллективным разумом разобрались с физикой удара о стенки: в движке Phys2D оказалась ошибка и полученное мной абсурдное выражение для переданного импульса реально соответствовало действительности. В результате мой танк стал осмысленней себя вести рядом с границами поля.
Стрельба с учетом точной физики
Но всего этого было мало, а до финала оставалось все меньше времени. И я решил кардинально улучшить систему стрельбы: сделать учет точной физики вражеских танков при выборе направления на цель. Так как перебрать все варианты не хватит ресурсов, я решил ограничиться случаями, когда танк подает одинаковую мощность на обе гусеницы. Эти случаи включает в себя полный вперед и полный назад, определяющие основной диапазон возможных положений танка в будущем. Так как в этих случаях угловой момент сил отсутствует, то все угловые величины общие, а отличаются только положение и скорость танка. Причем положение можно задать двумя векторами, например позиция для случая «полный вперед» и позиция «полный назад» (у меня позиция при нулевой мощности на гусеницах и вектор смещения позиции «полный вперед» от нулевой). Все остальные положения могут быть получены линейной интерполяцией.
Зная диапазон возможных положений танка в некоторый момент времени, а также положение снаряда в тот же самый момент, я нахожу поддиапазон, в котором происходит попадание, назначаю этому поддиапазону определенное количество очков, зависящее от времени и угла попадания, и перехожу к следующему моменту времени. Интегрируя по полному диапазону возможных положений, нахожу полное количество очков, соответствующих данному снаряду. Перебирая возможные направления выстрела и учитывая время поворота башни, я нахожу оптимальное и, если возможно, стреляю. Это стало третьим прорывом, опять-таки связанным с точной физикой. Обновленная стратегия заняла первое место в первой части финала, а в перерыве я ее еще улучшил, исправив баг с нахождением пересечений, сделав учет очков от уже летящих снарядов с целью перекрыть возможно больший диапазон положений, а также отбрасывание тех положений, в которых вражеский танк оказывается внутри препятствий.
Для реализации всего задуманного мне опять пришлось заняться геометрией, написанного ранее пересечения прямоугольников было недостаточно. Теперь я находил диапазон положений при движении произвольно ориентированного прямоугольника вдоль прямой, при которых этот прямоугольник перекрывает другой стационарный прямоугольник. Также отдельно реализовал частный случай, когда движущийся прямоугольник имеет нулевые размеры, то есть является точкой.
Интегрирование по диапазону возможных положений было не совсем тривиальным. Чтобы танк предпочитал перекрывать незакрытые сектора, а не добавлять плотности огня туда, где уже есть попадание, я усилил влияние на интеграл низких значений количества очков и ослабил влияние больших с помощью степенного преобразования:
Поиск наилучшего направления выстрела я сделал не простым перебором, а алгоритмом, чем-то схожим с методом деления пополам. Проверив несколько равноотстоящих направлений вокруг луча на вражеский танк, я выбирал наилучшее, уменьшал угловой шаг в два раза и проверял направления вокруг найденного. Повторив эту процедуру рекурсивно несколько раз и дополнительно проверив текущее направление пушки, я переходил к другому вражескому танку.
Нереализованные задумки
Пожалуй, наиболее важное улучшение, которого мне не хватало, это автоматическое ориентирование танка боком к врагам. Из-за отсутствия этой системы мои танки были относительно слабы в дальнем бою и приходилось устраивать раш, в котором риски были гораздо больше. Мое физическое образование подсказывало заменить скалярное поле опасности на квадрупольное, то есть хранить в каждой точке пять круговых гармоник. Но это привело бы к замедлению более чем в пять раз функции выборки из поля опасности, а мои стратегии и так выполнялись на пределе доступного процессорного времени.
Другая нереализованная возможность — это учет столкновений снарядов в воздухе. Останавливала меня тут невозможность ограничиться простым избеганием других снарядов при стрельбе. Достаточно большой процент вражеских снарядов сбивается своими и если добавить избегание, то придется писать и код для стрельбы по опасным вражеским снарядам.
Смотреть записи боев можно в моем профиле на сайте соревнования.
Исходный код окончательной версии стратегии можно посмотреть тут.
Код оптимизатора констант — здесь.

