Разделим парсинг (скраппинг) сайтов на две подзадачи.
Вначале опишем приложения:
Методов парсинга много, это и регулярные выражения и банальный поиск подстроки. Все эти способы имеют один большой недостаток – при небольших изменениях на сайте необходимо править сам парсер.
Для себя лично (пишу под .net на c#) остановился на библиотеке HtmlAgilityPack, описание например на Хабре.
Что она дает – она читает HTML (даже многие не валидные документы) и строит DOM дерево. А дальше вступает в дело вся мощь XPATH запросов. При правильно написанных XPATH запросах нет необходимости править парсер при изменениях на сайте.
Пример:
Для ориентации в DOM часто используются классы, но еще чаще минорные изменения в дизайне сайта выполняются добавлением соответствующих классов к элементам (было class=”productInfo” стало class=”productInfo clearfix”). Поэтому в XPATH лучше написать:
вместо
Да, это может сказаться на производительности, но не сильно. Универсальность кода – важнее.
Точно также при ориентации в дереве при помощи id элементов я, как правило, использую «//» (т.е. поиск по всему поддереву), вместо «/» (поиск только среди дочерних элементов). Это спасает в ситуациях, когда дизайнер обертывает какие-либо тэги (как правило, для фикса какого-нибудь бага отображения):
вместо
Парсить нам нужно основную информацию о товарах: наименование, фотография и, самое главное, список свойств. Полученные данные мы будем хранить в БД с примитивной структурой:

Т.е. для каждого товара будет список пар значений: название свойства (propertyName) и ее значение (propertyValue).
Допустим мы написали парсер, разобрали все данные с сайта и хотим теперь создать БД и сайт для поиска товаров по параметрам. Для этого нам нужно структурировать данные.
Создадим еще пару таблиц в БД для хранения структурированных данных.

Dict_Property – справочник свойств (цвет, размер, вес и т.д., т.е. все свойства по которым мы потом будем искать)
Product_Property – значения этих свойств у конкретного товара.
Маленькая «хитрость» — поле FloatValue – для числовых свойств, формируется при помощи попытки конвертации поля Value во float:
Оно будет нужно для поиска (например: поле «вес», запрос от 100 до 300 грамм, поиск по текстовому полю «Value» будет медленный и не правильный, а по floatValue – быстрый и корректный).
Теперь все готово для того чтобы начать структурировать данные.
Практика показала, что даже самые плохо оформленные Китайские магазины стараются унифицировать описания товаров.
Пример: сайт dx.com, распарсено 1267 товаров. Всего у них 49398 свойств. Если сгруппируем по названию получим всего 580 значений, что в принципе не много.
Сгруппируем свойства по названиям и по значениям, получим табличку (свойство, значение, сколько раз встречается) и отсортируем их по частоте появления.

Всю таблицу приводить смысла нет, отметим несколько моментов:
Для структурирования данных напишем приложение для создания «правил парсинга». Введем 2 типа правил:
- Собственно сам парсинг – поиск данных, которые нам интересны на страницах.
- Осмысливание полученных данных.
Вначале опишем приложения:
- Парсер «постоянной» информации о товарах с сайта. Этот парсер будет запускаться редко (исключительно для проверки наличия новых товаров), будет разбирать страницы и извлекать из них информацию о товаре: наименование, фотографии, свойства.
- Парсер условно переменной информации. Это приложение будет запускаться часто и автоматически, будет разбирать страницы сайта для поиска цен и наличия на складе для обновления этой информации в БД (мы его рассматривать не будем, тут нет ничего необычного).
- Админка, структурирование полученных данных. Это приложения будет запускаться после парсера «постоянной» информации и позволяет админу разобрать/структурировать полученные данные.
Итак, поговорим о парсерах
Методов парсинга много, это и регулярные выражения и банальный поиск подстроки. Все эти способы имеют один большой недостаток – при небольших изменениях на сайте необходимо править сам парсер.
Для себя лично (пишу под .net на c#) остановился на библиотеке HtmlAgilityPack, описание например на Хабре.
Что она дает – она читает HTML (даже многие не валидные документы) и строит DOM дерево. А дальше вступает в дело вся мощь XPATH запросов. При правильно написанных XPATH запросах нет необходимости править парсер при изменениях на сайте.
Пример:
Для ориентации в DOM часто используются классы, но еще чаще минорные изменения в дизайне сайта выполняются добавлением соответствующих классов к элементам (было class=”productInfo” стало class=”productInfo clearfix”). Поэтому в XPATH лучше написать:
div[contains(@class,’productInfo’)]
вместо
div[@class=’productInfo’]
Да, это может сказаться на производительности, но не сильно. Универсальность кода – важнее.
Точно также при ориентации в дереве при помощи id элементов я, как правило, использую «//» (т.е. поиск по всему поддереву), вместо «/» (поиск только среди дочерних элементов). Это спасает в ситуациях, когда дизайнер обертывает какие-либо тэги (как правило, для фикса какого-нибудь бага отображения):
div[@id=’productInfo’]//h1
вместо
div[@id=’productInfo’]/h1
Следующий вопрос – «что парсить?»
Парсить нам нужно основную информацию о товарах: наименование, фотография и, самое главное, список свойств. Полученные данные мы будем хранить в БД с примитивной структурой:

Т.е. для каждого товара будет список пар значений: название свойства (propertyName) и ее значение (propertyValue).
Допустим мы написали парсер, разобрали все данные с сайта и хотим теперь создать БД и сайт для поиска товаров по параметрам. Для этого нам нужно структурировать данные.
Структурирование данных
Создадим еще пару таблиц в БД для хранения структурированных данных.
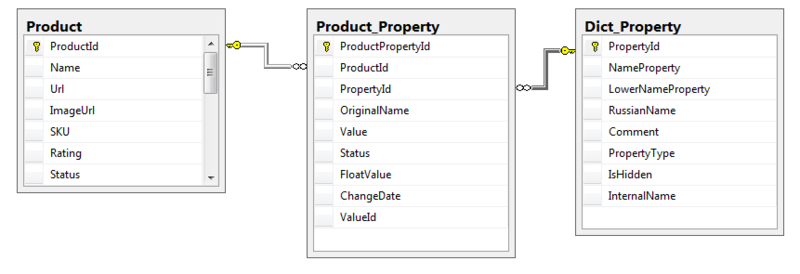
Dict_Property – справочник свойств (цвет, размер, вес и т.д., т.е. все свойства по которым мы потом будем искать)
Product_Property – значения этих свойств у конкретного товара.
Маленькая «хитрость» — поле FloatValue – для числовых свойств, формируется при помощи попытки конвертации поля Value во float:
update product_property
set floatvalue = CASE WHEN ISNUMERIC(value + 'e0') = 1 THEN CAST(value AS float) ELSE null END
Оно будет нужно для поиска (например: поле «вес», запрос от 100 до 300 грамм, поиск по текстовому полю «Value» будет медленный и не правильный, а по floatValue – быстрый и корректный).
Теперь все готово для того чтобы начать структурировать данные.
Практика показала, что даже самые плохо оформленные Китайские магазины стараются унифицировать описания товаров.
Пример: сайт dx.com, распарсено 1267 товаров. Всего у них 49398 свойств. Если сгруппируем по названию получим всего 580 значений, что в принципе не много.
Сгруппируем свойства по названиям и по значениям, получим табличку (свойство, значение, сколько раз встречается) и отсортируем их по частоте появления.

Всю таблицу приводить смысла нет, отметим несколько моментов:
- Первые 100 строк таблицы (наиболее встречаемые значения свойств) покрывают порядка 35-40% всех значений свойств.
- Очень много свойств и значений, отличающихся друг от друга только регистром или/и пробелами/опечатками.
- Цифровые данные – как правило в одном формате – например вес, габариты, объем оперативной памяти.
Для структурирования данных напишем приложение для создания «правил парсинга». Введем 2 типа правил:
- Точное совпадение. Например: свойство «Color», значение «Black»
- Совпадение по регулярному выражению. Например: свойство Weight, значение
(?\d*\.?\d+)g
