
Представляем проект indexisto.com — поиск для сайтов и мобильных приложений.
Проект в альфе, просьба отнестись с пониманием (нажимать аккуратно). Тестовая выдача сейчас по английскому контенту музыкальной тематики. Нам также очень нужны early adopter'ы, если поиск заинтересовал пишите ЛС.
Хроники
История началась пару лет назад, когда я переехал с Windows на Убунту, а потом продолжилась с переездом на Mac. Подобный переезд может дать начало десятку историй, однако у меня случилась одна — я вдруг стал пользоваться поиском по операционной системе как основным инструментом навигации.
В обеих системах поиск глубоко интегрирован, разбит на категории (файлы, программы..), работает очень быстро и имеет ряд приятных особенностей, как-то учет ранее введенных запросов в результатах выдачи. Со временем поиск научился понимать меня с первой введенной буквы.
Я так же стал замечать множество других сценариев, когда поиск здорово экономит время. Поиск по «настройкам» в Chrome, поиск по контактам в Skype, переход на человека через поиск в Facebook, подсказка URL в адресной строке Firefox с учетом частоты заходов на сайты…
В тоже время ситуация с поиском на сайтах в 99% случаев удручающая. Складывается ощущение что никто не воспринимает поисковую строку всерьез и не тратит времени на подумать. Да да, и на Хабре тоже.
С этого все началось )
Подготовка
Сколотив команду единомышленников, мы решили, что ситуацию с «мертвой» поисковой строкой на сайтах можно кардинально изменить )
Начали с того, что искали примеры хорошего и плохого поиска. Заходя на новый сайт в первую очередь смотрели как работает поиск. В итоге где-то через пол года начали вырисовываться требования к поисковой строке, на которые оказали влияние Windows 8 (приятным ощущением), new.myspace.com (смелостью), Вконтакте (скоростью и локальными поисками по всему сервису) и множество других поменьше.
Пример «революционного» поиска с перекрытием основного экрана на new.myspace.com

Требования со стороны пользователя
Появились требования, что нужно от поиска пользователю:
- скорость работы, речь о десятках миллисекунд от запроса до результата
- минимум лишних кликов, instant search и переход на искомое сразу из выпадающих результатов
- удобство. Если человек добрался до поисковой строки, не надо его зажимать в тесном инпуте шириной в 100px.
- возможность быстро настроить две поисковые строки на странице — одну глобальную по всему сайту, вторую по текущему разделу
- дополнительные параметры при поиске: категории, фасеты (тэги), сортировки
- умный поиск. Нужно помнить, что искал человек раньше, куда кликают в выдаче другие люди и др.
- очень умный поиск. Возможность «полусемантических» запросов, например, «большие красные диваны»
С первыми пунктами мы думаем, что справились, с последними двумя думаем, что в процессе )
Требования со стороны программиста/администратора:
Нужно учесть, что к поиску большинство владельцев сайтов относятся без особого энтузиазма, и выделят время программистов по остаточному принципу
- интеграция как у Google Site Search — вставил JS и работает. Не смотря на наличие серверов поиска высокого уровня типа Solr, Sphinx даже простейшая их настройка займет время, не говоря уже о множестве прекрасных параметров с говорящими названиями dis_max, tie_breaker, cutoff_frequency, slop и т.д.
- поменьше лазить в консоль, читать логи, ловить медленные запросы.
- если менеджер спросит «а что люди у нас ищут» не пришлось бы панически делать самописную статистику
- избежать двойной работы если придет задача впилить еще пару поисков
Здесь не по всем пунктам нам удалось достичь желаемого, в частности наш поиск ставится сложнее чем Google Site Search, но проще чем Solr, Sphinx
В итоге родился http://indexisto.com
Что такое indexisto?
- Это полнотекстовый поиск в облаке. Проект сделан с применением технологий Lucene и Elastic Search и написан полностью на Java.
- Не нужно самому устанавливать, настраивать и мониторить сервер полнотекстового поиска типа Sphinx, Solr
- Импорт данных напрямую из базы данных. Для этого ставится, например, PHP агент, который по нашему пушу выполняет запросы типа SELECT title,body FROM posts… В базе обязательно надо создать пользователя с правами только на чтение и только на определенные таблицы. Запрос подписан секретным ключем.
- Готовая быстронастраиваемая поисковая JS строка с множеством возможностей (виджеты, фасеты, гистограммы, сортировки). Вставка асинхронная, 50kb.
- Картинки выкачиваются и жмутся автоматом. Потом их можно вставить в шаблон выдачи.
- Удобная админка где прописываются запросы на выгребание данных, настраивается строка, запросы
- Отчеты о поисках, логи, отчеты об импортах
Админка Indexisto:
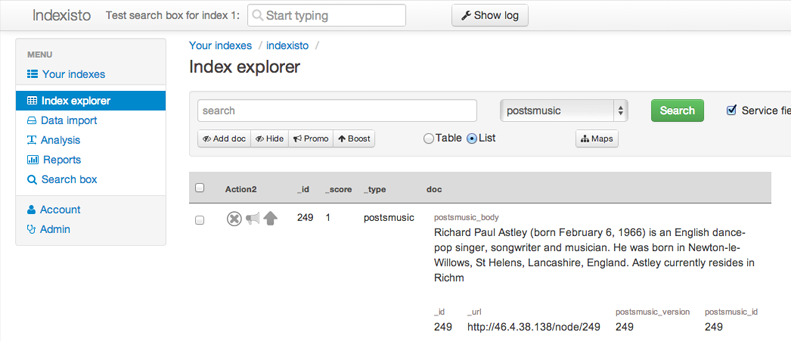
Сейчас Indexisto это полнотекстовый поиск, в облаке с удобной админкой. В процессе мы решили много задач которые облегчают жизнь администратору. К примеру вы можете долго настраивать и экспериментировать с поисковой выдачей, в админке, но на сайте эти изменения появятся только после того как вы нажмете кнопку Activate search box. Это очень полезно при любых изменениях.
Вы можете легко клонировать настройки индекса и сделать еще одну выдачу, например по подразделу. Есть незаметные но сложные проблемы, которые мы решили. Например, в Elastic Search, нельзя просто так взять и изменить поле String на поле Int в уже проиндексированном типе документа в рамках одного индекса, маппинги окажутся несовместимыми. У нас эта проблема решена непрозрачно для админа, будет создан новый индекс, с другим внутренним именем, а внешнее имя останется прежним и все настройки сохранятся.
Движение в сторону умного поиска
Уже сейчас мы считаем клики в результаты выдачи, и в ближайшее время можно будет настроить бусты в выдаче по пользовательскому поведению и поиск по ранее найденному.
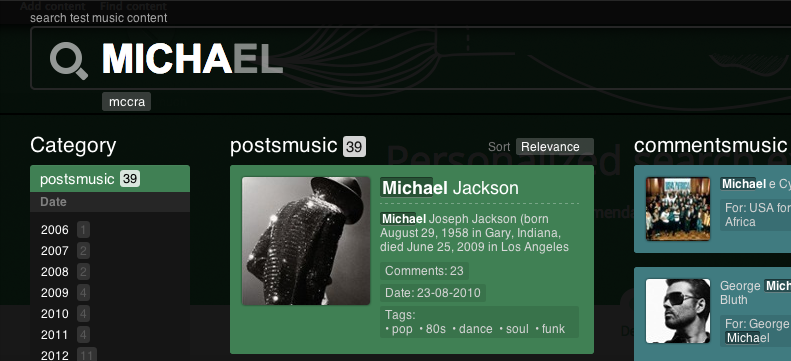
Еще одна интересная возможность — «полусемантический поиск». Так как мы берем данные напрямую из БД, вы можете делать довольно интересные вещи. Например, проиндексировать теги в текстовые поля. На примере нашей выдачи попробуйте набрать DISCO 80. Вы увидите релевантные группы которые играли диско в 80х:

Это конечно не rocket science, но можно делать и более интересные вещи, например при индексации товара:
- Имя товара: Диван «Светлана 5» т
- тип товара: диван
- цена: 7000руб
- цвет: красный
- длина: 2400мм
вы можете прописать правила:
- если длина > 2000мм добавить синонимы: БОЛЬШОЙ, ОГРОМНЫЙ, ДЛИННЫЙ
- если цена < 10000руб добавить синонимы: ДЕШЕВЫЙ, СКИДКА, РАСПРОДАЖА
таким образом мы получим «полусемантический» поиск, у нас будут работать запросы типа:
- БОЛЬШИЕ ДЕШЕВЫЕ ДИВАНЫ
- ДЕШЕВЫЕ КРАСНЫЕ ДИВАНЫ
Движение в сторону еще более умного поиска
Не знаю насколько на хабре следят за проектами типа Freebase, Dbpedia и прочими попытками структурировать информацию, но там есть подвижки, которые можно свободно использовать в свое благо. Если не вдаваться в подробности, можно извлекать структурированную информацию.
Если вы торгуете операционными системами и у вас есть товар Microsoft Windows, вы можете обогатить описание множеством дополнительных данных которые в общем случае можно найти в правой колонке в Википедии:

Таким образом у вас будет работать запрос:
ОС ДЛЯ ARM
Сейчас проект в активной разработке, однако базовый функционал мы уже готовы бесплатно подключать early adopter'ам,
пишите.
