
Занимаясь проектами связанными с веб-разработкой я сталкивался с различными вариантами реализации подержки нескольких языков для сайтов, порталов и веб приложений. Здесь я описал базовые варианты реализации архитектуры БД, которые мне встречались чаще всего.
Думаю для новыичков в веб-разработке эта статья окажется полезной, а тех кто уже имет опыт построения мультиязычных систем приглашаю для обсуждения тех вариантов, которые вы предпочитаете.
1. Создание полей для каждого языка

Реализация: для каждого поля для каждого языка в таблице создается отдельная колонка
Особенности: при большом количестве языков, или при заране неизвестно количестве языков такой подход будет требовать изменения структуры БД каждый раз, когда понадобиться реализовать подержку нового языка.
Когда стоит использовать: когда заранее четко известно количество поддерживаемых языков, и каждая сущность должна сущестовать во всех языковых вариантах.
2. Создание таблицы локализации
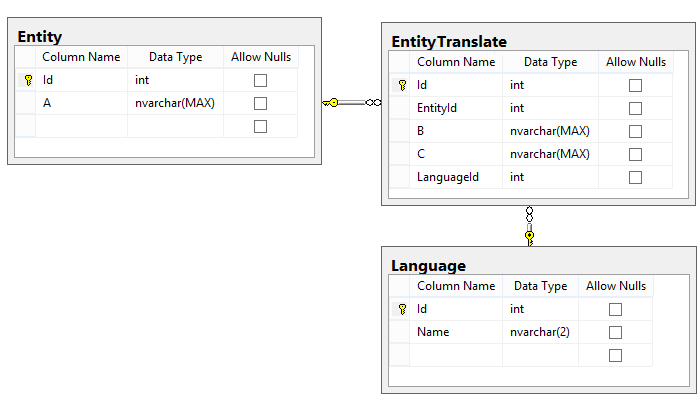
Реализация: для каждой сущности требующей локализации создается две таблицы. Основная таблица, содержащая поля, которые не зависят от конкретного языка и таблица содержащая поля требующие перевода. Также в БД создается таблица со списком доступных языков.
Особенности: данный подход ползволяет реализовать достаточно гибкую расширяемость поддерживаемых языков. Структура этого варианта немного сложнее предыдущего и предполагает создание таблицы-саттелита для каждой таблицы содержащей локализуемые поля.
3. Использование сериализованных данных сложной структуры
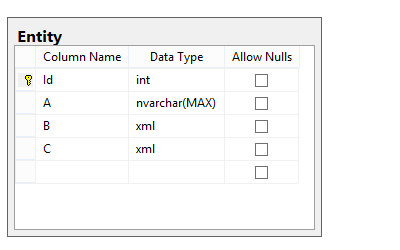
Реализация: в каждое поле требующее перевода пишется информация в сериализованном виде, например в JSON, XML, binary, etc. Объект при этом может быть например словарем, в котором ключ — язык, значение — текст. Или любой другой структуры.
Особенности: главная особенность состоит в том, что целостоность данных зависит уже не только от базы данных, но и от механизма сериализации. Кроме того, в таком варианте также очень сильно снижается нормализация базы данных.
4. Отдельная запись в таблице для каждого языка
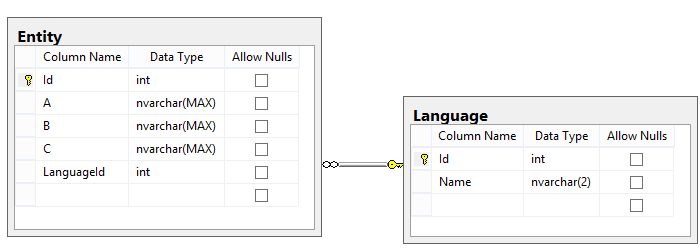
Реализация: в каждой таблице, которая описывает сущность требующую локализации поле с указанием языка, к которому относится запись. Также в БД создается таблица со списком доступных языков.
Особенности: данный вариант примечателен тем, что по сути одному объекту предметной области может соответствовать несколько объектов в БД и несколько связей. ЧТо может достаточно сильно усложнить бизнес-логику.
5. Отсутствие локализации на уровне БД. Использование внешних средств локлаизации
Данный вариант не относится напрямую к теме статьи, но думаю что упомянуть его стоит.
Реализация: способ реализуется за счет внешних подключаемых модулей (Google translate, Bing translate, etc.).
Особенности: данный вариант может применятся в том случае, если владелец ресурса хочет иметь возможность предоставить информацию как можно большему количеству посетителей. При этом следует понимать, что качество машинного перевода зачастую оставляет жлеать лучшего. Вариант может рассматриваться лишь как очень бюджетный (когда нет ресурсов на перевод каждой публикации) и перед его применением я бы рекомендовал хорошо подумать — а стоит ли вообще его реализовывать.
6. Создание таблицы перевода для каждого языка

Вариант предложенный хабрапользователем VolCh.
Реализация: для каждого языка в БД создается отдельная таблица, содержащая поля требующие перевода.
Особенности: при добавлении нового языка необходимо вносить изменения в базу. При большом количестве поддерживаемых языков количество таблиц может быть очень велико.
Хранение «статической» текстовой информации
Пару слов о хранении статической текстовой информации. Под ней я имею ввиду надписи на кнопках, информацию в футере и остальной текст такого типа, который в большинстве случаев не изменяется контент-менеджером, а при реализации одноязычных сайтов заносится прямо в шаблон. В случае многоязычного сайта для ханения такого текст может быть несколько вариантов:
- Текст хранится в базе и кэшируется при запуске веб-приложения — вариант позволяет потенциально расширять количество поддерживаемых языков. По сути текст становится не статическим, а вполне динамическим контентом.
- Текст хранится в ресурсных файлах — вариант по быстродействия быстрее предыдущего варианта, но для добавления языка необходима правка файлов веб-приложения
- Для каждого языкового варианта создается отдельный шаблон, содержащий статический текст — на мой взгляд излишне избыточный вариант. Имеет те же недостатки, что и предыдущий.
Другие варианты
Если вы хотите предложить еще какие-нибудь варианты реализации мультиязычности отличные от описанных — пишите мне и я включу их в статью.
Также, было бы интересно узнать, какие аргументы, кроме тех что изложены выше, для вас важны при выборе предпочитаемого варианта реализации.
Полезная информация
- Создание многоязычных сайтов (sharepoint)
- ASP.NET MVC Урок C. Многоязычный сайт
- Шесть советов по созданию сайтов для многоязычной аудитории от Google Web Studio
- Zend Framework и многоязычность
- LilacServer – коробка для создания сайтов на Java
- Локализация интерфейса сайта с использованием PHP, Smarty и Gettext
- Многоязычные модели Django для начинающих
- ASP.NET MVC 2 Localization complete guide
- Multilingual WordPress
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Какой вариант реализации поддержки мультиязычности вы предпочитаете?
13.67%1. Создание полей для каждого языка108
47.97%2. Создание таблицы локализации379
5.95%3. Использование сериализованных данных сложной структуры47
12.15%4. Отдельная запись в таблице для каждого языка96
16.08%5. Отсутствие локализации на уровне БД. Использование внешних средств локализации127
4.18%Свой вариант- напишу в коментариях33
Проголосовали 790 пользователей. Воздержались 355 пользователей.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Где нужно хранить статические текстовые блоки?
35.61%Текст хранится в базе и кэшируется при запуске веб-приложения255
56.28%Текст хранится в ресурсных файлах403
8.1%Для каждого языкового варианта создается отдельный шаблон58
Проголосовали 716 пользователей. Воздержался 291 пользователь.

