Продолжение.
Предыдущие части: 1-3, 4-6
Я уже показал вам как данные из разных таблиц могут быть связаны при помощи связи по внешнему ключу. Вы видели как заказы связываются с клиентами путем помещения customer_id в качестве внешнего ключа в таблице заказов.
Другой пример связи один-ко-многим – это связь, которая существует между матерью и ее детьми. Мать может иметь множество детей, но каждый ребенок может иметь только одну мать.
(Технически лучше говорить о женщине и ее детях вместо матери и ее детях потому, что, в контексте связи один-ко-многим, мать может иметь 0, 1 или множество потомков, но мать с 0 детей не может считаться матерью. Но давайте закроем на это глаза, хорошо?)
Когда одна запись в таблице А может быть связана с 0, 1 или множеством записей в таблице B, вы имеете дело со связью один-ко-многим. В реляционной модели данных связь один-ко-многим использует две таблицы.
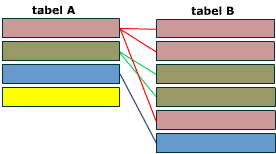
Схематическое представление связи один-ко-многим. Запись в таблице А имеет 0, 1 или множество ассоциированных ей записей в таблице B.
Если у вас есть две сущности спросите себя:
1) Сколько объектов и B могут относится к объекту A?
2) Сколько объектов из A могут относиться к объекту из B?
Если на первый вопрос ответ – множество, а на второй – один (или возможно, что ни одного), то вы имеете дело со связью один-ко-многим.
Некоторые примеры связи один-ко-многим:
В данном случае все настолько просто, что только поэтому может оказаться трудным понимание. Возьмем последний пример с домами. На улице ведь действительно может быть любое количество домов, но у каждого дома именно на этой улице может быть только одна улица (не берем дома, которые на практике принадлежат разным улицам, возьмем, к примеру, дом в центре улицы). Ведь не может конкретно этот дом быть одновременно в двух местах, на двух разных улицах, а мы говорим не про какой-то абстрактный дом вообще, а про конкретный.
Связь многие-ко-многим – это связь, при которой множественным записям из одной таблицы (A) могут соответствовать множественные записи из другой (B). Примером такой связи может служить школа, где учителя обучают учащихся. В большинстве школ каждый учитель обучает многих учащихся, а каждый учащийся может обучаться несколькими учителями.
Связь между поставщиком пива и пивом, которое они поставляют – это тоже связь многие-ко-многим. Поставщик, во многих случаях, предоставляет более одного вида пива, а каждый вид пива может быть предоставлен множеством поставщиков.
Обратите внимание, что при проектировании базы данных вы должны спросить себя не о том, существуют ли определенные связи в данный момент, а о том, возможно ли существование связей вообще, в перспективе. Если в настоящий момент все поставщики предоставляют множество видов пива, но каждый вид пива предоставляется только одним поставщиком, то вы можете подумать, что это связь один-ко-многим, но… Не торопитесь реализовывать связь один-ко-многим в этой ситуации. Существует высокая вероятность того, что в будущем два или более поставщиков будут поставлять один и тот же вид пива и когда это случится ваша база данных — со связью один-ко-многим между поставщиками и видами пива – не будет подготовлена к этому.
Связь многие-ко-многим создается с помощью трех таблиц. Две таблицы – “источника” и одна соединительная таблица. Первичный ключ соединительной таблицы A_B – составной. Она состоит из двух полей, двух внешних ключей, которые ссылаются на первичные ключи таблиц A и B.
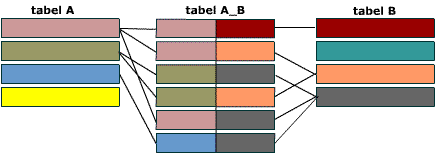
Все первичные ключи должны быть уникальными. Это подразумевает и то, что комбинация полей A и B должна быть уникальной в таблице A_B.
Пример проект базы данных ниже демонстрирует вам таблицы, которые могли бы существовать в связи многие-ко-многим между бельгийскими брендами пива и их поставщиками в Нидерландах. Обратите внимание, что все комбинации beer_id и distributor_id уникальны в соединительной таблице.
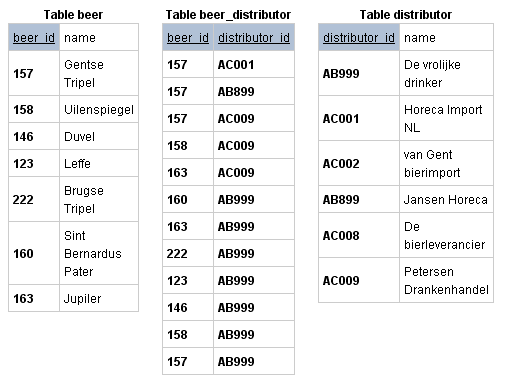

Таблицы выше связывают поставщиков и пиво связью многие-ко-многим, используя соединительную таблицу. Обратите внимание, что пиво 'Gentse Tripel' (157) поставляют Horeca Import NL (157, AC001) Jansen Horeca (157, AB899) и Petersen Drankenhandel (157, AC009). И vice versa, Petersen Drankenhandel является поставщиком 3 видов пива из таблицы, а именно: Gentse Tripel (157, AC009), Uilenspiegel (158, AC009) и Jupiler (163, AC009).
Еще обратите внимание, что в таблицах выше поля первичных ключей окрашены в синий цвет и имеют подчеркивание. В модели проекта базы данных первичные ключи обычно подчеркнуты. И снова обратите внимание, что соединительная таблица beer_distributor имеет первичный ключ, составленный из двух внешних ключей. Соединительная таблица всегда имеет составной первичный ключ.
Есть еще одна важная вещь на которую нужно знать. Связь многие-ко-многим состоит из двух связей один-ко-многим. Обе таблицы: поставщики пива и пиво – имеют связь один-ко-многим с соединительной таблицей.
В качестве последнего примера позвольте мне показать как бы могла быть смоделирована таблица заказов номеров гостиницы посетителями.

Соединительная таблица связи многие-ко-многим имеет дополнительные поля.
В этом примере вы видите, что между таблицами гостей и комнат существует связь многие-ко-многим. Одна комната может быть заказана многими гостями с течением времени и с течением времени гость может заказывать многие комнаты в отеле. Соединительная таблица в данном случае является не классической соединительной таблицей, которая состоит только из двух внешних ключей. Она является отдельной сущностью, которая имеет связи с двумя другими сущностями.
Вы часто будете сталкиваться с такими ситуациями, когда совокупность двух сущностей будет являться новой сущностью.
В связи один-к-одному каждый блок сущности A может быть ассоциирован с 0, 1 блоком сущности B. Наемный работник, например, обычно связан с одним офисом. Или пивной бренд может иметь только одну страну происхождения.
Связь один-к-одному легко моделируется в одной таблице. Записи таблицы содержат данные, которые находятся в связи один-к-одному с первичным ключом или записью.
В редких случаях связь один-к-одному моделируется используя две таблицы. Такой вариант иногда необходим, чтобы преодолеть ограничения РСУБД или с целью увеличения производительности (например, иногда — это вынесение поля с типом данных blob в отдельную таблицу для ускорения поиска по родительской таблице). Или порой вы можете решить, что вы хотите разделить две сущности в разные таблицы в то время, как они все еще имеют связь один-к-одному. Но обычно наличие двух таблиц в связи один-к-одному считается дурной практикой.
Проект реляционной базы данных – это коллекция таблиц, которые перелинковываются (связываются) первичными и внешними ключами. Реляционная модель данных включает в себя ряд правил, которые помогают вам создать верные связи между таблицами. Эти правила называются “нормальными формами”. В следующих частях я покажу как нормализовать вашу базу данных.
Примеры связей таблиц на практике. Когда какие-то данные являются уникальными для конкретного объекта, например, человек и номера его паспортов, то имеем дело со связью один-ко-многим. Т.е. в одной таблице мы имеем список неких людей, а в другой таблице у нас есть перечисление номеров паспортов этого человека (напр., паспорт страны проживания и загранпаспорт). И эта комбинация данных уникальная для каждого человека. Т.е. у каждого человека может быть несколько номеров паспортов, но у каждого паспорта может быть только один владелец. Итого: нужны две таблицы.
А если есть некие данные, которые могу быть присвоены любому человеку, то имеем дело со связью многие-ко-многим. Например, есть таблица со списком людей и мы хотим хранить информацию о том, какие страны посетил каждый человек. В данном случае имеется две сущности: люди и страны. Любой человек может посетить любое количество стран равно, как и любая страна может быть посещена любым человеком. Т.е., в данном случае, страна не является уникальными данными для конкретного человека и может использоваться повторно.
В таких случаях использование связи многие-ко-многим с использованием трех таблиц и с хранением общей информации централизованно очень удобно. Ведь если общие данные меняются, то для того, чтобы информация в базе данных соответствовала действительности достаточно подправить ее только в одном месте, т.к. хранится она только в одном месте (таблице), в остальных таблицах имеются лишь ссылки на нее.
А когда у вас есть набор уникальных данных, которые имеют отношение только друг к другу, то храните все в одной таблице. Ваш выбор – связь один-к-одному. Например, у вас есть небольшая коллекция автомобилей и вы хотите хранить информацию о них (цвет, марка, год выпуска и пр.).
Предыдущие части: 1-3, 4-6
7. Связь один-ко-многим.
Я уже показал вам как данные из разных таблиц могут быть связаны при помощи связи по внешнему ключу. Вы видели как заказы связываются с клиентами путем помещения customer_id в качестве внешнего ключа в таблице заказов.
Другой пример связи один-ко-многим – это связь, которая существует между матерью и ее детьми. Мать может иметь множество детей, но каждый ребенок может иметь только одну мать.
(Технически лучше говорить о женщине и ее детях вместо матери и ее детях потому, что, в контексте связи один-ко-многим, мать может иметь 0, 1 или множество потомков, но мать с 0 детей не может считаться матерью. Но давайте закроем на это глаза, хорошо?)
Когда одна запись в таблице А может быть связана с 0, 1 или множеством записей в таблице B, вы имеете дело со связью один-ко-многим. В реляционной модели данных связь один-ко-многим использует две таблицы.
Схематическое представление связи один-ко-многим. Запись в таблице А имеет 0, 1 или множество ассоциированных ей записей в таблице B.
Как опознать связь один-ко-многим?
Если у вас есть две сущности спросите себя:
1) Сколько объектов и B могут относится к объекту A?
2) Сколько объектов из A могут относиться к объекту из B?
Если на первый вопрос ответ – множество, а на второй – один (или возможно, что ни одного), то вы имеете дело со связью один-ко-многим.
Примеры.
Некоторые примеры связи один-ко-многим:
- Машина и ее части. Каждая часть машины единовременно принадлежит только одной машине, но машина может иметь множество частей.
- Кинотеатры и экраны. В одном кинотеатре может быть множество экранов, но каждый экран принадлежит только одному кинотеатру.
- Диаграмма сущность-связь и ее таблицы. Диаграмма может иметь больше, чем одну таблицу, но каждая из этих таблиц принадлежит только одной диаграмме.
- Дома и улицы. На улице может быть несколько домов, но каждый дом принадлежит только одной улице.
В данном случае все настолько просто, что только поэтому может оказаться трудным понимание. Возьмем последний пример с домами. На улице ведь действительно может быть любое количество домов, но у каждого дома именно на этой улице может быть только одна улица (не берем дома, которые на практике принадлежат разным улицам, возьмем, к примеру, дом в центре улицы). Ведь не может конкретно этот дом быть одновременно в двух местах, на двух разных улицах, а мы говорим не про какой-то абстрактный дом вообще, а про конкретный.
8. Связь многие-ко-многим.
Связь многие-ко-многим – это связь, при которой множественным записям из одной таблицы (A) могут соответствовать множественные записи из другой (B). Примером такой связи может служить школа, где учителя обучают учащихся. В большинстве школ каждый учитель обучает многих учащихся, а каждый учащийся может обучаться несколькими учителями.
Связь между поставщиком пива и пивом, которое они поставляют – это тоже связь многие-ко-многим. Поставщик, во многих случаях, предоставляет более одного вида пива, а каждый вид пива может быть предоставлен множеством поставщиков.
Обратите внимание, что при проектировании базы данных вы должны спросить себя не о том, существуют ли определенные связи в данный момент, а о том, возможно ли существование связей вообще, в перспективе. Если в настоящий момент все поставщики предоставляют множество видов пива, но каждый вид пива предоставляется только одним поставщиком, то вы можете подумать, что это связь один-ко-многим, но… Не торопитесь реализовывать связь один-ко-многим в этой ситуации. Существует высокая вероятность того, что в будущем два или более поставщиков будут поставлять один и тот же вид пива и когда это случится ваша база данных — со связью один-ко-многим между поставщиками и видами пива – не будет подготовлена к этому.
Создание связи многие-ко-многим.
Связь многие-ко-многим создается с помощью трех таблиц. Две таблицы – “источника” и одна соединительная таблица. Первичный ключ соединительной таблицы A_B – составной. Она состоит из двух полей, двух внешних ключей, которые ссылаются на первичные ключи таблиц A и B.
Все первичные ключи должны быть уникальными. Это подразумевает и то, что комбинация полей A и B должна быть уникальной в таблице A_B.
Пример проект базы данных ниже демонстрирует вам таблицы, которые могли бы существовать в связи многие-ко-многим между бельгийскими брендами пива и их поставщиками в Нидерландах. Обратите внимание, что все комбинации beer_id и distributor_id уникальны в соединительной таблице.
Таблицы “о пиве”.
Таблицы выше связывают поставщиков и пиво связью многие-ко-многим, используя соединительную таблицу. Обратите внимание, что пиво 'Gentse Tripel' (157) поставляют Horeca Import NL (157, AC001) Jansen Horeca (157, AB899) и Petersen Drankenhandel (157, AC009). И vice versa, Petersen Drankenhandel является поставщиком 3 видов пива из таблицы, а именно: Gentse Tripel (157, AC009), Uilenspiegel (158, AC009) и Jupiler (163, AC009).
Еще обратите внимание, что в таблицах выше поля первичных ключей окрашены в синий цвет и имеют подчеркивание. В модели проекта базы данных первичные ключи обычно подчеркнуты. И снова обратите внимание, что соединительная таблица beer_distributor имеет первичный ключ, составленный из двух внешних ключей. Соединительная таблица всегда имеет составной первичный ключ.
Есть еще одна важная вещь на которую нужно знать. Связь многие-ко-многим состоит из двух связей один-ко-многим. Обе таблицы: поставщики пива и пиво – имеют связь один-ко-многим с соединительной таблицей.
Другой пример связи многие-ко-многим: заказ билетов в отеле.
В качестве последнего примера позвольте мне показать как бы могла быть смоделирована таблица заказов номеров гостиницы посетителями.
Соединительная таблица связи многие-ко-многим имеет дополнительные поля.
В этом примере вы видите, что между таблицами гостей и комнат существует связь многие-ко-многим. Одна комната может быть заказана многими гостями с течением времени и с течением времени гость может заказывать многие комнаты в отеле. Соединительная таблица в данном случае является не классической соединительной таблицей, которая состоит только из двух внешних ключей. Она является отдельной сущностью, которая имеет связи с двумя другими сущностями.
Вы часто будете сталкиваться с такими ситуациями, когда совокупность двух сущностей будет являться новой сущностью.
9. Связь один-к-одному.
В связи один-к-одному каждый блок сущности A может быть ассоциирован с 0, 1 блоком сущности B. Наемный работник, например, обычно связан с одним офисом. Или пивной бренд может иметь только одну страну происхождения.
В одной таблице.
Связь один-к-одному легко моделируется в одной таблице. Записи таблицы содержат данные, которые находятся в связи один-к-одному с первичным ключом или записью.
В отдельных таблицах.
В редких случаях связь один-к-одному моделируется используя две таблицы. Такой вариант иногда необходим, чтобы преодолеть ограничения РСУБД или с целью увеличения производительности (например, иногда — это вынесение поля с типом данных blob в отдельную таблицу для ускорения поиска по родительской таблице). Или порой вы можете решить, что вы хотите разделить две сущности в разные таблицы в то время, как они все еще имеют связь один-к-одному. Но обычно наличие двух таблиц в связи один-к-одному считается дурной практикой.
Примеры связи один-к-одному.
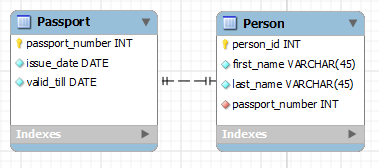
- Люди и их паспорта. Каждый человек в стране имеет только один действующий паспорт и каждый паспорт принадлежит только одному человеку.
Проект реляционной базы данных – это коллекция таблиц, которые перелинковываются (связываются) первичными и внешними ключами. Реляционная модель данных включает в себя ряд правил, которые помогают вам создать верные связи между таблицами. Эти правила называются “нормальными формами”. В следующих частях я покажу как нормализовать вашу базу данных.
Какой же вид связи вам нужен?
Примеры связей таблиц на практике. Когда какие-то данные являются уникальными для конкретного объекта, например, человек и номера его паспортов, то имеем дело со связью один-ко-многим. Т.е. в одной таблице мы имеем список неких людей, а в другой таблице у нас есть перечисление номеров паспортов этого человека (напр., паспорт страны проживания и загранпаспорт). И эта комбинация данных уникальная для каждого человека. Т.е. у каждого человека может быть несколько номеров паспортов, но у каждого паспорта может быть только один владелец. Итого: нужны две таблицы.
А если есть некие данные, которые могу быть присвоены любому человеку, то имеем дело со связью многие-ко-многим. Например, есть таблица со списком людей и мы хотим хранить информацию о том, какие страны посетил каждый человек. В данном случае имеется две сущности: люди и страны. Любой человек может посетить любое количество стран равно, как и любая страна может быть посещена любым человеком. Т.е., в данном случае, страна не является уникальными данными для конкретного человека и может использоваться повторно.
В таких случаях использование связи многие-ко-многим с использованием трех таблиц и с хранением общей информации централизованно очень удобно. Ведь если общие данные меняются, то для того, чтобы информация в базе данных соответствовала действительности достаточно подправить ее только в одном месте, т.к. хранится она только в одном месте (таблице), в остальных таблицах имеются лишь ссылки на нее.
А когда у вас есть набор уникальных данных, которые имеют отношение только друг к другу, то храните все в одной таблице. Ваш выбор – связь один-к-одному. Например, у вас есть небольшая коллекция автомобилей и вы хотите хранить информацию о них (цвет, марка, год выпуска и пр.).

