Введение
В мире функционального программирования есть один большой пробел, а именно почти не освещена тема высокоуровневого дизайна больших приложений. Я решил для себя изучить этот вопрос. Есть ли существенные отличия дизайна приложений в ФП-мире от оного в мире императивном? Что такое «каноничный ФП-код»? Какие существуют идиомы разработки, есть ли смысл вообще говорить о паттернах проектирования в применении к ФП? Эти и другие важные вопросы часто вспыхивают то там, то здесь, но покамест мне не известно ни одной книги, аналогичной книге Банды Четырех. Вероятно, мои изыскания уже кто-то повторил, однако тем лучше: схожие результаты подтвердят правильность, иные — укажут на место в теории, которое необходимо доработать.
О материале
Основа данных статей — опыт по разработке игры «The Amoeba World». Используемый язык — Haskell. Игру я изначально делал в рамках конкурса «Ludum Dare» #27, но прицел был на прототипирование инфраструктуры для другой игры, более масштабной, имя которой «Big Space». «The Amoeba World» — лишь «кошка», на которой я исследую подходы в «функциональном» геймдеве. Конкурсо-ориентированная игра стала хорошей стартовой площадкой для дальнейших раздумий.
Код «The Amoeba World» вот здесь. Документация по «Big Space» — здесь. Кстати, давным-давно я уже делал нечто похожее. Это был «Haskell Quest Tutorial», в рамках написания которого я, гм, тоже разрабатывал игру. Если это можно так назвать. Но то был очень простой низкоуровневый материал для изучения языка Haskell, здесь же речь пойдет совсем об иных материях. Соответственно, предполагается, что читатель в достаточной мере знаком с ФП и языком программирования Haskell.
План
По крайней мере следующие темы должны быть освещены в дальнейшем:
- Часть 1. Архитектура ФП приложения. Нисходящее проектирование в ФП. Борьба со сложностью ПО.
- Часть 2. Восходящее проектирование в ФП. Идея — основа хорошего дизайна. Антипаттерны в Haskell.
- Часть 3. Свойства и законы. Сценарии. Inversion of Control в Haskell.
- Часть 4. FRP
Также данный цикл статей можно найти единым документом здесь.
Часть первая
Архитектура ФП приложения. Нисходящее проектирование в ФП. Борьба со сложностью ПО.
Немного теории
Процесс разработки ПО исхожен вдоль и поперек. Мы давно пользуемся стандартизированными техниками в нашей практике, — это и различные методологии, и приемы проектирования ПО, и инструменты моделирования. Очень известен, например, UML — язык объектно-ориентированного (по большей части) проектирования. Его используют для сквозной разработки, начиная с требований и заканчивая, если повезет, генерацией кода. А паттерны проектирования? Сегодня необходимо их знать, чтобы решать типовые проблемы в ОО-коде. И есть лишь один вопрос — насколько этот багаж знаний применим к функциональной парадигме? Можно ли придумать свой язык моделирования? Нужны ли паттерны для функциональных языков?
Видится, что начальные этапы — сбор и анализ требований, определение функционала программы, написание бизнес-сценариев, — будут в той или иной мере присутствовать всегда, о каком бы ПО ни шла речь. Представим, что требования нам уже известны, и пропустим пока первые этапы, сосредоточившись на более инженерных.
И первый по-настоящему инженерный этап — разработка архитектуры ПО, или, что то же самое — архитектурный дизайн ПО. Здесь мы решаем вопросы высокоуровневого строения и функционирования программы, чтобы поддержать все нефункциональные требования, собранные ранее. Выбор парадигмы программирования — это тоже архитектурный вопрос. Выбирая ФП, мы почти полностью отказываемся от UML в виду его объектной природы. Так, диаграммы классов, объектов и последовательности практически теряют смысл. В Haskell нет классов или объектов, нет инкапсулированной мутабельности, — а есть только процесс преобразования данных. Диаграмму последовательности, необходимую для описания взаимодействий этих самых объектов, можно было бы как-то использовать для цепочек функций, но штука в том, что сами цепочки будут более читабельны и понятны. Все прочие диаграммы, тем не менее, вполне применимы. В большой программе на ФП также имеются подсистемы или компоненты, а значит, в строю остаются диаграммы компонентов, пакетов и коммуникации. Диаграмма состояний — универсальна: процессы и конечные автоматы встречаются очень часто. Ее можно было бы применять даже в иных областях, не только в разработке ПО. Наконец, диаграмма вариантов использования вообще имеет мало отношения к дизайну ПО; она связывает бизнес-требования с системными требованиями на этапе анализа.
Но если внимательно присмотреться к «применимым» диаграммам, можно прийти к выводу, что они слабо помогут в высокоуровневом дизайне кода (который располагается ниже дизайна архитектуры), а то и вовсе могут навредить, подталкивая к императивному мышлению. Например, думая о компонентной архитектуре, мы вспоминаем Inversion of Control. IoC решает одну из главных проблем разработки ПО — помогает бороться со сложностью за счет выделения абстракций. А что если взять его на вооружение? И тут мы вспоминаем, что есть один из способов его реализации — Dependency Injection. Вероятно, его можно адаптировать под наши нужды, — в следующих частях мы рассмотрим несколько различных решений, как то: Existential Types, абстракции на уровне модулей, монадная абстракция, а также монадная инъекция состояния. Но на самом деле, имея первоклассные функции, мы можем вообще забыть о DI, так как это неидиоматичный подход, поскольку он приводит (явно или неявно) к состоянию в ФП-программе. А это не всегда хорошо. Хотя, справедливости ради, нужно признать, что IoC присутствует и в ФП.
А что еще, если не IoC, помогает в борьбе со сложностью при дизайне ПО? Из SICP мы знаем, что есть три важных методики:
- абстракции для скрытия деталей реализации («черный ящик»);
- публичные интерфейсы взаимодействия между независимыми системами;
- предметно-ориентированные языки (DSL, Domain Specific Languages).
Можно предположить, что первые две методики нам известны. Интерфейсы, абстракция, сокрытие деталей, — всё это об одном, и IoC — тому пример. Из-за доминирования ООП-языков у нас сложились прочные ассоциативные связи «абстракция» => «наследование» и «интерфейс» => «ООП-интерфейс». На самом деле это только часть правды. Мы слишком сужаем термины «интерфейс» и «абстракция» до ООП-понятий и тем самым отсекаем «неподходящие» парадигмы. Однако, идеи, лежащие в основе первых двух методик — более общие, они справедливы для всех миров, и знание других подходов никак не может быть лишним.
Касательно третьей методики можно сказать следующее. В виду своей природы, ФЯ располагают к написанию всяческих предметно-ориентированных языков — внутренних, внешних. Во-первых потому, что обвязочный код парсеров и трансляторов получается коротким, понятным и легко модифицируемым. Во-вторых, синтаксис ФП-языков позволяет делать встроенные DSL, не перегружая основной код. Предметно-ориентированные языки способны радикально сократить сложность программы и уменьшить количество ошибок. Побочный (а может, и основной) эффект от реализации DSL — более четкое понимание предметной области. Код на предметно-ориентированном языке гораздо лучше подходит для формализации требований, чем низкоуровневые подходы.
Стоит однако признать: специализированные языки сильно недооценены в реальной жизни. Бытует миф, что это сложно, трудно и дорого в поддержке. Его причина в том, что императивному программисту для создания внешнего DSL нужно выйти из своей зоны комфорта и представить себе иной синтаксис, семантику, и, может быть даже — иную парадигму. Не зная этого, он сможет придумать DSL лишь в собственных рамках, что автоматически приведет его к текущему коду, а следом — и к вопросу «Зачем тогда DSL?». Но и это еще не все. Как реализовать DSL? Доминирующие ООП-языки (за редким исключением) не предлагают элегантного решения в сравнении с функциональными; действительно, при традиционном подходе требуются значительные усилия, чтобы внешний DSL не увеличивал риски. Для снятия рисков нужно изучить иные парадигмы и подтянуть теорию; как следствие, сложность реализации внешнего DSL на привычном языке переносится на саму идею DSL. Данное заблуждение почему-то считается сильным аргументом «против»… И оно легко разбивается тем, что помимо внешнего DSL существует и внутрений (встроенный, embedded DSL, eDSL). Для внешнего DSL, невыразимого грамматикой текущего языка, нужны, как минимум, парсер и транслятор, — что приводит к добавочному обслуживающему коду. Но внутренний DSL находится в пределах грамматики текущего языка, значит, никаких парсеров и трансляторов не нужно. Однако, придумать иную организацию кода все-таки нужно; и опять мы пришли к тому, что без широкого программистского кругозора не обойтись. И это естественное требование к современному программисту. Что ж, Мартин Фаулер нам в помощь.
Что еще можно сказать об архитектуре в применении к ФП? Важный момент состоит в том, что в ФП побочные эффекты нежелательны. Но в любой большой программе работать с внешним миром надо; то есть, должны быть какие-либо механизмы контроля побочных эффектов. И они есть. Пресловутые монады Haskell — отличный вариант, но это скорее инструмент более низкого дизайна, чем элемент общей архитектуры. Так, код общения с внешним сервером может быть реализован в рамках монады IO, — что будет не сильно отличаться от императивщины. Второе решение — код может быть задекларирован на DSL. В таком DSL есть кирпичики с побочными эффектами, есть кирпичики с чистым поведением, но все они — лишь декларация, следовательно, весь код будет чист и менее подвержен ошибкам. Вероятно, он будет понятный, гибкий, комбинируемый и управляемый, по сути — конструктор. Исполнение этого кода можно возложить на конечный автомат, работающий над тонкой прослойкой из монадического IO-кода. И пожалуйста, мы получили вполне хорошее архитектурное решение, благодаря которому также снизили сложность формализации наших бизнес-процессов.
Для борьбы с побочными эффектами есть и другое архитектурное решение, известное как "реактивное программирование". В применении к функциональным языкам стоит говорить о FRP, то есть, о Functional Reactive Programming. Данная концепция математична, поэтому хорошо ложится на ФП. Суть FRP — в распространении изменений по модели данных. Каждый элемент такой модели — это значение, зависящее других значений по нужным формулам. Таким образом, «реактивная модель» — это дерево, где листовые значения могут изменяться во времени, возбуждая волну по пересчету вышестоящих значений. Источниками значений могут быть любые функции, в том числе и с побочными эффектами. Код модели при этом будет декларативным и компонуемым.
Вообще, в функциональном программировании идиоматичнее всего код, написанный в комбинаторном стиле, как конструктор. Идея проста: из маленьких однотипных кирпичиков складывается сколь угодно большая самоприменимая система. Чем лучше спроектирован конструктор, тем мощнее и выразительнее код. Обычно комбинаторный код тоже является некоторым eDSL, в разы снижающем сложность разработки. Многие библиотеки Haskell используют этот принцип, например: Parsec, Netwire, HaXml, Lenses… Идея монадических парсерных комбинаторов была настолько удачной, что Parsec стал известен за пределами Haskell. Существуют его порты на F#, Erlang, Java, другие языки. Любопытно, что Parsec реализует аж три идеи: комбинаторы, DSL и монады, и все это органично связано в едином стройном API.
Теперь нетрудно выделить еще одну очень мощную методику борьбы со сложностью (название авторское):
4. Предметно-ориентированные комбинаторы (Domain-specific combinators).
DSC — это eDSL, элементы которого являются комбинаторами. Наиболее удобные DSC получаются на функциональных языках за счет синтаксиса (функции — суть комбинаторы преобразований), но и в обычных языках это возможно. Конечно, спроектировать DSC даже труднее, чем простой DSL, — из-за чего, вероятно, данный подход совершенно неизвестен в мэйнстриме.
Немного практики
Переходя от абстрактных размышлений к практике, обратимся к проекту большой игры «Big Space». Если кратко, это реалистичная космическая 3D-леталка реальных масштабов с полностью программируемыми игровыми элементами и, вероятно, с возможностью путешествий во времени. Любопытные могут заглянуть в дизайн-документ и другие сопутствующие материалы для более детального знакомства, а нам этого описания уже достаточно, чтобы продумывать общую архитектуру игры. Но сперва — небольшое отступление.
Начало любого проекта лежит в идее, которая, родившись, требует развития и осмысления. В случае «Big Space» главными помощниками в этом были карты памяти, которые отличным образом позволяют осознать и структурировать краеугольные моменты будущей игры. Начиная с обобщенных понятий (таких как «Концепция», «Космос», «Мотивация», «Изучение галактики»), можно спуститься глубже, пока не получим конкретные элементы игры. Карты памяти помогают также увидеть и отсеять противоречия и нестыковки.
Big Space: MM-01 'Концепция'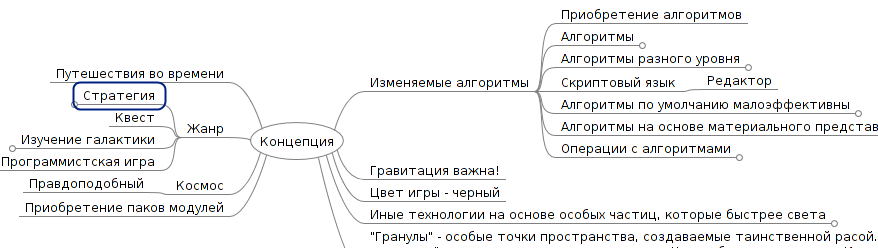
Можно ли рассматривать карты памяти как альтернативу вариантам использования? Вот статья, автор которой поднимает тот же вопрос. Из нее следует, что карты памяти являются более общим инструментом, так как легко могут содержать варианты использования. Карты памяти отвечают на вопрос «что есть вообще, и какие решения в частности», а варианты использования отвечают на вопрос «что позволено сделать для решения задачи». Последнее выражается в том, что с каждым вариантом использования обычно связана короткая история (user story), в которой по шагам расписаны высокоуровневые изменения в системе. И несколько таких вариантов будут являться рычагами, за которые нужно подергать пользователю, чтобы система приняла необходимое состояние. Можно сделать вывод, что карты памяти и варианты использования соотносятся также, как соотносятся декларативное (в стиле Prolog) и императивное программирование. В первом случае мы описываем, что именно хотим получить; во втором случае — описываем, как хотим этого добиться. То есть, карты памяти более подходят функциональному программированию, так как в ФП поощряются декларативные решения.
Заменив на первом шаге диаграмму вариантов использования, можно пойти дальше. Концепт-карты — родственники карт памяти — хорошо подходят для отображения требований на черновую архитектуру. Это достигается за счет трех этапов (названия авторские).
- Карта необходимости. Содержит настолько крупные блоки, насколько это возможно. Связи опциональны, блоки размещаются по тематике. Карта показывает, на чем вообще базируется игра. При проектировании нужно учесть самые общие требования; например, для требований «огромный реалистичный космос», «3D графика», «кроссплатформенность» будут присутствовать блоки Cloud Computing, OpenGL и SDL. Если нужен сторонний игровой движок, — его нужно обозначить именно здесь.
- Карта элементов. В вольной форме раскрываем предыдущую диаграмму, не заботясь о структуре. Элементами являются такие блоки: «подсистема», «концепция», «данные», «библиотека» «объект предметной области». Связи показывают самое общее представление о том, как система работает. Можно обозначить характер связей, например: «использует», «реализует» и другие. Блоки разделяются по слоям. Диаграмма должна учитывать большую часть концептуальных требований. Ничего страшного, если будут смешаны несколько уровней абстракции, появятся конкурирующие варианты, или что-то будет выглядеть не самым лучшим образом. Диаграмма лишь очерчивает поле деятельности и предлагает возможные решения, но не является конечной архитектурой программы.
- Карта подсистем. На данной диаграмме принимаются конкретные архитектурные решения из предложенных на втором этапе. Информация структурируется и размещается таким образом, чтобы отделить слои приложения. Указываются библиотеки и подходы к реализации. Диаграмма не опишет полностью высокоуровневый дизайн, но покажет важные зависимости между подсистемами и поможет их разделить по слоям.
Big Space: CM-01 Necessity Map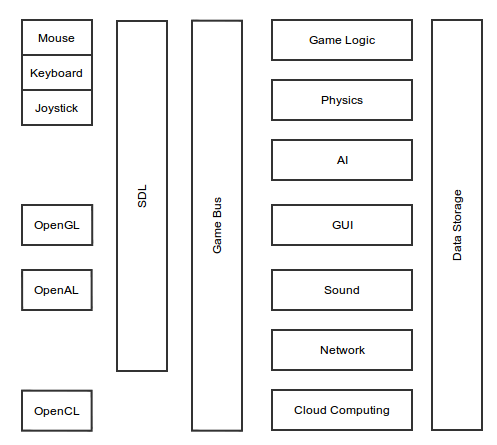
Big Space: CM-02 Elements Map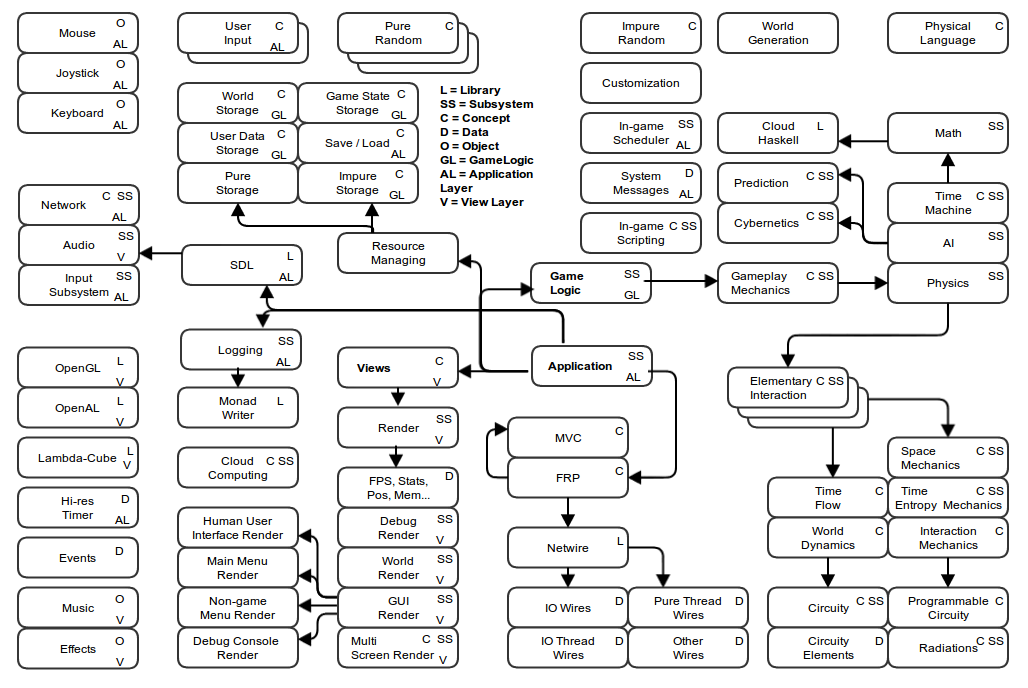
Big Space: CM-03 Subsystems Map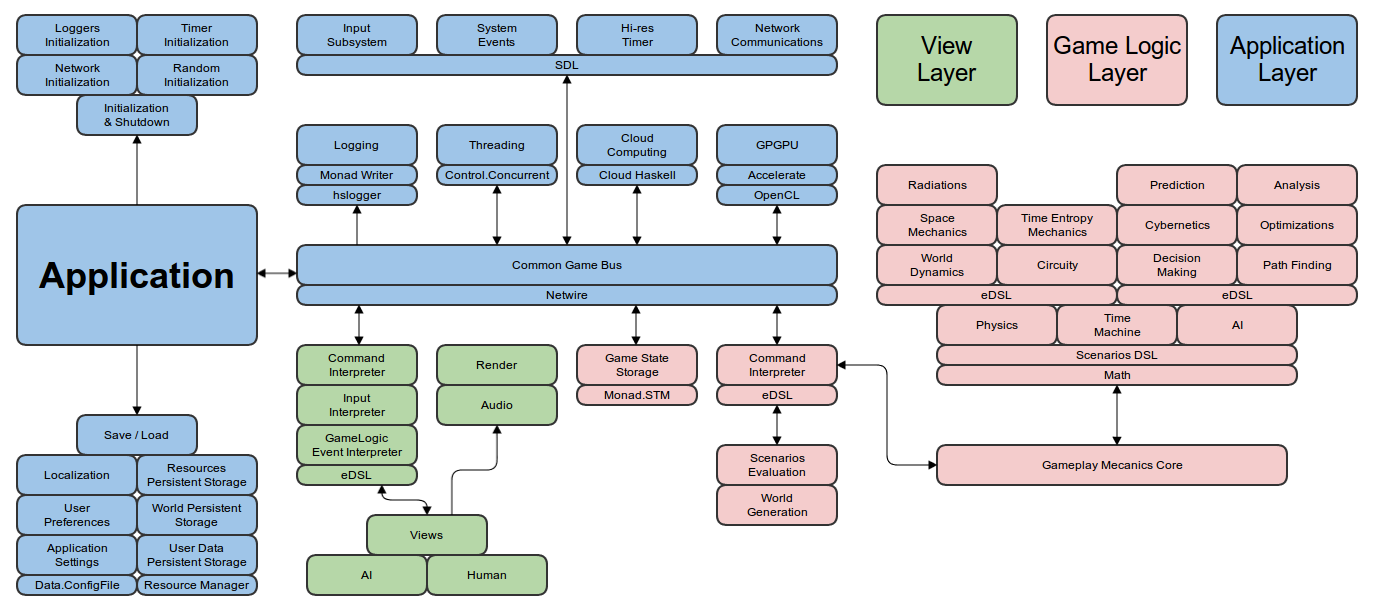
На последней диаграмме видно, что в игре три слоя: Views, Game Logic, Application (Mike McShaffry, Game Coding Complete). Слои «Views» и «Game Logic» отделены от основного кода собственными интерпретаторами команд и фасадами eDSL. При этом предполагается, что вся игровая логика, за исключением игрового состояния, будет реализована вне монады IO. Игровое состояние, хоть и относится и игровой логике, стоит отдельно, поскольку к нему требуется разделяемый доступ из представлений и со стороны приложения (для сетевого общения, для периодической подгрузки данных, для GPGPU и облачных вычислений). На диаграмме показано, что для работы с состоянием игры будет использована концепция Software Transactional Memory; также указаны библиотеки Netwire, SDL, Cloud Haskell и другие. Почти вся игровая логика, по замыслу, должна быть реализована с использованием нескольких внутренних и внешних языков. Конечно, предложенный вариант архитектуры — один из тысячи, и в диаграмме ничего не сказано о более низком уровне дизайна; нужны исследования и прототипы, чтобы найти узкие места или просчеты. Но в целом, архитектура выглядит стройной и аккуратной.
После диаграммы подсистем можно перейти к следующему этапу проектирования. Имея знания об архитектуре, можно построить две модели: модель данных и модель типов, и расписать интерфейсы всех публичных модулей. Наконец, последним этапом будет реализация этих интерфейсов и написание внутренних библиотек. Но эти заключительные этапы уже являются низкоуровневым дизайном и имплементацией. Частично мы рассмотрим их в следующих главах.
Заключение
Представленный в этой статье подход является нисходящим, то есть, направленным от наиболее общего к наиболее частному. Мы увидели, что UML слабо применим к ФП. Поэтому мы спроектировали верхнеуровневую архитектуру, придумав свои диаграммы и построив свою методологию. Мы также узнали о методах борьбы со сложностью, которые обязательно нам пригодятся при дизайне подсистем.

