
Не секрет, что каждый интернет-магазин должен помогать пользователям найти то, что им нужно. Особенно, если товаров у вас много (> 10). На помощь приходит каталогизация товаров, но разбить товары по категориям — полдела. Товары внутри категории нужно уметь фильтровать по их свойствам. Особенно, если товары у вас разношёрстные, например, одежда, электроника, ювелирные изделия и т.д. И тут любой разработчик, пишущий свой e-commerce продукт, сталкивается с неприятными реалиями жизни: у товаров могут быть совершенно разные свойства, у некоторых товаров они могут отсутствовать, некоторые товары по одному свойству могут попадать под разные значения (цвет платья то ли синий, то ли голубой, соответственно, неплохо бы его показать и по синему и по голубому цвету). Проще говоря, у вас EAV. Бывает ещё, что EAV вам диагностирует заказчик ближе к концу разработки, а то и просит добавить фильтр по динамическим свойствам уже после релиза.
Вы начинаете почёсывать за ухом, понимая, что в реляционную модель у вас ничего не укладывается, вы же уже выбрали MySQL в качестве СУБД, если вы хороший веб-разработчик, или, может, PostgreSQL, если вы про него читали, а адепты разных корпораций могут вообще выбрать их продукты, никто не запрещает. Чаще всего, тем не менее, это всё RDBMS, и динамические свойства туда вкручиваются не очень просто (читай: сложно), не каждому это под силу.
Вот, для примера, маленький кусочек диаграммы БД у популярной e-commerce платформы Magento:

(по клику в полный размер)
Вот и перед нами была поставлена задача сделать такой фильтр каталога для ювелирного магазина. А свойства у товаров у нас тогда вообще лежали в json-е в MySQL, т.к. нужны были только на странице самого товара и нигде более. Немного улучшало наше положение то, что это был ювелирный интернет-магазин, и свойства в нём можно было установить изначально, такие как размер кольца, тип металла, цвет металла, вставка. Тем не менее, полученное решение универсально, доработать код можно легко под полностью динамические наборы свойств у товаров.
Решено было, что менять половину БД и больше половины кода для добавления фильтра не есть хорошо, поэтому на помощь мы позвали in-memory key-value storage called Redis, в частности, его крутую возможность работать побитово со строками, операции: SETBIT, GETBIT, BITOP, BITCOUNT. О значении команд легко догадаться не заглядывая в документацию.
Схема хранения фильтров в Redis была следующей:
- Один ключ — это одно значение свойства товара, например, size-18: или color-red:
- Данными в каждом ключе являлся битмап длиной N бит, где N — количество товаров всего в магазине. Соответственно, позиция бита в битмапе — это ID товара, а сам бит показывает, принадлежит ли данный ID фильтру с таким значением.
Пример, для лучшего понимания:
| ID товаров (позиция бита) | ID: 1 | ID: 2 | ID: 3 | ID: 4 | ID: 5 |
| redis-key | redis-value | ||||
| size-17: | 0 | 0 | 1 | 0 | 1 |
| size-18: | 1 | 1 | 0 | 0 | 0 |
| size-19: | 0 | 0 | 0 | 1 | 0 |
| color-red: | 1 | 1 | 1 | 0 | 1 |
| color-green: | 0 | 0 | 1 | 1 | 1 |
Таким образом, в редисе у нас 5 пар ключ-значение, т.к. имеем два фильтра — по цвету (2 варианта) и по размеру (3 варианта). В магазине всего 5 товаров, поэтому битмап состоит из 5 бит. Из таблицы видно, что товар с ID 2 — красного цвета, размера 18, а товар с ID 3 — размера 17, но имеет в себе как красный, так и зелёный цвет.
Для применения фильтра к каталогу товаров, достаточно произвести операцию побитового AND для выбранных пользователем значений фильтров. Например, человек хочет товар зелёного цвета размера 18, тыкает в фильтре две галки, а мы делаем:
BITOP AND result-key size-18 color-green
после чего в result-key у нас будет лежать битмап, представлющий собой побитовое умножение этих двух битмапов. Нам остаётся только посчитать места, в которых у нас стоят единички, позиции единичек и будут ID товаров с заданными фильтрами:
$bytes = str_split($result_key); $ids = []; // resulting product IDs for ($i = 0; $i < count($bytes); $i++) // iterate in bytes (8 products at once) for ($j = 7; $j >= 0; $j--) // iterate over bits in current 8-products chunk if ($bytes[$i] & (1 << $j)) // >0 if bit was 1, otherwise 0 $ids[] = 8*$i + (8-$j); // calculate product ID and append it
Генерация битмапов происходит на моменте добавления / изменения товара в админке, в зависимости от имеющихся свойств товара мы делаем BITSET в нужный фильтр, и всё.
 плюсы такого решения:
плюсы такого решения:1) Жрёт мало памяти. У нас > 50000 товаров, около 100 значений фильтров, то есть 50000 * 100 = 5 000 000 бит = всего 625 килобайт памяти.
2) Очень быстро. Сложность побитовой операции O(N), тем не менее, строки у нас не миллионами байт измеряются, а перемножить пару-тройку битмапов ио 50000 бит — задача пары микросекунд для процессора. Overall, в худшем случае (перемножение всех фильтров), замеряя разницу времени в PHP до отправки команды в REDIS и после получения результата — 40мс (это с доп. функцией из п.3, далее). Вполне реалтаймовая генерация страницы, для веба пойдёт. Если кажется много — просьба кешируйте результат, но нас это удовлетворило вполне.
3) Возможность подсчёта кол-ва товаров в каждом фильтре и категории. Это стало полезным side-эффектом. Мы теперь можем посчитать количество товаров для каждого значения фильтра, доступное в данный момент. Да, это требует побитовое умножение текущего result-key (текущей выборки товаров) на каждое значение фильтра, а затем выполнение BITCOUNT. Мы это реализовали, теперь можем динамически скрывать фильтры с пустым множеством товаров (человек, выбрав платиновые кольца с бриллиантами, не видит фильтра по цене «до 3 000 рублей»).
 минусы такого решения:
минусы такого решения:1) Невозможность закодировать фильтры типа range, например, где цену пользователь может фильтровать вручную влоть до рубля. Ну такие, с ползунками ОТ и ДО, знаете. Которые ещё на мобилах никогда не работают. В нашем магазине фильтр по ценам представлял из себя просто пять вариантов (до 3000, 3000-10000 и т.д.), соответственно, закодировали их как 5 битмапов price-0-3000:, price-3000-10000: и т.д.
2) Необходимость передачи списка выбранных ID в MySQL для выборки их данных. Это, конечно, нехорошо, что мы из редиса кидаем список ID для выборки
SELECT * FROM products WHERE id IN (....)
Но, как оказалось, работает крайне быстро. В худшем случае вся страница каталога со всеми выбранными фильтрами для всех категорий генерировалась за 600мс, если не ошибаюсь. Пруф для нескольких фильтров:
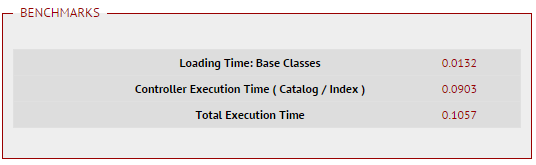
Итогом, прикрутить это дело оказалось очень быстро, биндинги Redis для PHP имеются, сам Redis очень примитивен и лёгок для освоения за один день.

