Продолжу начатую в моей предыдущей статье работу по оптимизации алгоритма. Вкратце расскажу, что было сделано. Были взяты готовые java исходники и каскадная модель одной из реализаций алгоритма Виола-Джонса. Данный алгоритм используется для поиска объектов на фотографии, в частности для поиска лиц. Тестирование проводил на своем телефоне, по результатам было получено, что изначальный код на java работал 54 секунды на фотографии размером 300 на 400. Это было слишком медленно, переписанный мною код на C++ показал результат в 14 секунд. В комментариях было предложено догнать java-реализацию до C++ следующим образом: отпрофилировать и найти узкие места, и заменить двумерный массив на одномерный. Также у меня в планах было распараллелить алгоритм на C++. Все было сделано и исследовано, результаты ниже.
Профилируем java-релизацию. Снимаем статистику в момент работы основной части алгоритма. Видим такую картину(результат в файле кому интересно):
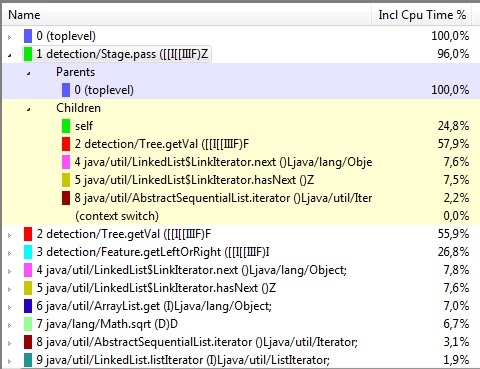
методы List'ов съедают немало времени. В данной ситуации все List'ы можем спокойно заменить на массивы, что на C++ и используется. Заменяем и получаем следующий результат(в файле):
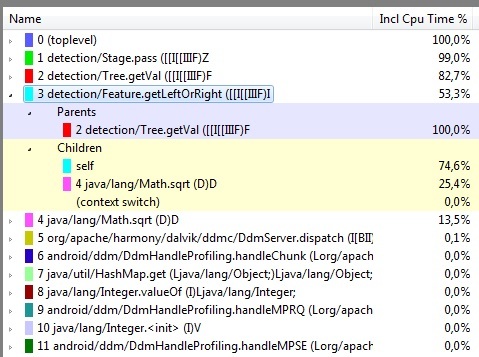
обратите внимание на Math.sqrt, процент её исполнения поднялся с 6.7 до 13.5, что значит — другие уменьшили потребления времени, и запуск на телефоне показал — 38 секунд. Все остальное время уходит на примитивные методы: умножение, деление и получение элемента массива и Math.sqrt. Соответственно, уже не вижу, где и что можно изменить, т.к. C++ повторяет код в точности.
Одномерные массивы вместо двумерных. Меняем следующий код:
на:
и в соответствующих местах использования:
результат точно такой же. Попробуем сократить количество операций умножения для вычисления элемента массива, т.е. сделаем так:
результат не изменился. Одномерный массив не дал плюсов, только минусы в читабельности кода.
И так, с Java закончили на результате 38 против 14 секунд на C++.
Распараллеливание. Попробуем распараллелить алгоритм написанный на C++ на телефоне GT-I9300I с четырехядерным процессором. На Android'е можно применить posix threads, как написано в документации он немного урезан, но нам достаточно создать потоки, передать им параметры и дождаться их исполнения. Все это делается просто:
Получаем следующий результат 14 секунд для одного потока, 8 секунд для двух потоков, 5 секунд для трех и 4 секунды для четырех и более потоков. На виртуальном устройстве Nexus S с одноядерным процессором распараллеливание не привело ни к чему.
Исходники полученного алгоритма можно скачать здесь. Использовать следующим образом:
где inputHaas — поток модели, т.е. файл haarcascade_frontalface_default.xml из исходного алгоритма, useCpp — использовать C++ или нет, threadsNum — количество потоков для C++ кода. Предполагается, что Detector инициируется один раз.
Итого. Замена LinkedList используемых в итерации на массивы в целом дало прирост для текущего алгоритма в 1.5 раза, но все еще отстает в 2,5 раза от реализации на C++. Перевод двумерного массива в одномерный не показал изменений. С помощью распараллеливания на C++ удалось ускорить процесс в 3 раза на четырехядерном процессоре, что уже намного лучше, но до идеала далеко. Можно посмотреть в сторону RenderScript — механизм для сложных вычислений на нативном уровне, может быть это даст какую-либо пользу.
Профилируем java-релизацию. Снимаем статистику в момент работы основной части алгоритма. Видим такую картину(результат в файле кому интересно):

методы List'ов съедают немало времени. В данной ситуации все List'ы можем спокойно заменить на массивы, что на C++ и используется. Заменяем и получаем следующий результат(в файле):

обратите внимание на Math.sqrt, процент её исполнения поднялся с 6.7 до 13.5, что значит — другие уменьшили потребления времени, и запуск на телефоне показал — 38 секунд. Все остальное время уходит на примитивные методы: умножение, деление и получение элемента массива и Math.sqrt. Соответственно, уже не вижу, где и что можно изменить, т.к. C++ повторяет код в точности.
Одномерные массивы вместо двумерных. Меняем следующий код:
int[][] grayImage=new int[width][height];
int[][] squares=new int[width][height];
на:
int[] grayImage=new int[width * height];
int[] squares=new int[width * height];
и в соответствующих местах использования:
int total_x = grayImage[(i + w) * height + j + h] + grayImage[i * height + j] - grayImage[i * height + j + h] - grayImage[(i + w) * height + j];
int total_x2 = squares[(i + w) * height + j + h] + squares[i * height + j] - squares[i * height + j + h] - squares[(i + w) * height + j];
...
rect_sum += (int) ((grayImage[rx2 * height + ry2] - grayImage[rx1 * height + ry2] - grayImage[rx2 * height + ry1] + grayImage[rx1 * height + ry1]) * r.weight);
}
результат точно такой же. Попробуем сократить количество операций умножения для вычисления элемента массива, т.е. сделаем так:
int iwh = (i + w) * height;
int ih = i * height;
int total_x = grayImage[iwh + j + h] + grayImage[ih + j] - grayImage[ih + j + h] - grayImage[iwh + j];
int total_x2 = squares[iwh + j + h] + squares[ih + j] - squares[ih + j + h] - squares[iwh + j];
...
int rx2h = rx2 * height;
int rx1h = rx1 * height;
rect_sum += (int) ((grayImage[rx2h + ry2] - grayImage[rx1h + ry2] - grayImage[rx2h + ry1] + grayImage[rx1h + ry1]) * r.weight);
результат не изменился. Одномерный массив не дал плюсов, только минусы в читабельности кода.
И так, с Java закончили на результате 38 против 14 секунд на C++.
Распараллеливание. Попробуем распараллелить алгоритм написанный на C++ на телефоне GT-I9300I с четырехядерным процессором. На Android'е можно применить posix threads, как написано в документации он немного урезан, но нам достаточно создать потоки, передать им параметры и дождаться их исполнения. Все это делается просто:
#include <pthread.h>
...
extern "C" {
struct ThreadArgument {
void *array;
int threadNum;
};
void *worker_thread(void *arg) {
ThreadArgument *arg1 = (ThreadArgument*) arg;
((Detector*) (arg1->array))->workerTansient(arg1->threadNum);
pthread_exit(NULL);
}
}
...
pthread_t m_pt[threadsNum - 1];
if (threadsNum > 1) {
res2 = new VectorRects*[threadsNum - 1];
for (int l = 0; l < threadsNum - 1; l++) {
ThreadArgument* args = new ThreadArgument;
args->array = (void*)this;
args->threadNum = l + 1;
int success = pthread_create(&m_pt[l], NULL, worker_thread, args);
if (success == 0) {
__android_log_print(ANDROID_LOG_INFO, "Detector", "thread %d started", l);
}
}
}
__android_log_print(ANDROID_LOG_INFO, "Detector", "gettFaces3 baseScale=%f maxScale=%f scale_inc=%f", baseScale, maxScale, scale_inc);
ret = getResult(0);
if (threadsNum > 1) {
for (int l = 0; l < threadsNum - 1; l++) {
int success = pthread_join(m_pt[l], NULL);
for (int b = 0; b < res2[l]->currIndex; b++) {
ret->addRect(res2[l]->rects[b]);
}
}
}
...
VectorRects* Detector::workerTansient(int threadNum)
{
__android_log_print(ANDROID_LOG_INFO, "Detector", "workerTansient thread running %d", threadNum);
res2[threadNum - 1] = getResult(threadNum);
return NULL;
}
...
Получаем следующий результат 14 секунд для одного потока, 8 секунд для двух потоков, 5 секунд для трех и 4 секунды для четырех и более потоков. На виртуальном устройстве Nexus S с одноядерным процессором распараллеливание не привело ни к чему.
Исходники полученного алгоритма можно скачать здесь. Использовать следующим образом:
Detector detector = Detector.create(inputHaas);
List<Rectangle> res = detector.getFaces(image, 1.2f, 1.1f, .05f, 2, true, useCpp, threadsNum);
где inputHaas — поток модели, т.е. файл haarcascade_frontalface_default.xml из исходного алгоритма, useCpp — использовать C++ или нет, threadsNum — количество потоков для C++ кода. Предполагается, что Detector инициируется один раз.
Итого. Замена LinkedList используемых в итерации на массивы в целом дало прирост для текущего алгоритма в 1.5 раза, но все еще отстает в 2,5 раза от реализации на C++. Перевод двумерного массива в одномерный не показал изменений. С помощью распараллеливания на C++ удалось ускорить процесс в 3 раза на четырехядерном процессоре, что уже намного лучше, но до идеала далеко. Можно посмотреть в сторону RenderScript — механизм для сложных вычислений на нативном уровне, может быть это даст какую-либо пользу.
