Итак, пока наши новые повелители отдыхают, давайте я попробую рассказать как работает AlphaGo. Пост подразумевает некоторое знакомство читателя с предметом — нужно знать, чем отличается Fan Hui от Lee Sedol, и поверхностно представлять, как работают нейросети.
Disclaimer: пост написан на основе изрядно отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и наличие уточняющих вопросов
Как все знают, компьютеры плохо играли в Го потому, что там очень много возможных ходов и пространство поиска настолько велико, что прямой перебор помогает мало.
Лучшие программы используют так называемый Monte Carlo Tree Search — поиск по дереву с оценкой нодов через так называемые rollouts, то есть быстрые симуляции результата игры из позиции в ноде.
AlphaGo дополняет этот поиск по дереву оценочными функциями на основе deep learning, чтобы оптимизировать пространство перебора. Статья изначально появилась в Nature (и она там за пейволлом), но в интернетах ее можно найти. Например тут — https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
Берем 160K доступных в онлайне игр игроков довольно высокого уровня и тренируем нейросеть, которая предсказывает по позиции следующий ход человека.
Архитектура сети — просто 12 уровней convolution layers с нелинейностью и softmax на каждую клетку в конце. Такая глубина в целом сравнима с сетями для обработки изображений прошлого поколения (гугловский Inception-v1, VGG, все эти дела)
Важный момент — что нейросети дается на вход:
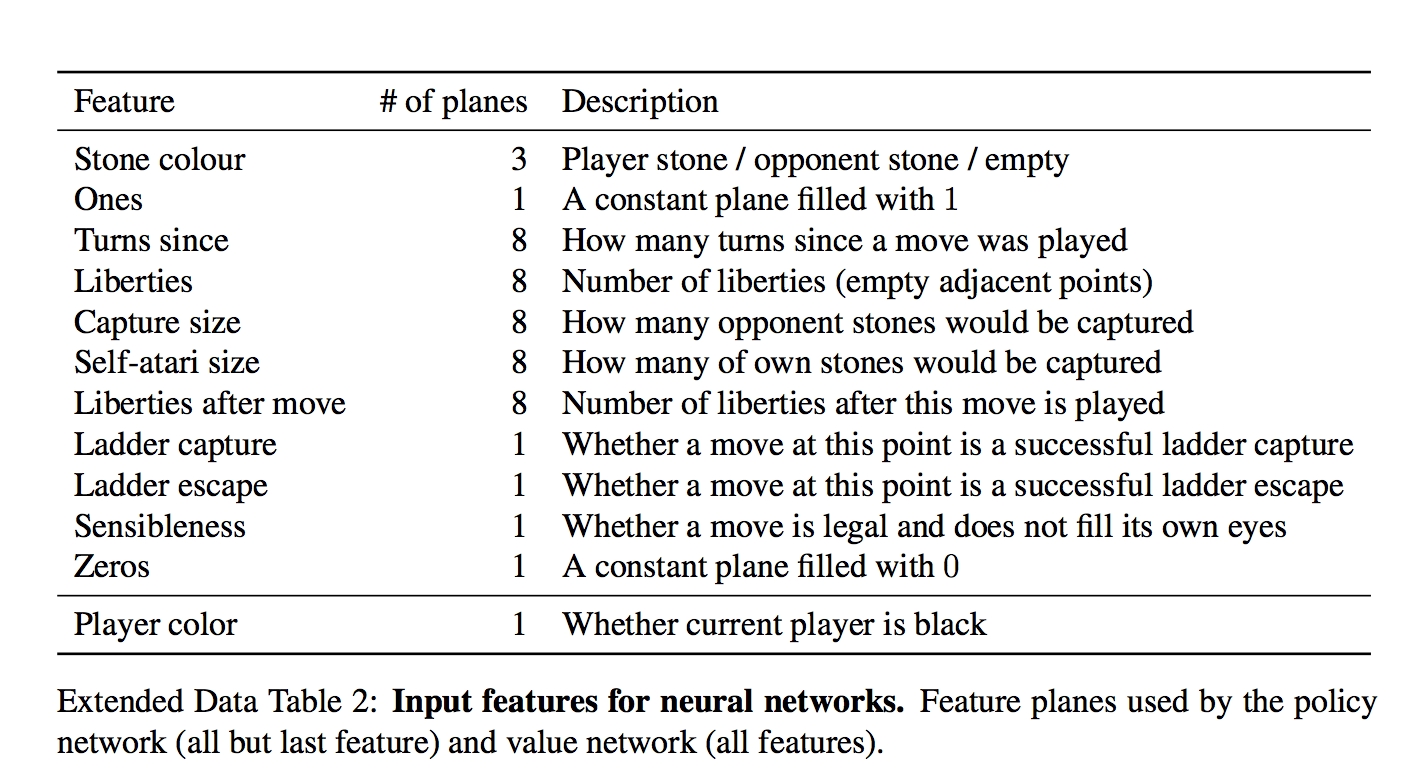
Для каждой клетки на вход дается 48 фич, они все есть в таблице (каждое измерение — это бинарная фича)
Набор интересный. На первый взгляд кажется, сети нужно давать только есть ли в клетке камень и если есть, то какой. Но фиг там!
Есть и тривиально вычисляющиеся фичи типа "количество степеней свободы камня", или "количество камней, которые будут взяты этим ходом"
Есть и формально неважные фичи типа "как давно было сделан ход"
И даже специальная фича для частого явления "ladder capture/ladder escape" — потенциально долгой последовательности вынужденных ходов.
а что за "всегда 1" и "всегда 0"?
Они просто чтобы добить количество фич до кратного 4-м, мне кажется.
И вот на этом всем сетка учится предсказывать человеческие ходы. Предсказывает с точностью 57% и к этому надо относиться осторожно — цель предсказания, человеческий ход, все же неоднозначен.
Авторы показывают, впрочем, что даже небольшие улучшения в точности сильно сказываются на силе в игре (сравнивая сетки разной мощности)
Отдельно от SL-policy, тренируют fast rollout policy — очень быструю стратегию, которая является просто линейным классификатором.
Ей на вход дают еще больше заготовленных фич

То есть, ей дают фичи в виде заранее заготовленных паттернов
Она гораздо хуже, чем модель с глубокой сетью, но зато сверх-быстрая. Как она используется — будет понятно дальше
Выбираем противника из пула прошлых версий сети случайно (чтобы не оверфитить на саму себя), играем с ним партию до конца просто выбирая наиболее вероятный ход из предсказания сети, опять же без всякого перебора.
Единственный reward — это собственно результат игры, выиграл или проиграл.
После того, как reward известен, вычисляем как нужно сдвинуть веса — проигрываем партию заново и на каждом ходу двигаем веса, влияющие на выбор выбранной позиции, по градиенту в + или в — в зависимости от результата. Другими словами, применяем этот reward как направление градиента к каждому ходу.
(для любознательных — там чуть более тонко и градиент умножается на разницу между результатом и оценкой позиции через value network)
И вот повторяем и повторяем этот процесс — после этого RL-policy значительно сильнее SL-policy из первого шага.
Предсказание этой натренированной RL-policy уже рвет большинство прошлых программ, играющих в Го, без всяких деревьев и переборов.
Включая DarkForest Фейсбука?
С ней не сравнивали, непонятно.
Интересная деталь! В оригинальной статье пишется, что этот процесс длился всего 1 день (остальные тренировки — недели).
Т.е. предсказывает всего одно значение от -1 до 1.
У нее ровно та же архитектура, что и у policy network (есть один лишний convolution layer, кажется) + естественно fully connected layer в конце.
То есть у нее те же фичи?
value network дают еще одну фичу — играет игрок черными или нет (policy network передают "свой-чужой" камень, а не цвет). Я так понимаю, это чтобы она могла учесть коми — дополнительные очки белым, за то что они ходят вторыми
Оказывается, что ее нельзя тренировать на всех позициях из игр людей — так как много позиций принадлежит игре с тем же результатом, такая сеть начинает оверфитить — т.е. запоминать, какая это партия, вместо того, чтобы оценивать позицию.
Поэтому ее обучают на синтетических данных — делают N ходов через SL network, потом делают случайный легальный ход, потом доигрывают через RL-network чтобы узнать результат, и обучают на ходе N+2 (!) — только на одной позицию за сгенерированную игру.
TL;DR: Policy network предсказывает вероятные ходы чтобы уменьшить ширину перебора (меньше возможных ходов в ноде), value network предсказывает насколько выигрышна позиция, чтобы уменьшить необходимую глубину перебора
Внимание, картинко!
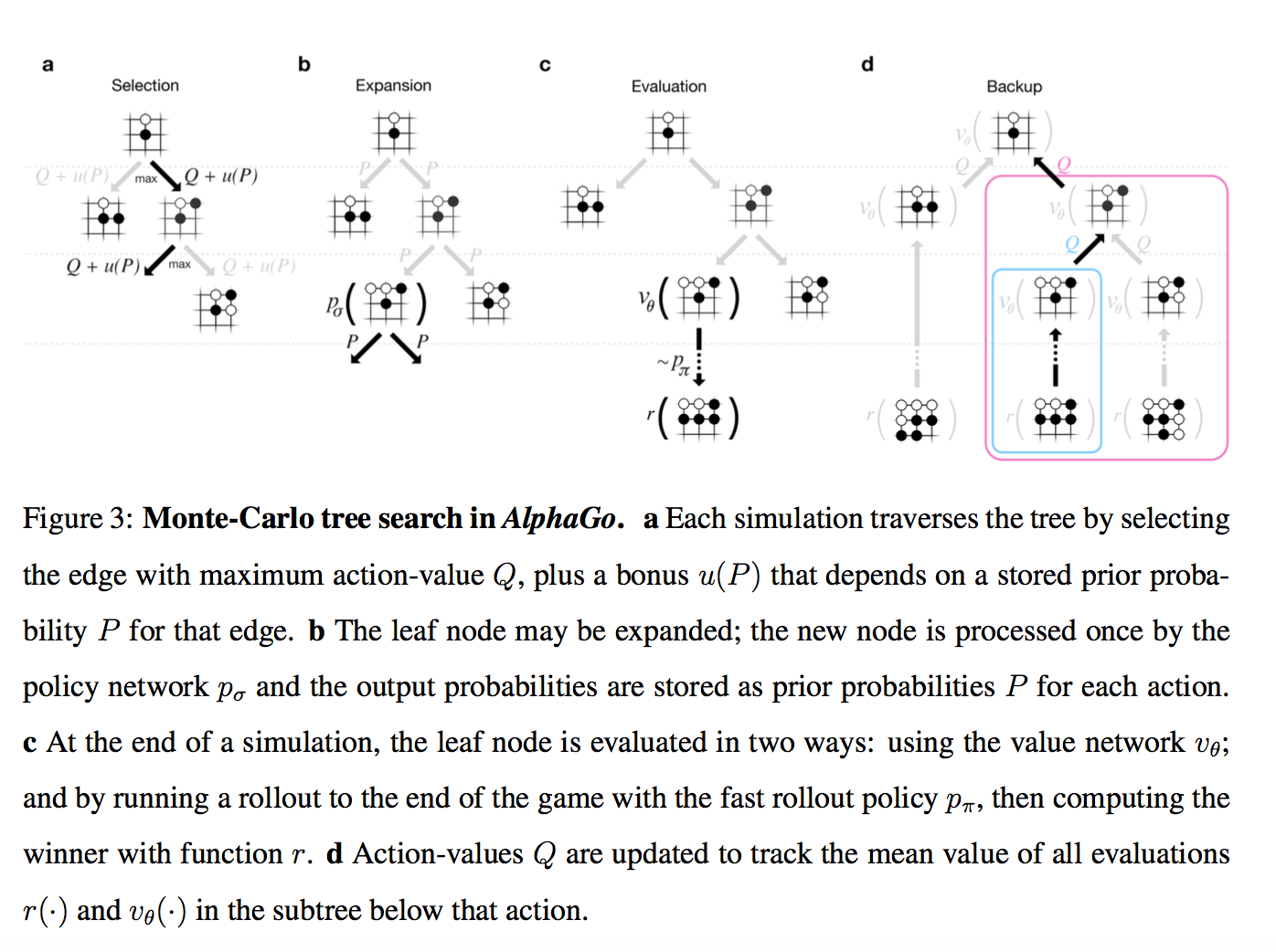
Итак, у нас есть дерево позиций, в руте — текущая. Для каждой позиции есть некое значение Q, которое означает насколько она ведет к победе.
Мы на этом дереве параллельно проводим большое количество симуляций.
Каждая симуляция идет по дереву туда, где больше Q + m(P). m(P) — это специальная добавка, которая стимулирует exploration. Она больше, если policy network считает, что у этого хода большая вероятность и меньше, если по этому пути уже много ходили
(это вариация стандартной техники multi-armed bandit)
Когда симуляция дошла по дереву до листа, и хочет походить дальше, где ничего еще нет…
То новый созданный нод дерева оценивается двумя способами
Результаты этих двух оценок смешиваются с неким весом (в релизе он натурально 0.5), и получившийся score записывается всем нодам дерева, через которые прошла симуляция, а Q в каждом ноде апдейтится как среднее от всех score для проходов через эту ноду.
(там совсем чуть-чуть сложнее, но можно пренебречь)
Т.е. каждая симуляция бежит по дереву в наиболее перспективную область (с учетом exploration), находит новую позицию, оценивает ее, записывает результат вверх по всем ходам, которые к ней привели. А потом Q в каждом ноде вычисляется как усреднение по всем симуляциям, которые через него бежали.
Собственно, все. Лучшим ходом объявляется нод, через который бегали чаще всех (оказывается, это чуть стабильнее чем этот Q-score). AlphaGo сдается, если у всех ходов Q-score < -0.8, т.е. вероятность выиграть меньше 10%.
Интересная деталь! В пейпере для изначальных вероятностей ходов P использовалась не RL-policy, а более слабая SL-policy.
Эмпирически оказалось, что так чуть лучше (возможно, к матчу с Lee Sedol уже не оказалось, но вот с Fan Hui играли так), т.е. reinforcement learning нужен был только для того, чтобы обучить value network
Напоследок, что можно сказать про то, чем версия AlphaGo, которая играла с Fan Hui (и была описана в статье), отличалась от версии, которая играет с Lee Sedol:
Пожалуй, все. Ждем 5:0!
Бонус: Попытка опенсурсной реализации. Там, конечно, еще пилить и пилить.
Disclaimer: пост написан на основе изрядно отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и наличие уточняющих вопросов
Как все знают, компьютеры плохо играли в Го потому, что там очень много возможных ходов и пространство поиска настолько велико, что прямой перебор помогает мало.
Лучшие программы используют так называемый Monte Carlo Tree Search — поиск по дереву с оценкой нодов через так называемые rollouts, то есть быстрые симуляции результата игры из позиции в ноде.
AlphaGo дополняет этот поиск по дереву оценочными функциями на основе deep learning, чтобы оптимизировать пространство перебора. Статья изначально появилась в Nature (и она там за пейволлом), но в интернетах ее можно найти. Например тут — https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
Сначала поговорим про составные кусочки, а потом как они комбинируются
Шаг 1: тренируем нейросеть, которая учится предсказывать ходы людей — SL-policy network
Берем 160K доступных в онлайне игр игроков довольно высокого уровня и тренируем нейросеть, которая предсказывает по позиции следующий ход человека.
Архитектура сети — просто 12 уровней convolution layers с нелинейностью и softmax на каждую клетку в конце. Такая глубина в целом сравнима с сетями для обработки изображений прошлого поколения (гугловский Inception-v1, VGG, все эти дела)
Важный момент — что нейросети дается на вход:
Для каждой клетки на вход дается 48 фич, они все есть в таблице (каждое измерение — это бинарная фича)
Набор интересный. На первый взгляд кажется, сети нужно давать только есть ли в клетке камень и если есть, то какой. Но фиг там!
Есть и тривиально вычисляющиеся фичи типа "количество степеней свободы камня", или "количество камней, которые будут взяты этим ходом"
Есть и формально неважные фичи типа "как давно было сделан ход"
И даже специальная фича для частого явления "ladder capture/ladder escape" — потенциально долгой последовательности вынужденных ходов.
а что за "всегда 1" и "всегда 0"?
Они просто чтобы добить количество фич до кратного 4-м, мне кажется.
И вот на этом всем сетка учится предсказывать человеческие ходы. Предсказывает с точностью 57% и к этому надо относиться осторожно — цель предсказания, человеческий ход, все же неоднозначен.
Авторы показывают, впрочем, что даже небольшие улучшения в точности сильно сказываются на силе в игре (сравнивая сетки разной мощности)
Отдельно от SL-policy, тренируют fast rollout policy — очень быструю стратегию, которая является просто линейным классификатором.
Ей на вход дают еще больше заготовленных фич
То есть, ей дают фичи в виде заранее заготовленных паттернов
Она гораздо хуже, чем модель с глубокой сетью, но зато сверх-быстрая. Как она используется — будет понятно дальше
Шаг 2: тренируем policy еще лучше через игру с собой (reinforcement learning) — RL-policy network
Выбираем противника из пула прошлых версий сети случайно (чтобы не оверфитить на саму себя), играем с ним партию до конца просто выбирая наиболее вероятный ход из предсказания сети, опять же без всякого перебора.
Единственный reward — это собственно результат игры, выиграл или проиграл.
После того, как reward известен, вычисляем как нужно сдвинуть веса — проигрываем партию заново и на каждом ходу двигаем веса, влияющие на выбор выбранной позиции, по градиенту в + или в — в зависимости от результата. Другими словами, применяем этот reward как направление градиента к каждому ходу.
(для любознательных — там чуть более тонко и градиент умножается на разницу между результатом и оценкой позиции через value network)
И вот повторяем и повторяем этот процесс — после этого RL-policy значительно сильнее SL-policy из первого шага.
Предсказание этой натренированной RL-policy уже рвет большинство прошлых программ, играющих в Го, без всяких деревьев и переборов.
Включая DarkForest Фейсбука?
С ней не сравнивали, непонятно.
Интересная деталь! В оригинальной статье пишется, что этот процесс длился всего 1 день (остальные тренировки — недели).
Шаг 3: натренируем сеть, которая "с одного взгляда" на расстановку говорит нам, какие у нас шансы выиграть! — Value network
Т.е. предсказывает всего одно значение от -1 до 1.
У нее ровно та же архитектура, что и у policy network (есть один лишний convolution layer, кажется) + естественно fully connected layer в конце.
То есть у нее те же фичи?
value network дают еще одну фичу — играет игрок черными или нет (policy network передают "свой-чужой" камень, а не цвет). Я так понимаю, это чтобы она могла учесть коми — дополнительные очки белым, за то что они ходят вторыми
Оказывается, что ее нельзя тренировать на всех позициях из игр людей — так как много позиций принадлежит игре с тем же результатом, такая сеть начинает оверфитить — т.е. запоминать, какая это партия, вместо того, чтобы оценивать позицию.
Поэтому ее обучают на синтетических данных — делают N ходов через SL network, потом делают случайный легальный ход, потом доигрывают через RL-network чтобы узнать результат, и обучают на ходе N+2 (!) — только на одной позицию за сгенерированную игру.
Итак, вот есть у нас эти обученные кирпичики. Как мы с их помощью играем?
TL;DR: Policy network предсказывает вероятные ходы чтобы уменьшить ширину перебора (меньше возможных ходов в ноде), value network предсказывает насколько выигрышна позиция, чтобы уменьшить необходимую глубину перебора
Внимание, картинко!
Итак, у нас есть дерево позиций, в руте — текущая. Для каждой позиции есть некое значение Q, которое означает насколько она ведет к победе.
Мы на этом дереве параллельно проводим большое количество симуляций.
Каждая симуляция идет по дереву туда, где больше Q + m(P). m(P) — это специальная добавка, которая стимулирует exploration. Она больше, если policy network считает, что у этого хода большая вероятность и меньше, если по этому пути уже много ходили
(это вариация стандартной техники multi-armed bandit)
Когда симуляция дошла по дереву до листа, и хочет походить дальше, где ничего еще нет…
То новый созданный нод дерева оценивается двумя способами
- во-первых, через описанный выше value network
- во-вторых, играется до конца с помощью супер-быстрой модели из Шага 1 (это и называется rollout)
Результаты этих двух оценок смешиваются с неким весом (в релизе он натурально 0.5), и получившийся score записывается всем нодам дерева, через которые прошла симуляция, а Q в каждом ноде апдейтится как среднее от всех score для проходов через эту ноду.
(там совсем чуть-чуть сложнее, но можно пренебречь)
Т.е. каждая симуляция бежит по дереву в наиболее перспективную область (с учетом exploration), находит новую позицию, оценивает ее, записывает результат вверх по всем ходам, которые к ней привели. А потом Q в каждом ноде вычисляется как усреднение по всем симуляциям, которые через него бежали.
Собственно, все. Лучшим ходом объявляется нод, через который бегали чаще всех (оказывается, это чуть стабильнее чем этот Q-score). AlphaGo сдается, если у всех ходов Q-score < -0.8, т.е. вероятность выиграть меньше 10%.
Интересная деталь! В пейпере для изначальных вероятностей ходов P использовалась не RL-policy, а более слабая SL-policy.
Эмпирически оказалось, что так чуть лучше (возможно, к матчу с Lee Sedol уже не оказалось, но вот с Fan Hui играли так), т.е. reinforcement learning нужен был только для того, чтобы обучить value network
Напоследок, что можно сказать про то, чем версия AlphaGo, которая играла с Fan Hui (и была описана в статье), отличалась от версии, которая играет с Lee Sedol:
- Кластер мог стать больше. Максимальная версия кластера в статье — 280 GPUs, но Fan Hui играл с версией с 176 GPUs.
- Похоже, стала больше тратить времени на ход (в статье все эстимейты даны для 2 секунд на ход) + добавился некий ML на тему менеджмента времени
- Было больше времени на тренировку сетей до матча. Мое личное подозрение — принципиально то, что больше времени на reinforcement learning. 1 день в изначальной статье это как-то даже не смешно.
Пожалуй, все. Ждем 5:0!
Бонус: Попытка опенсурсной реализации. Там, конечно, еще пилить и пилить.

