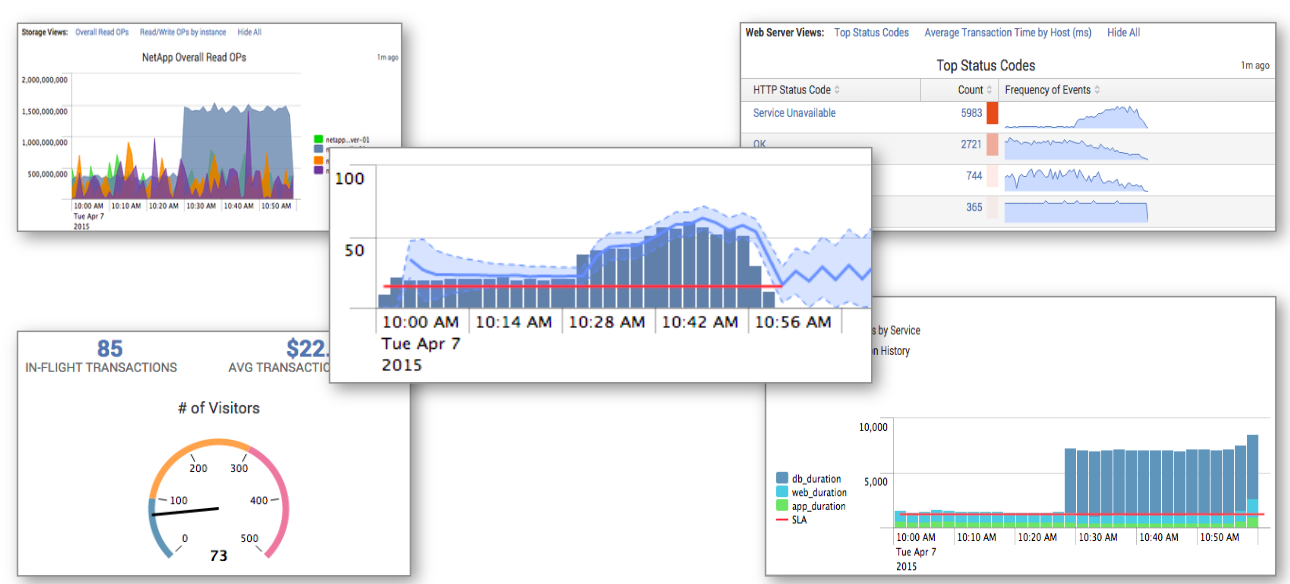
В данной статье мы расскажем и покажем как загрузить данные в Splunk, как строить поисковые запросы в системе на основе встроенного языка SPL и как можно их визуализировать. Это чисто практическая «How to» статья на основе тестовых данных, доступ к которым предоставляется свободно и доступен для скачивания всем желающим.
После прочтения и практического повторения Вы научитесь:
- Пользоваться базовым функционалом системы
- Загружать данные в Splunk
- Строить базовые поисковые запросы
- Визуализировать полученные результаты
Загрузка данных в систему
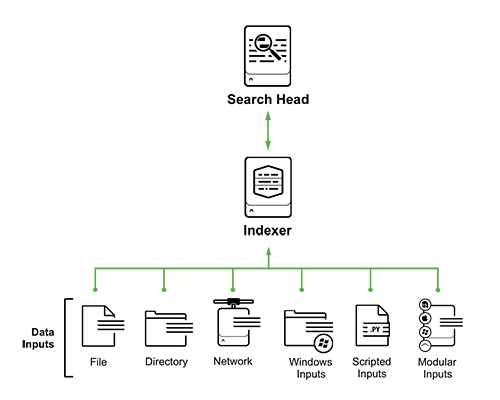
В системе можно выделить 5 основных источников сбора логов (это не полный список):
- Files and Directories: Splunk может разово забирать или мониторить конкретный файл или директорию с файлами, причем самостоятельно следит за изменением
- Network events: данные, поступающие с сетевых портов (syslog например)
- Windows sources: журналы событий (event log) Windows, события AD
- Scripted Inputs: данные собираемые посредством скриптов
- Modular Inputs: забор данных из специфических платформ, систем и приложений
В данной статье, для наглядности мы будем использовать наиболее простой метод. Мы просто загрузим тестовый файл в Splunk c локального компьютера. Понятно, что в истории с Enterprise использованием так никто не делает, и как раз используются варианты описанные выше вместе с агентами (forwarder), стоящими на целевых системах, и тогда инфраструктура выглядит следующим образом:
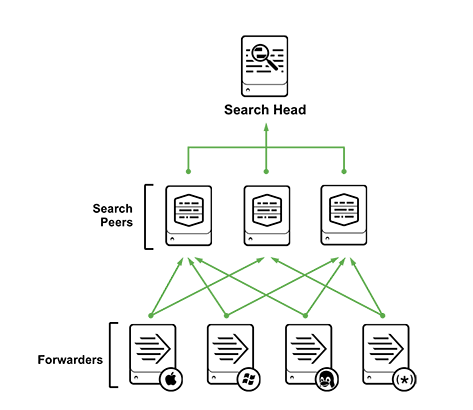
Но в нашем учебном примере, нам будет достаточно одного скаченного на локальный компьютер бесплатного Splunk Enterprise Free. Инструкции по установке вы можете найти в нашей предыдущей статье.
Теперь когда Вы скачали данные и установили Splunk их надо загрузить в него. На самом деле это достаточно просто (инструкция), потому что данные заранее подготовлены. Важно! Не нужно разархивировать архив.
SPL запросы
Ключевые особенности языка SPL:
- 140+ поисковых команд
- Синтаксис похож на Unix pipeline и SQL и оптимизирован на данные с временной отметкой
- SPL позволяет искать, фильтровать, модифицировать, обогащать, совмещать и удалять
- SPL включает функционал машинного обучения и поиска аномалий
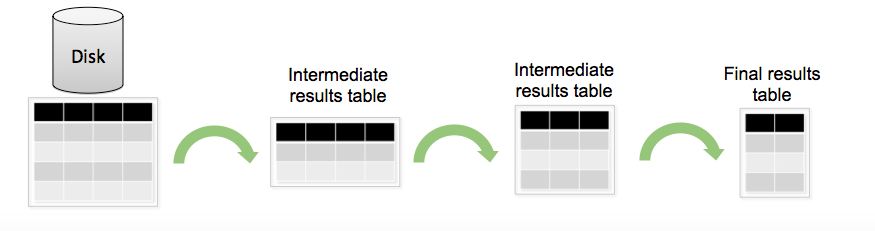
Структура SPL:
Стандартно SPL запрос можно разделить на несколько этапов: фильтрация и выбор нужных данных, затем создание новых полей на основе уже существующих, затем агрегирование данных и вычисление статистик, и в конце переименование полей, сортировка другими словами облагораживание вывода.
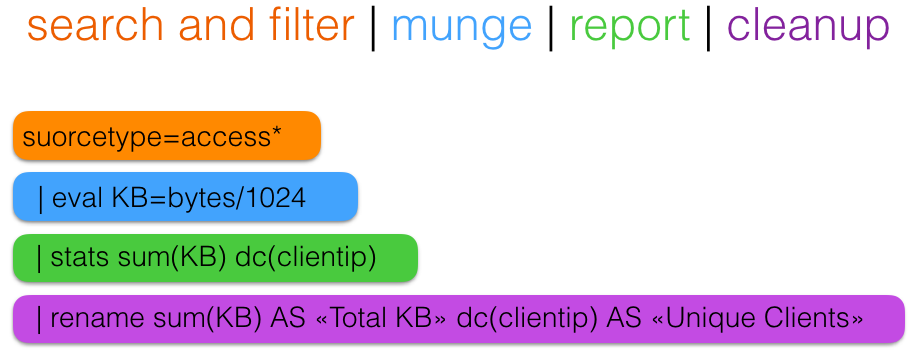
После того как Вы загрузили данные в систему вы можете осуществлять поиски по ним (ниже примеры запросов, с результатами выполнения):
Поисковый интерфейс имеет следующий вид:
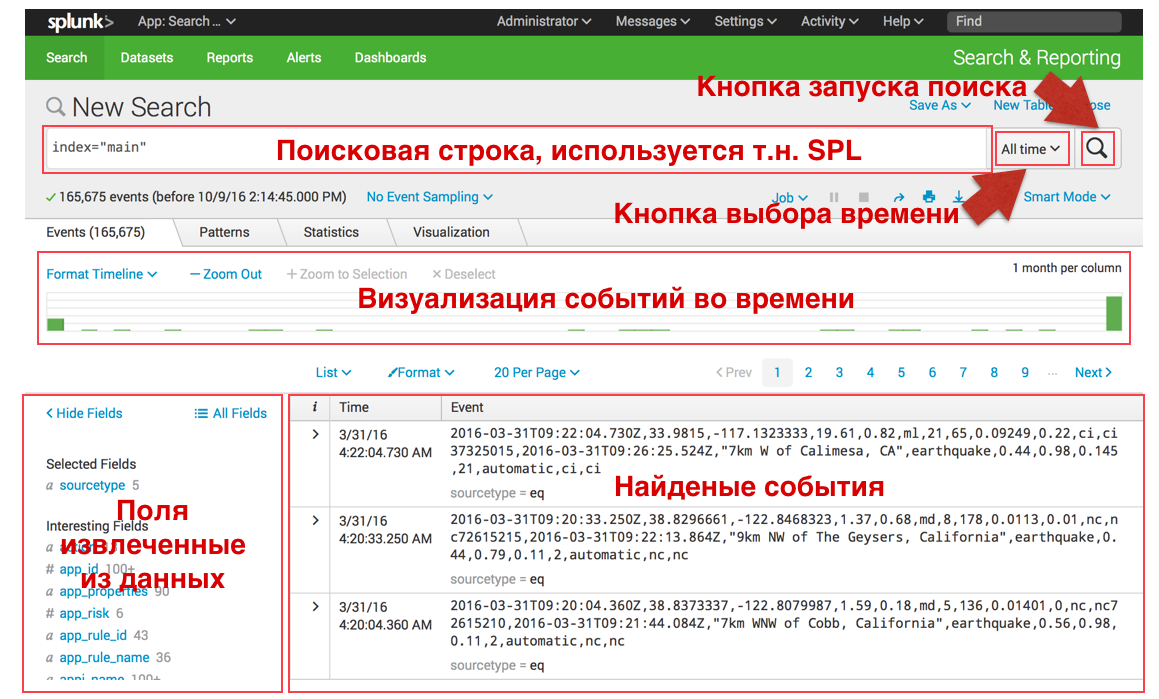
Поиск и фильтрация:
В Splunk можно «как в гугле» искать события по ключевому слову, или набору ключевых слов разделенных стандартными логическими операторами, примеры ниже. Также вы можете в любой момент актуализировать свой поиск, выбрав нужный вам временной интервал как в меню справа, так и центральной зеленой гистограмме, которая показывает количество событий в определенный период времени.
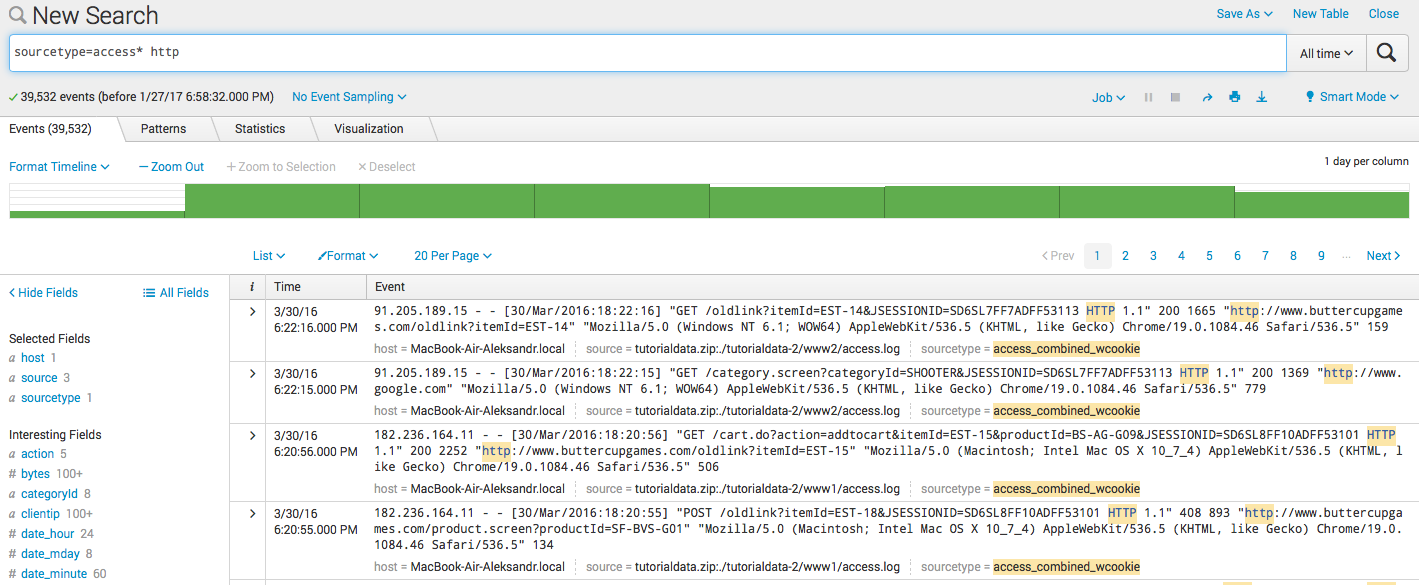
- Поиск по ключевому слову:
sourcetype=access* http
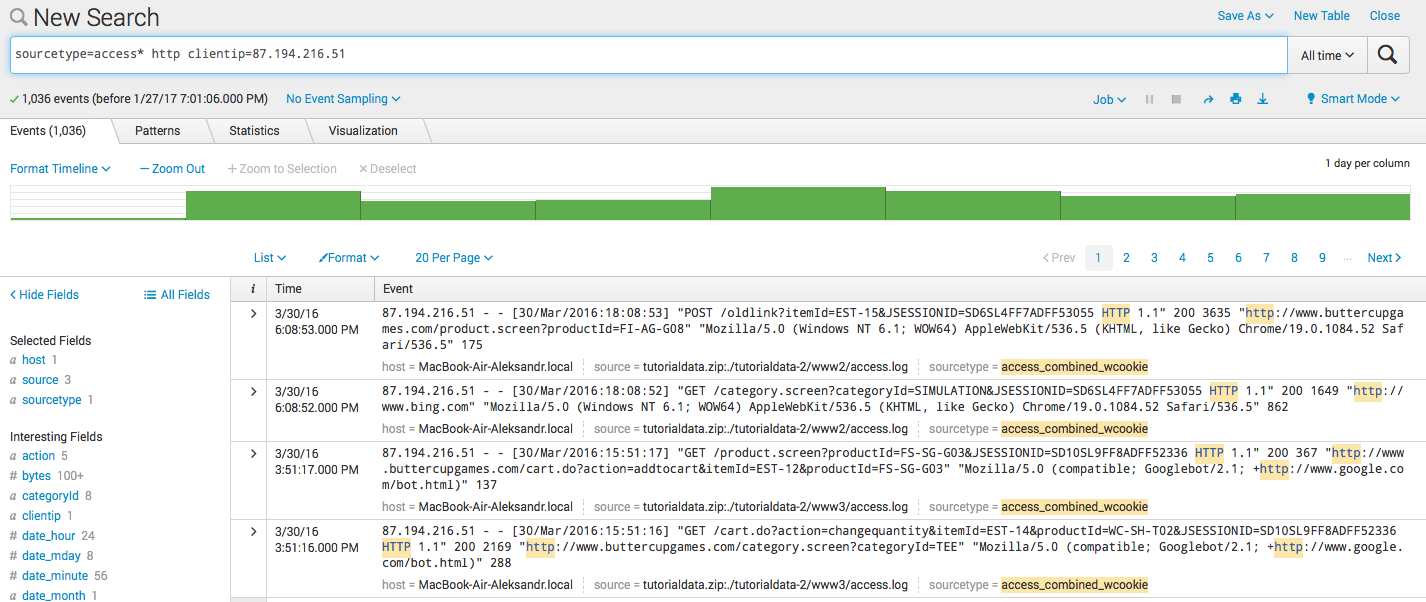
- Фильтрация:
sourcetype=access* http clientip=87.194.216.51
- Комбинация:
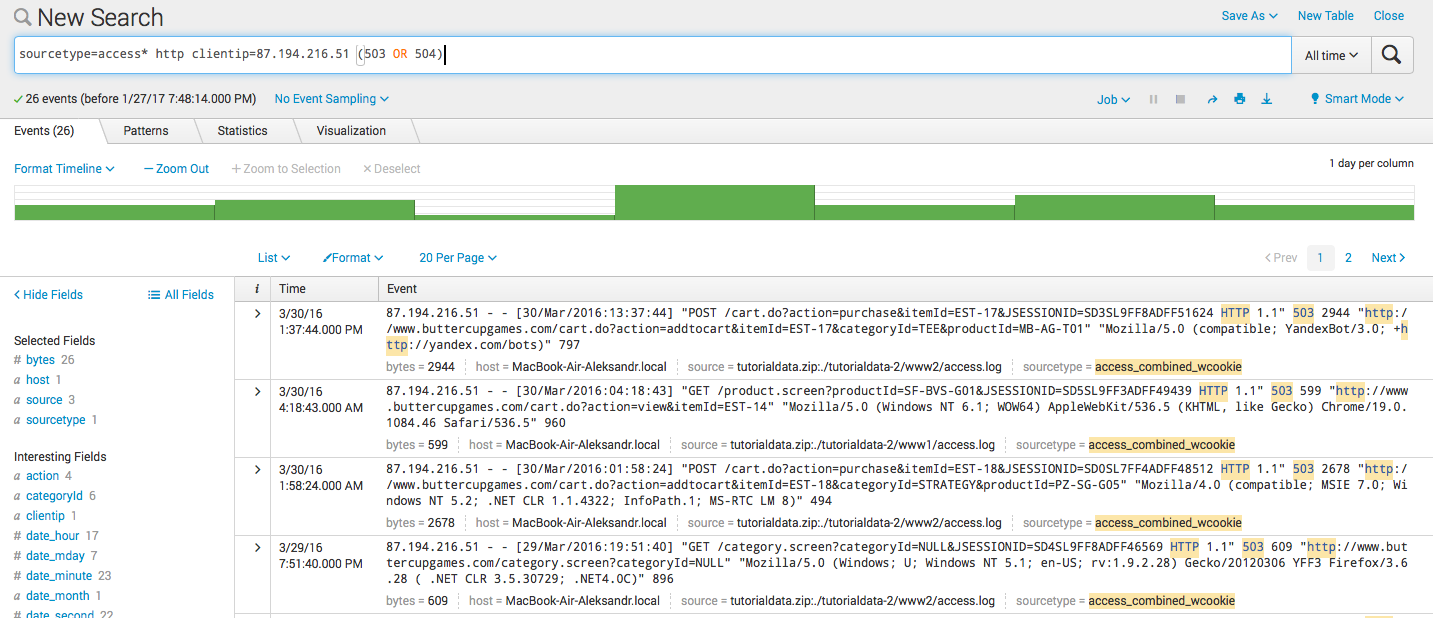
sourcetype=access* http clientip=87.194.216.51 (503 OR 504)
Вычисляемые поля (Eval):
Splunk может создавать новые поля на основе уже существующих, для этого используется команда eval, синтаксис и пример использования которой описан ниже. После того как мы создали какое-то поле, оно также может участвовать в дальнейших запросах.
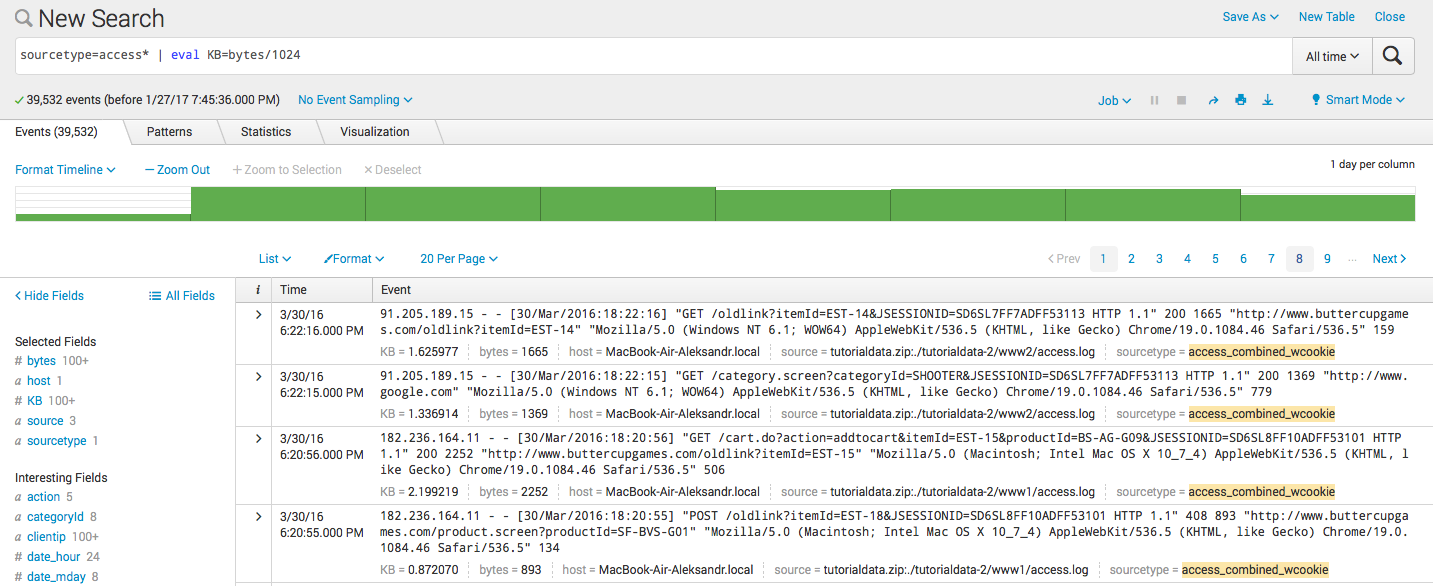
- Вычисление нового поля:
sourcetype=access* | eval KB=bytes/1024
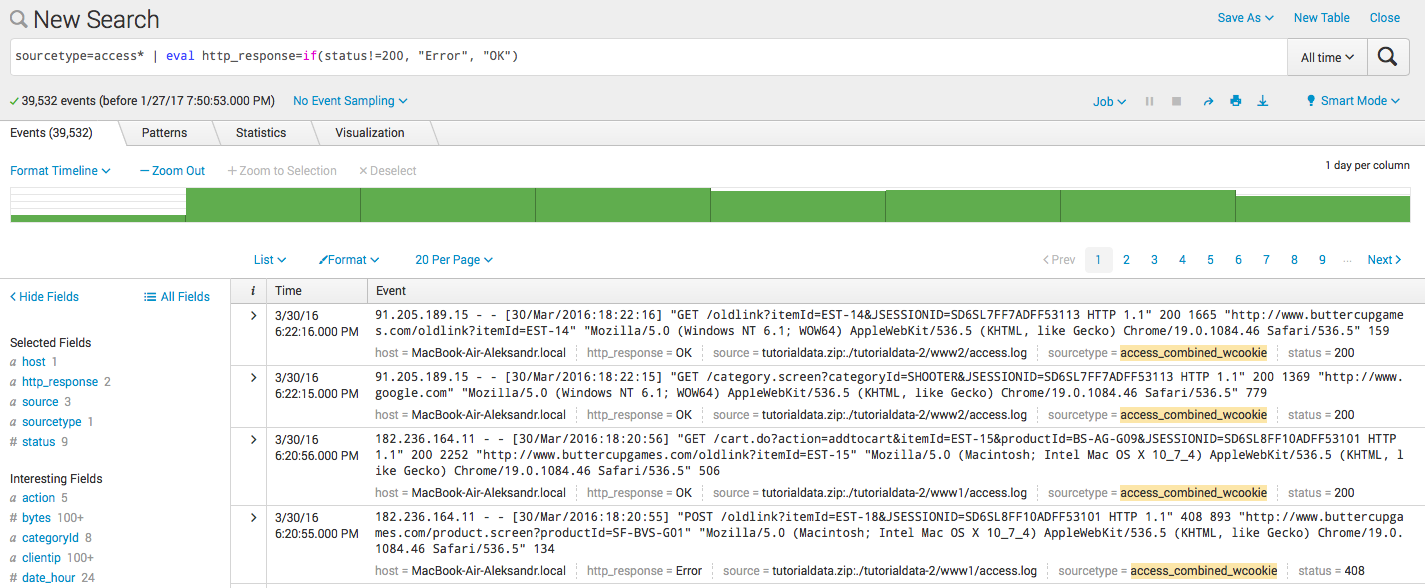
- Создание нового поля по условию:
sourcetype=access* | eval http_response=if(status!=200, "Error", "OK")
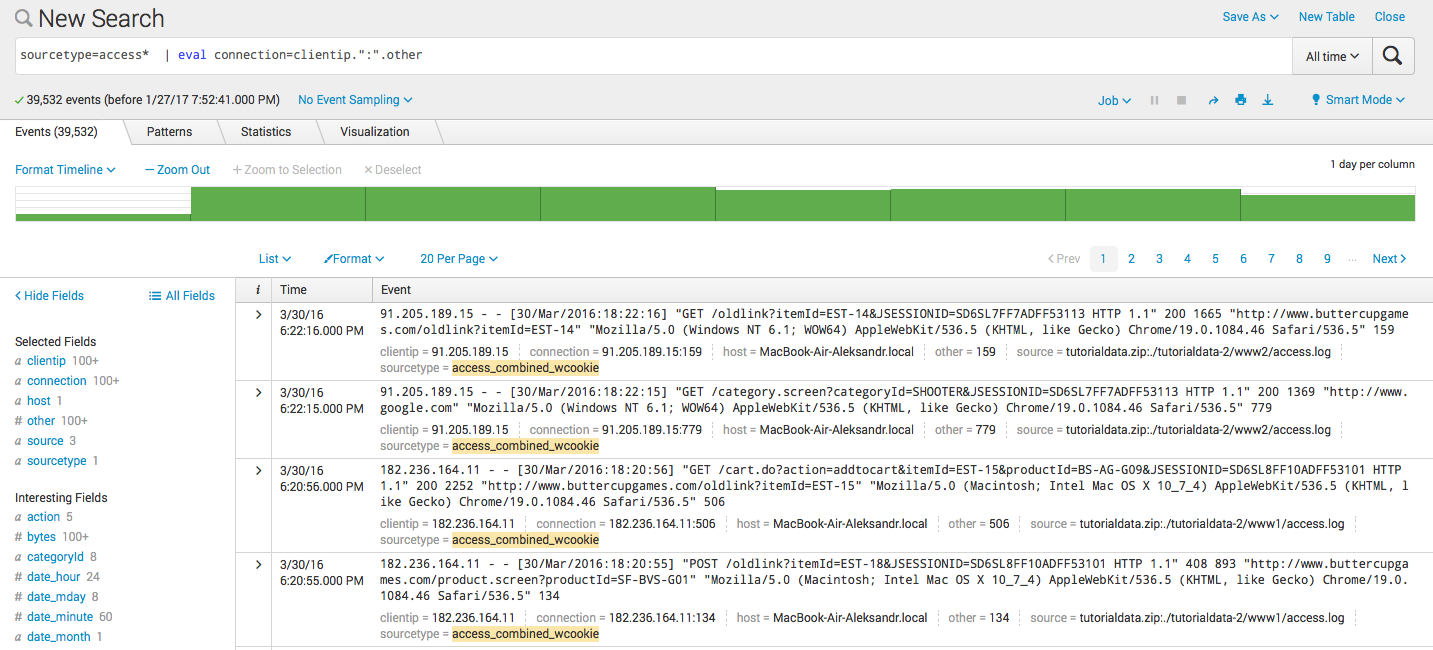
- Сцепление двух полей в новом:
sourcetype=access* | eval connection=clientip.":".other
Статистические запросы и визуализация:
После того как мы научились фильтровать и создавать новые поля переходим к следующему этапу — статистические запросы или агрегирование данных. Плюс все это естественно можно визуализировать. Для этих запросов вам потребуется загрузить в систему другой тестовый файл. Важно, на этапе загрузки поменять sourcetype csv на eq c помощью кнопки Save As, чтобы результаты запросов совпадали с нашими скриншотами.

- Вычисление:
sourcetype="eq" | stats avg(mag) AS "Средняя Магнитуда"
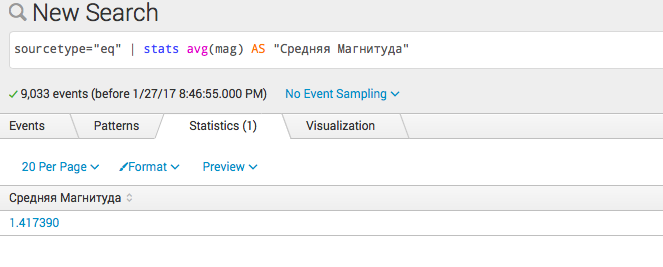
- Несколько вычислений:
sourcetype="eq" | stats avg(mag) AS "Средняя Магнитуда", sparkline(avg(mag)) AS "Тренд"
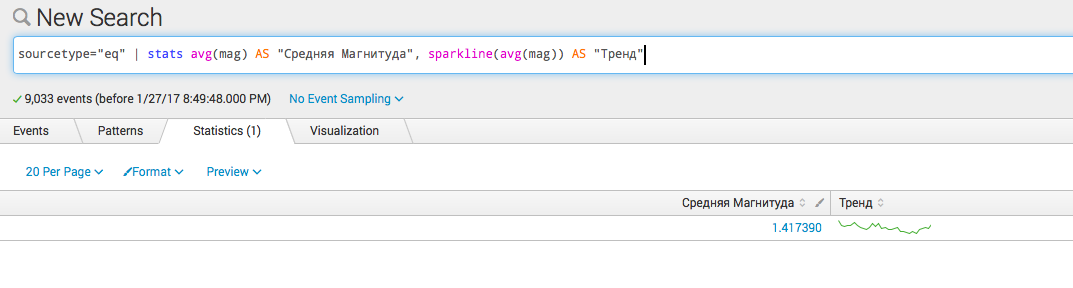
- Сгруппируем по полю type
sourcetype="eq" | stats avg(mag) AS "Средняя Магнитуда", sparkline(avg(mag)) AS "Тренд" by type
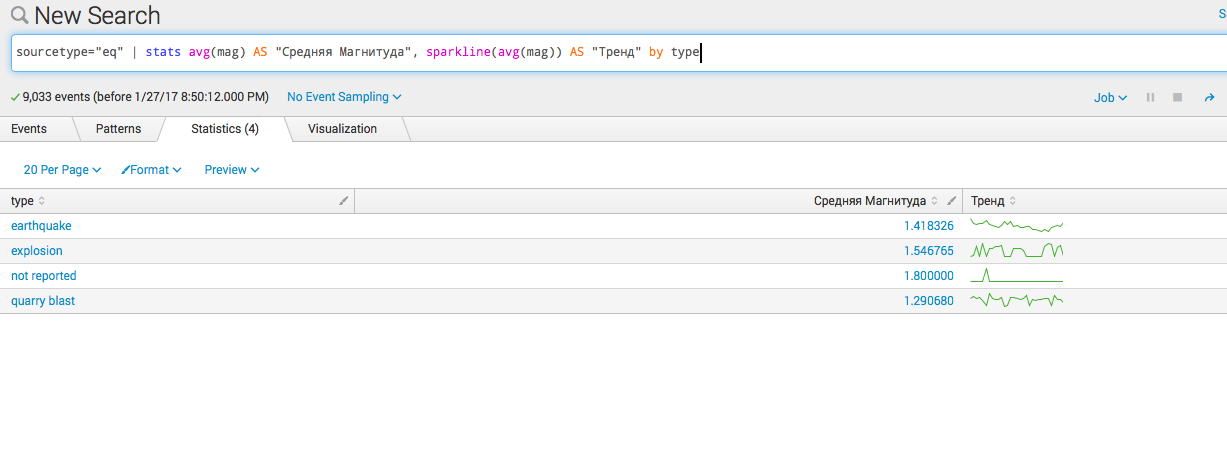
Статистические запросы во времени:
Так как Splunk осуществляет все поиски во времени, то одно из самых распространенных команд является timechart, которая позволяет строить статистические запросы с привязкой ко времени, ниже примеры (тип визуализации можно выбрать в интерфейсе под закладками statistics, visualization и рядом с кнопкой format):
- Визуализация простой статистики по времени:
sourcetype="eq" | timechart avg(mag) as "Средняя магнитуда"
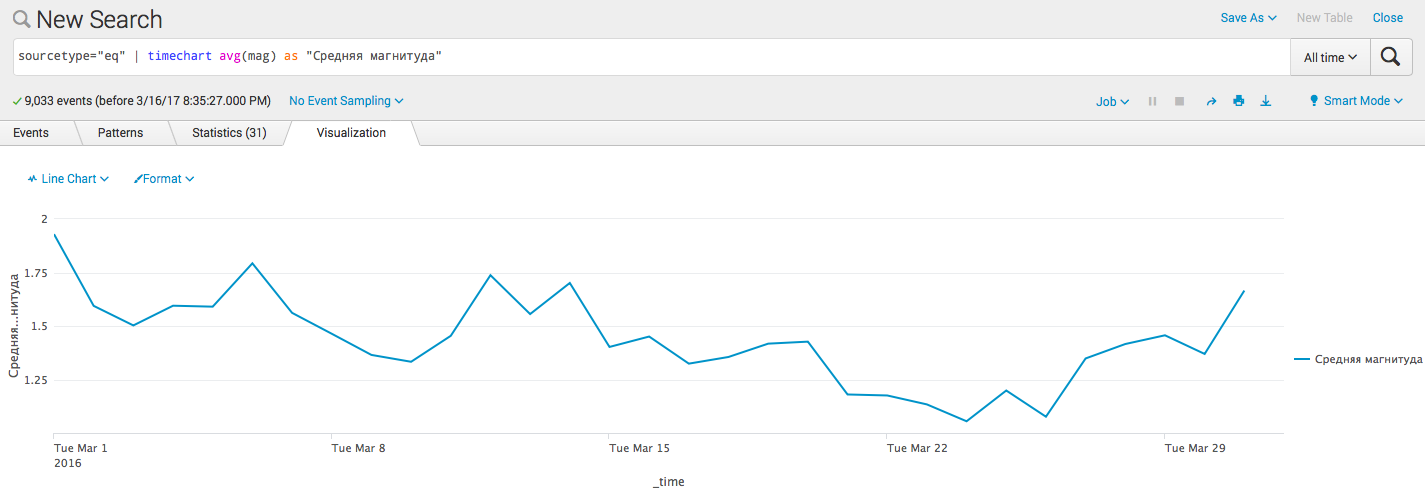
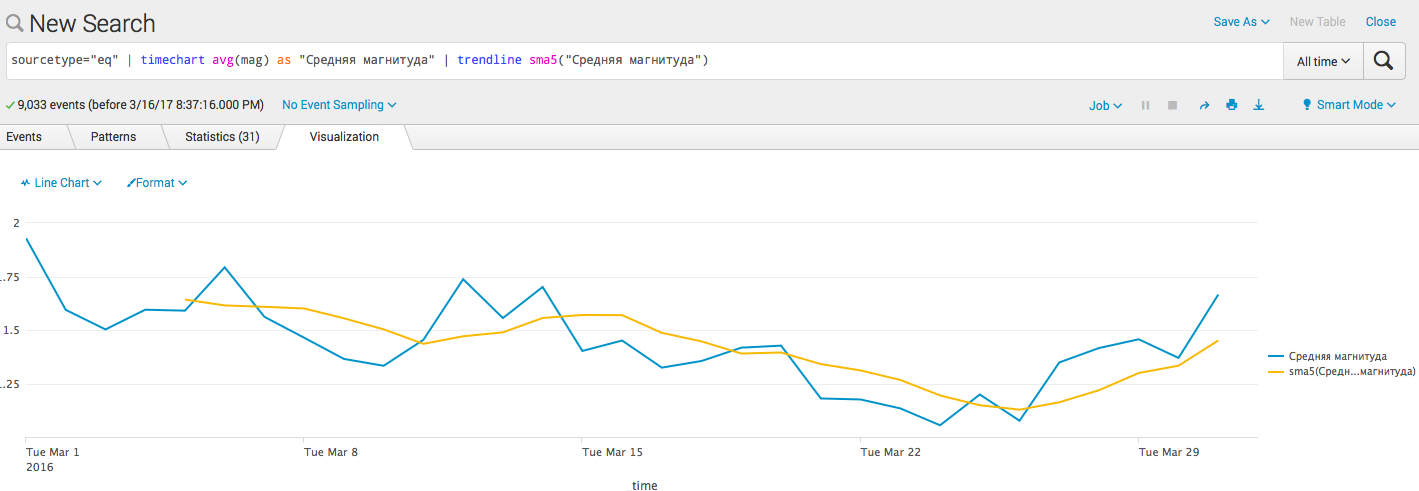
- Добавим линию тренда(алгоритм):
sourcetype="eq" | timechart avg(mag) as "Средняя магнитуда" | trendline sma5("Средняя магнитуда")
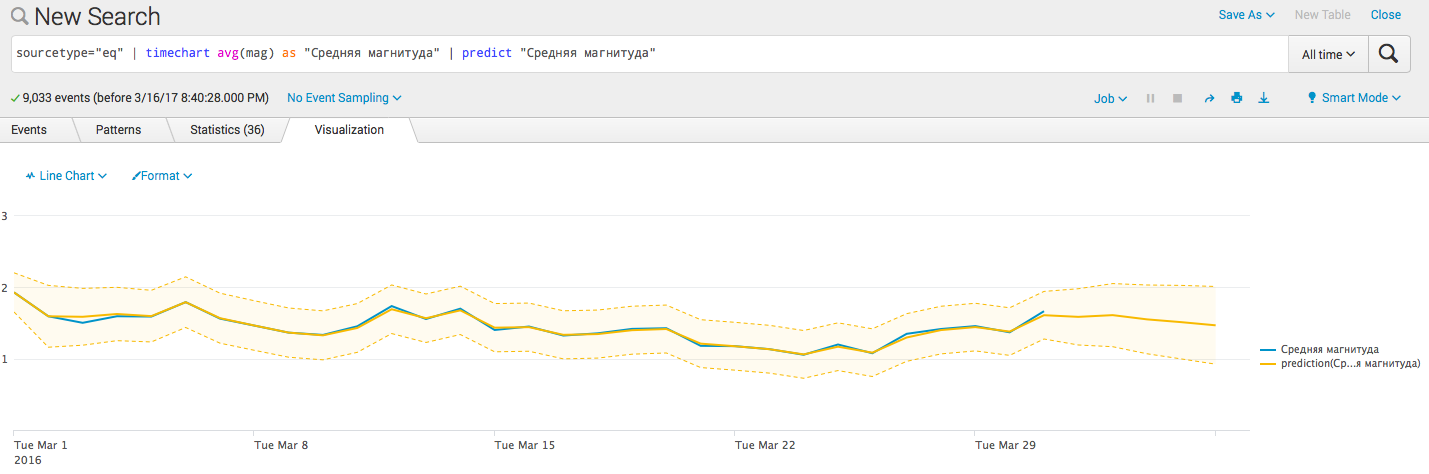
- Добавим прогнозные барьеры:
sourcetype="eq" | timechart avg(mag) as "Средняя магнитуда" | predict "Средняя магнитуда"
Заключение
В следующий раз мы расскажем про несколько интересных команд которые позволяют работать с данными в которых есть географические координаты и про то, как и откуда взять эти координаты если их нет, а также про группировки данных для выделения транзакций и выявления очередности событий.
Также хочу отметить супер полезный документ, содержащий в одном месте множество информации о Splunk — Quick Reference Guide.

