Джефф Этвуд, возможно, самый читаемый программист-блоггер, опубликовал пост против использования памяти ECC. Как я понимаю, его доводы такие:
Давайте рассмотрим эти аргументы один за другим:
Если вы делаете нечто только из-за того, что когда-то это сделал Google, то попробуйте:
Сегодня все ещё пишут статьи о том, что это — отличная идея, хотя Google всего лишь провёл эксперимент, который был расценен как неудачный. Оказывается, даже эксперименты Google не всегда удаются. Фактически, их известное пристрастие к «прорывным проектам» («луншоты») означает, что у них имеется больше неудачных экспериментов, чем у большинства компаний. По-моему, для них это существенное конкурентное преимущество. Не стоит делать это преимущество больше, чем оно есть, слепо копируя провалившиеся эксперименты.
Часть поста Этвуда обсуждает, насколько удивительными были эти серверы:
Некоторые могут взглянуть на эти ранние серверы Google и увидеть непрофессионализм в отношении опасности пожара. Не я. Я вижу здесь дальновидное понимание того, как недорогое стандартное оборудование будет формировать современный интернет.
Последняя часть высказанного — это правда. Но и в первой части есть доля правды. Когда Google начал разрабатывать свои собственные платы, одно их поколение имело проблему «роста» (1), вызвавшую ненулевое число возгораний.
Кстати, если вы перейдёте к посту Джеффа и посмотрите на фотографию, на которую ссылается цитата, то вы увидите, что на платах много кабелей-перемычек. Это вызывало проблемы и было исправлено в следующем поколении оборудования. Также можно видеть довольно неряшливо выполненную кабельную разводку, что дополнительно вызывало проблемы и что также было быстро устранено. Были и другие проблемы, но я оставлю их в качестве упражнения для читателя.
Острые грани одного из поколений серверов Google заработали им репутацию сделанных из «бритвенных лезвий и ненависти».
После разговоров с сотрудниками многих крупных технологических компаний создаётся впечатление, что в большинстве компаний был такой климат-контроль, что в их центрах обработки данных образовывались облака или туман. Можно было бы назвать это расчётливым и коварным планом Google по воспроизведению сиэтловской погоды, чтобы переманивать сотрудников Microsoft. Как вариант, это мог быть план создания в буквальном смысле «облачных вычислений». А может и нет.
Обратите внимание, что всё указанное Google попробовал, а затем изменил. Делать ошибки, а затем устранять их — распространённое явление в любой организации, успешно занимающейся разработками. Если вы боготворите инженерную практику, то следует держаться, по крайней мере, за современную практику, а не за сделанное в 1999 году.
Когда Google использовал серверы без ECC в 1999 году, на них проявился ряд симптомов, которые, как в конце концов выяснилось, были вызваны повреждением памяти. В том числе индекс поиска, который возвращал фактически случайные результаты в запросы. Реальный режим сбоя здесь поучителен. Я часто слышу, что на этих машинах можно игнорировать ECC, потому что ошибки в отдельных результатах являются допустимыми. Но даже если вы считаете для себя случайные ошибки допустимыми, их игнорирование означает, что существует опасность полного повреждения данных, если только не проводить тщательный анализ с целью убедиться, что одна ошибка может лишь незначительно исказить один результат.
В исследованиях, проведённых на файловых системах, неоднократно было показано, что, несмотря на героические попытки создания систем, устойчивых к одной ошибке, сделать это крайне сложно. По существу, каждая сильно тестируемая файловая система может иметь серьёзный сбой из-за единственной ошибки (см. результаты работы исследовательской группы Андреа и Ремзи, Висконсин, если вам интересно это). Я не собираюсь нападать на разработчиков файловых систем. Они лучше разбираются в таком анализе, чем 99,9% программистов. Просто неоднократно уже было показано, что эта проблема настолько трудная, что люди не могут достаточно обоснованно обсуждать её, и автоматизированное инструментальное средство для такого анализа ещё далеко от процесса простого нажатия кнопки. В своём справочнике по компьютерной обработке складских данных Google обсуждает обнаружение и исправление ошибок, и память ECC рассматривается как самый правильный вариант, когда очевидно, что необходимо использовать исправление ошибок аппаратного обеспечения (2).
Google имеет отличную инфраструктуру. Из того, что я слышал об инфраструктуре в других крупных инфотехнологических компаниях, Google представляется лучшим в мире. Но это не значит, что следует копировать всё, что они делают. Даже если рассматривать только их хорошие идеи, для большинства компаний нет смысла копировать их. Они создали замену планировщику перехвата работ Linux, который использует как аппаратную информацию времени выполнения, так и статические трассировки, чтобы позволить им использовать преимущества нового оборудования в серверных процессорах Intel, что позволяет динамически разбивать кэш между ядрами. Если использовать это на всём их оборудовании, то Google сэкономит за неделю больше денег, чем компания Stack Exchange потратила на все свои машины за всю свою историю. Означает ли это, что вы должны скопировать Google? Нет, если на вас уже не свалилась манна небесная, например, в виде того, что ваша основная инфраструктура написана на высокооптимизированном C++, а не на Java или (не дай бог) Ruby. И дело в том, что для подавляющего большинства компаний написание программ на языке, который влечёт 20-кратное снижение производительности, — совершенно разумное решение.
Аргументация против ECC воспроизводит следующий раздел исследования ошибок DRAM (выделение дано Джеффом):
Цитата кажется несколько ироничной, поскольку она выглядит не аргументом против ECC, а аргументом за Chipkill — определённый класс ECC. Отложив это в сторону, пост Джеффа указывает, что систематические ошибки встречаются в два раза чаще, чем ошибки случайные. Затем пост сообщает, что они запускают memtest на своих машинах, когда происходят систематические ошибки.
Во-первых, соотношение 2:1 не столь велико, чтобы просто игнорировать случайные ошибки. Во-вторых, пост подразумевает веру Джеффа, что систематические ошибки, по существу, неизменны и не могут проявиться через некоторое время. Это неверно. Электроника изнашивается точно так же, как изнашиваются механические устройства. Механизмы разные, но эффекты схожи. Действительно, если сравнить анализ надёжности чипов с другими видами анализа надёжности, то можно видеть, что они часто используют одни и те же семейства распределений для моделирования отказов. В-третьих, ход рассуждений Джеффа подразумевает, что ECC не может помочь в обнаружении или исправлении ошибок, что не только неверно, но и прямо противоречит цитате.
Итак, как часто вы собираетесь запускать memtest на своих машинах в попытках поймать эти системные ошибки и сколько потерь данных вы готовы пережить? Одно из ключевых применений ECC состоит не в том, чтобы исправить ошибки, а в том, чтобы сигнализировать об ошибках, благодаря чему оборудование может быть заменено до того, как произойдёт «silent corruption» («скрытое повреждение данных»). Кто согласится закрывать всё на машине каждый день, чтобы запустить memtest? Это было бы намного дороже, чем просто купить ECC-память. И даже если бы вы смогли убедить гонять тестирование памяти, memtest не обнаружил бы столько ошибок, сколько сможет найти ECC.
Когда я работал в компании с парком в примерно тысячу машин, мы заметили, что у нас происходят странные отказы при проверке целостности данных, и примерно через полгода мы поняли, что отказы на одних машинах более вероятны, чем на других. Эти отказы были довольно редкими (может быть, пару раз в неделю в среднем), поэтому потребовалось много времени для накопления информации и понимания, что же происходит. Без знания причины анализ логов с целью понять, что ошибки были вызваны единичными случаями инвертирования битов (с большой вероятностью), также был нетривиальным. Нам повезло, что в качестве побочного эффекта процесса, который мы использовали, контрольные суммы вычислялись в отдельном процессе на другой машине в разное время, так что ошибка не могла исказить результат и распространить это повреждение на контрольную сумму.
Если вы просто пытаетесь защитить себя с помощью контрольных сумм в памяти, есть немалая вероятность того, что вы выполните операцию вычисления контрольной суммы на уже повреждённых данных и получите правильную контрольную сумму неправильных данных, если только вы не делаете некоторые действительно необычные операции с вычислениями, которые дают их собственные контрольные суммы. А если вы серьёзно относитесь к исправлению ошибок, то вы, вероятно, всё же используете ECC.
Во всяком случае, после завершения анализа мы обнаружили, что memtest не мог обнаружить какие-либо проблемы, но замена ОЗУ на плохих машинах привела к уменьшению частоты ошибок на один-два порядка. У большинства сервисов нет такого рода контрольных сумм, которые были у нас; эти сервисы будут просто молча записывать повреждённые данные в постоянное хранилище и не увидят проблему, пока клиент не начнёт жаловаться.
Данных в посте недостаточно для такого утверждения. Обратите внимание, что поскольку использование ОЗУ возрастает и продолжает увеличиваться экспоненциально, отказы ОЗУ должны уменьшаться с большей экспоненциальной скоростью, чтобы фактически уменьшить частоту повреждения данных. Кроме того, поскольку чипы продолжают уменьшаться, элементы становятся меньше, что делает более актуальными проблемы износа, обсуждаемые во втором пункте. Например, при технологии 20 нм конденсатор DRAM может накпливать где-то электронов 50, и это число будет меньше для следующего поколения DRAM при сохранении тенденции уменьшения.
Исследование 2012 года, которое цитирует Этвуд, имеет этот график по исправленным ошибкам (подмножество всех ошибок) на десяти случайно выбранных отказавших узлах (6% узлов имели по крайней мере один отказ):
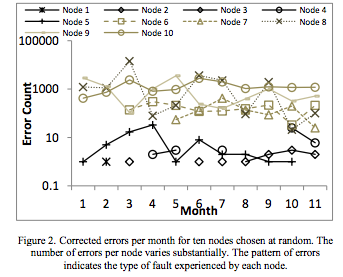
Рис. 1. Исправленные за месяц ошибки для выбранных случайным образом узлов. Количество ошибок показывает тип сбоя, возникший в каждом узле.
Речь идёт о количестве ошибок от 10 до 10 тыс. для типичного узла, у которого происходит отказ, и это — тщательно отобранное исследование с поста, утверждающего, что вам не нужна память ECC. Обратите внимание, что здесь рассматриваются узлы с ОЗУ только 16 ГБ, что на порядок меньше, чем у современных серверов, и что исследование было проведено на более старом техпроцессе, который был менее уязвим для шума, чем нынешний.
Для тех, кто привык иметь дело с проблемами надёжности и просто хочет знать значение FIT (единица измерения интенсивности отказов): исследование показывает, что значение FIT составляет 0,057-0,071 сбоев на один мегабит (что — в противоположность утверждению Этвуда — не является поразительно низким числом).
Если взять самое оптимистичное значение FIT, равное 0,057, и провести расчёт для сервера не с самой большой оперативной памятью (здесь я использую 128 ГБ, поскольку серверы, которые я вижу в настоящее время, обычно имеют ОЗУ от 128 до 1,5 ТБ), то получим ожидаемое значение 0,057 * 1 000 * 1 000 * 8 760 /1 000 000 000 = 0,5 сбоя в год на каждый сервер. Обратите внимание, что это относится к сбоям, а не к ошибкам. Из графика выше видно, что сбой может легко вызвать сотни или тысячи ошибок в месяц. Ещё нужно отметить, что есть несколько узлов, у которых нет ошибок в начале исследования, но ошибки появляются позже.
Компания Sun/Oracle серьёзно столкнулась с этим несколько десятилетий назад. Транзисторы и конденсаторы DRAM становились всё меньше, как это происходит и сейчас, а использование памяти и кэши росли, так же как и в настоящее время. Столкнувшись, с одной стороны, со всё уменьшающимся транзистором, который был менее стойким к временному нарушению и более сложным в изготовлении, а, с другой стороны, с растущим встроенным кэшем, подавляющее большинство поставщиков серверов ввело ECC в свои кэши. Компания Sun решила сэкономить несколько долларов и не использовать ECC. Прямым результатом было то, что ряд клиентов Sun сообщил о периодических повреждении данных. В результате затем Sun несколько лет занималась разработкой новой архитектуры с кэшем на ECC и заставляла клиентов подписывать NDA для замены чипов.
Конечно, невозможно постоянно скрывать подобные вещи, и когда они всплыли, репутация Sun по созданию надёжных серверов получила сильный удар, во многом похожий на случай, когда Sun пыталась скрыть плохие показатели производительности, введя в свои условия использования запрет на бенчмарки.
Ещё одно замечание: когда вы платите за ECC, вы платите не просто за память ECC — вы платите за детали (процессоры, платы), которые являются более качественными. Такое легко можно видеть с частотой отказа дисков, и я слышал, что многие замечают такое в своих личных наблюдениях.
Если приводить общедоступные исследования: насколько помню, группа Андреа и Ремзи несколько лет назад выпустила документ SIGMETRICS, который показал, что вероятность сбоя при чтении у диска SATA в 4 раза выше, чем у диска SCSI, а вероятность скрытого повреждения данных — в 10 раз выше. Это соотношение сохранялось даже при использовании дисков одного изготовителя. Нет особой причины думать, что интерфейс SCSI должен быть более надёжным, чем интерфейс SATA, но речь идёт не об интерфейсе. Речь идёт о покупке высоконадёжных серверных компонентов по сравнению с клиентскими. Возможно, конкретно надёжность диска вас не интересует, потому что у вас всё на контрольных суммах, и повреждения легко находятся, но есть некоторые виды нарушений, которые обнаружить труднее.
Немного перефразируя этот аргумент, можно сказать, что «если бы эта характеристика была, действительно, важна для серверов, то она использовалась бы и в не-серверах». Можно применить этот аргумент к довольно большому количеству аппаратных средств сервера. На самом деле это одна из наиболее неприятных проблем, стоящих перед крупными поставщиками облачных решений.
У них достаточно рычагов воздействия, чтобы получать большинство компонентов по подходящей цене. Но поторговаться получится только там, где есть более одного жизнеспособного поставщика.
Одной из немногих областей, где нет каких-либо жизнеспособных конкурентов, является производство центральных процессоров и видеоускорителей. К счастью для крупных поставщиков, видеоускорители им обычно не нужны, нужны процессоры, много — уже давно так сложилось. Было несколько попыток поставщиков процессоров войти на серверный рынок, но всегда каждая такая попытка с самого начала имела фатальные недостатки, делавшие очевидной её обречённость (а это часто проекты, требующие не менее 5 лет, т.е. необходимо было потратить очень много времени без уверенности в успехе).
Усилия Qualcomm получили много шума, но, когда я общаюсь с моими контактами в Qualcomm, они все говорят мне, что сделанный в данный момент чип предназначен, по существу, для пробы. Так получилось, потому что компании Qualcomm нужно было узнать, как сделать серверный чип, у всех тех специалистов, которых она переманила из IBM, и что следующий чип будет первым, который, можно надеяться, станет конкурентоспособным. Я возлагаю большие надежды на Qualcomm, а также на усилия ARM по созданию хороших серверных компонентов, но эти усилия пока не дают желаемого результата.
Почти полная непригодность текущих вариантов ARM (и POWER) (не считая гипотетических вариантов впечатляющего чипа ARM от Apple) для большинства рабочих нагрузок серверов с точки зрения производительности на доллар совокупной стоимости владения (TCO) — эта тема немного в стороне, поэтому я оставлю её для другой публикации. Но дело в том, что Intel имеет такую позицию на рынке, что может заставить людей платить сверху за серверные функции. И Intel это делает. Кроме того, некоторые функции действительно важнее для серверов, чем для мобильных устройств с несколькими гигабайтами оперативной памяти и энергетическим бюджетом в несколько ватт, мобильных устройств, от которых всё равно ожидают периодические вылеты и перезагрузки.
Следует ли покупать ECC-ОЗУ? Это зависит от многого. Для серверов это, вероятно, хороший вариант, учитывая затраты. Хотя на самом деле трудно провести анализ затрат/выгод, потому что довольно сложно определить ущерб от скрытого повреждения данных или затраты на риск потерять полгода времени разработчика на отслеживание перемежающихся сбоев, только чтобы обнаружить, что они вызваны использованием памяти без ECC.
Для настольных компьютеров я тоже сторонник ECC. Но если вы не делаете регулярные бэкапы, то вам полезнее вложиться в регулярные бэкапы, чем в ECC-память. И если у вас есть резервные копии без ECC, то вы можете легко записать повреждённые данные в основное хранилище и реплицировать эти повреждённые данные в резервную копию.
Спасибо Прабхакару Рагде, Тому Мерфи, Джею Вайскопфу, Лии Хансон, Джо Уайлдеру и Ральфу Кордерою за обсуждение / комментарии / исправления. Кроме того, спасибо (или, может быть, не-спасибо) Лии за то, что убедила меня написать этот устный экспромт как пост в блоге. Приносим извинения за любые ошибки, отсутствие ссылок и возвышенную прозу; это, по существу, запись половины обсуждения, и я не объяснил условия, не предоставил ссылки или не проверил факты на том уровне детализации, как я обычно делаю.
1. Одним из забавных примеров является (по крайней мере, для меня) магическая самовосстанавливающаяся плавкая перемычка. Хотя реализаций много, представим себе плавкую перемычку на чипе как некоторый резистор. Если вы пропускаете через неё какой-то ток, то вы должны получить соединение. Если ток слишком большой, то резистор разогреется и, в конце концов, разрушится. Это обычно используется для отключения элементов на микросхемах или для таких действий, как задание тактовой частоты. Основной принцип состоит в том, что после сгорания перемычки нет возможности вернуть её в исходное состояние.
Давным давно жил да был производитель полупроводниковых устройств, который немного поторописля со своим производственным процессом и несколько чрезмерно уменьшил допуски в некотором технологическом поколении. Через несколько месяцев (или лет) соединение между двумя концами подобной перемычки смогло снова появиться и восстановить его. Если вам повезёт, то такая перемычка будет чем-то вроде старшего бита множителя тактовой частоты, который в случае его изменения будет выводить чип из строя. Если не повезёт, то это приведёт к скрытому повреждению данных.
Я слышал от многих людей в разных компаниях о проблемах в этом технологическом поколении этого производителя, так что это не были отдельные случаи. Когда я говорю, что это забавно, я имею в виду, что забавно услышать эту историю в баре. Менее забавно обнаружить через год тестирования, что некоторые из ваших чипов не работают, потому что их установки для перемычек бессмысленны, и необходимо переделать ваш чип и отложить выпуск на 3 месяца. Кстати, эта ситуация с восстановлением плавкой перемычки — ещё один пример класса ошибок, остроту которых можно сгладить с помощью ECC.
Это не проблема Google; я упоминаю об этом только потому, что многие люди, с которыми я общаюсь, удивлены тем, каким образом аппаратное обеспечение может выйти из строя.
2. Если вы не хотите копаться во всей книге, то вот нужный фрагмент:
В системе, которая может выдержать ряд отказов на программном уровне, минимальное требование, предъявляемое к аппаратной части, заключается в том, что сбои этой части всегда обнаруживаются и сообщаются программному обеспечению достаточно своевременно, чтобы позволить программной инфраструктуре ограничить их и принять соответствующие действия по восстановлению. Необязательно, чтобы аппаратное обеспечение явно справлялось со всеми сбоями. Это не означает, что оборудование для таких систем должно быть спроектировано без возможности исправления ошибок. Всякий раз, когда функциональные возможности исправления ошибок могут быть предложены с разумной ценой или сложностью, поддержка их часто окупается. Это означает, что, если аппаратная коррекция ошибок была бы чрезвычайно дорогостоящей, то система могла бы иметь возможность использования более дешёвой версии, которая предоставляла бы возможности только обнаружения. Современные системы DRAM являются хорошим примером ситуации, в которой мощная коррекция ошибок может быть предоставлена при очень низких дополнительных затратах. Однако смягчение требования об обнаружении аппаратных ошибок было бы намного сложнее, поскольку это означало бы, что каждый программный компонент был бы обременён необходимостью проверки его собственного правильного выполнения. На начальном этапе своей истории Google пришлось иметь дело с серверами, на которых у DRAM отсутствовал даже контроль чётности. Создание индекса веб-поиска состоит, по существу, из очень большой операции сортировки/слияния, использующей длительно несколько машин. В 2000 году одно из ежемесячных обновлений веб-индекса Google не прошло предварительную проверку, когда обнаружилось, что некоторое подмножество проверенных запросов возвращает документы, по-видимому, случайным образом. После некоторого исследования в новых индексных файлах была выявлена ситуация, которая соответствовала фиксации бита на нуле в определённом месте в структурах данных, что было негативным побочным эффектом потоковой передачи большого количества данных через неисправный чип DRAM. В структуры данных индекса были добавлены проверки непротиворечивости, чтобы свести к минимуму вероятность повторения этой проблемы, и в дальнейшем проблем такого характера не было. Однако следует отметить, что этот способ не гарантирует 100% обнаружения ошибок в проходе индексации, так как не все позиции памяти проверяются — инструкции, например, остаются без проверки. Это сработало потому, что структуры данных индекса были настолько больше, чем все другие данные, участвующие в вычислении, что наличие этих самоконтролируемых структур данных делало очень вероятным, что машины с дефектным DRAM будут идентифицированы и исключены из кластера. Следующее поколение машин в Google уже содержало обнаружение чётности в памяти, и как только цена памяти с ECC опустилась до конкурентного уровня, все последующие поколения использовали ECC-DRAM.
- В Google не использовали ECC, когда собирали свои серверы в 1999 году.
- Большинство ошибок ОЗУ — это ошибки систематические, а не случайные.
- Ошибки ОЗУ возникают редко, потому что аппаратное обеспечение улучшилось.
- Если бы память ECC имела на самом деле важное значение, то она использовались бы везде, а не только в серверах. Плата за такого рода опциональный материал явно слишком сомнительна.
Давайте рассмотрим эти аргументы один за другим:
1. В Google не использовали ECC в 1999 году
Если вы делаете нечто только из-за того, что когда-то это сделал Google, то попробуйте:
A. Поместите свои серверы в транспортные контейнеры.
Сегодня все ещё пишут статьи о том, что это — отличная идея, хотя Google всего лишь провёл эксперимент, который был расценен как неудачный. Оказывается, даже эксперименты Google не всегда удаются. Фактически, их известное пристрастие к «прорывным проектам» («луншоты») означает, что у них имеется больше неудачных экспериментов, чем у большинства компаний. По-моему, для них это существенное конкурентное преимущество. Не стоит делать это преимущество больше, чем оно есть, слепо копируя провалившиеся эксперименты.
B. Вызывайте пожары в своих собственных центрах обработки данных.
Часть поста Этвуда обсуждает, насколько удивительными были эти серверы:
Некоторые могут взглянуть на эти ранние серверы Google и увидеть непрофессионализм в отношении опасности пожара. Не я. Я вижу здесь дальновидное понимание того, как недорогое стандартное оборудование будет формировать современный интернет.
Последняя часть высказанного — это правда. Но и в первой части есть доля правды. Когда Google начал разрабатывать свои собственные платы, одно их поколение имело проблему «роста» (1), вызвавшую ненулевое число возгораний.
Кстати, если вы перейдёте к посту Джеффа и посмотрите на фотографию, на которую ссылается цитата, то вы увидите, что на платах много кабелей-перемычек. Это вызывало проблемы и было исправлено в следующем поколении оборудования. Также можно видеть довольно неряшливо выполненную кабельную разводку, что дополнительно вызывало проблемы и что также было быстро устранено. Были и другие проблемы, но я оставлю их в качестве упражнения для читателя.
C. Создавайте серверы, которые травмируют ваших сотрудников
Острые грани одного из поколений серверов Google заработали им репутацию сделанных из «бритвенных лезвий и ненависти».
D. Создавайте свою погоду в ваших центрах обработки данных
После разговоров с сотрудниками многих крупных технологических компаний создаётся впечатление, что в большинстве компаний был такой климат-контроль, что в их центрах обработки данных образовывались облака или туман. Можно было бы назвать это расчётливым и коварным планом Google по воспроизведению сиэтловской погоды, чтобы переманивать сотрудников Microsoft. Как вариант, это мог быть план создания в буквальном смысле «облачных вычислений». А может и нет.
Обратите внимание, что всё указанное Google попробовал, а затем изменил. Делать ошибки, а затем устранять их — распространённое явление в любой организации, успешно занимающейся разработками. Если вы боготворите инженерную практику, то следует держаться, по крайней мере, за современную практику, а не за сделанное в 1999 году.
Когда Google использовал серверы без ECC в 1999 году, на них проявился ряд симптомов, которые, как в конце концов выяснилось, были вызваны повреждением памяти. В том числе индекс поиска, который возвращал фактически случайные результаты в запросы. Реальный режим сбоя здесь поучителен. Я часто слышу, что на этих машинах можно игнорировать ECC, потому что ошибки в отдельных результатах являются допустимыми. Но даже если вы считаете для себя случайные ошибки допустимыми, их игнорирование означает, что существует опасность полного повреждения данных, если только не проводить тщательный анализ с целью убедиться, что одна ошибка может лишь незначительно исказить один результат.
В исследованиях, проведённых на файловых системах, неоднократно было показано, что, несмотря на героические попытки создания систем, устойчивых к одной ошибке, сделать это крайне сложно. По существу, каждая сильно тестируемая файловая система может иметь серьёзный сбой из-за единственной ошибки (см. результаты работы исследовательской группы Андреа и Ремзи, Висконсин, если вам интересно это). Я не собираюсь нападать на разработчиков файловых систем. Они лучше разбираются в таком анализе, чем 99,9% программистов. Просто неоднократно уже было показано, что эта проблема настолько трудная, что люди не могут достаточно обоснованно обсуждать её, и автоматизированное инструментальное средство для такого анализа ещё далеко от процесса простого нажатия кнопки. В своём справочнике по компьютерной обработке складских данных Google обсуждает обнаружение и исправление ошибок, и память ECC рассматривается как самый правильный вариант, когда очевидно, что необходимо использовать исправление ошибок аппаратного обеспечения (2).
Google имеет отличную инфраструктуру. Из того, что я слышал об инфраструктуре в других крупных инфотехнологических компаниях, Google представляется лучшим в мире. Но это не значит, что следует копировать всё, что они делают. Даже если рассматривать только их хорошие идеи, для большинства компаний нет смысла копировать их. Они создали замену планировщику перехвата работ Linux, который использует как аппаратную информацию времени выполнения, так и статические трассировки, чтобы позволить им использовать преимущества нового оборудования в серверных процессорах Intel, что позволяет динамически разбивать кэш между ядрами. Если использовать это на всём их оборудовании, то Google сэкономит за неделю больше денег, чем компания Stack Exchange потратила на все свои машины за всю свою историю. Означает ли это, что вы должны скопировать Google? Нет, если на вас уже не свалилась манна небесная, например, в виде того, что ваша основная инфраструктура написана на высокооптимизированном C++, а не на Java или (не дай бог) Ruby. И дело в том, что для подавляющего большинства компаний написание программ на языке, который влечёт 20-кратное снижение производительности, — совершенно разумное решение.
2. Большинство ошибок ОЗУ — это систематические ошибки
Аргументация против ECC воспроизводит следующий раздел исследования ошибок DRAM (выделение дано Джеффом):
Наше исследование имеет несколько основных результатов. Во-первых, мы обнаружили, что приблизительно 70% сбоев DRAM является повторяющимися (например, постоянными) сбоями, тогда как только 30% является неустойчивыми (перемежающимися) сбоями. Во-вторых, мы обнаружили, что большие многобитовые сбои, такие как сбои, которые затрагивают всю строку, столбец или блок, составляют более 40% всех сбоев DRAM. В-третьих, мы обнаружили, что почти 5% отказов DRAM влияют на схемы на уровне платы, такие как линии данных (DQ) или стробирования (DQS). Наконец, мы обнаружили, что функция Chipkill уменьшила частоту отказов системы, вызываемих сбоями DRAM, в 36 раз.
Цитата кажется несколько ироничной, поскольку она выглядит не аргументом против ECC, а аргументом за Chipkill — определённый класс ECC. Отложив это в сторону, пост Джеффа указывает, что систематические ошибки встречаются в два раза чаще, чем ошибки случайные. Затем пост сообщает, что они запускают memtest на своих машинах, когда происходят систематические ошибки.
Во-первых, соотношение 2:1 не столь велико, чтобы просто игнорировать случайные ошибки. Во-вторых, пост подразумевает веру Джеффа, что систематические ошибки, по существу, неизменны и не могут проявиться через некоторое время. Это неверно. Электроника изнашивается точно так же, как изнашиваются механические устройства. Механизмы разные, но эффекты схожи. Действительно, если сравнить анализ надёжности чипов с другими видами анализа надёжности, то можно видеть, что они часто используют одни и те же семейства распределений для моделирования отказов. В-третьих, ход рассуждений Джеффа подразумевает, что ECC не может помочь в обнаружении или исправлении ошибок, что не только неверно, но и прямо противоречит цитате.
Итак, как часто вы собираетесь запускать memtest на своих машинах в попытках поймать эти системные ошибки и сколько потерь данных вы готовы пережить? Одно из ключевых применений ECC состоит не в том, чтобы исправить ошибки, а в том, чтобы сигнализировать об ошибках, благодаря чему оборудование может быть заменено до того, как произойдёт «silent corruption» («скрытое повреждение данных»). Кто согласится закрывать всё на машине каждый день, чтобы запустить memtest? Это было бы намного дороже, чем просто купить ECC-память. И даже если бы вы смогли убедить гонять тестирование памяти, memtest не обнаружил бы столько ошибок, сколько сможет найти ECC.
Когда я работал в компании с парком в примерно тысячу машин, мы заметили, что у нас происходят странные отказы при проверке целостности данных, и примерно через полгода мы поняли, что отказы на одних машинах более вероятны, чем на других. Эти отказы были довольно редкими (может быть, пару раз в неделю в среднем), поэтому потребовалось много времени для накопления информации и понимания, что же происходит. Без знания причины анализ логов с целью понять, что ошибки были вызваны единичными случаями инвертирования битов (с большой вероятностью), также был нетривиальным. Нам повезло, что в качестве побочного эффекта процесса, который мы использовали, контрольные суммы вычислялись в отдельном процессе на другой машине в разное время, так что ошибка не могла исказить результат и распространить это повреждение на контрольную сумму.
Если вы просто пытаетесь защитить себя с помощью контрольных сумм в памяти, есть немалая вероятность того, что вы выполните операцию вычисления контрольной суммы на уже повреждённых данных и получите правильную контрольную сумму неправильных данных, если только вы не делаете некоторые действительно необычные операции с вычислениями, которые дают их собственные контрольные суммы. А если вы серьёзно относитесь к исправлению ошибок, то вы, вероятно, всё же используете ECC.
Во всяком случае, после завершения анализа мы обнаружили, что memtest не мог обнаружить какие-либо проблемы, но замена ОЗУ на плохих машинах привела к уменьшению частоты ошибок на один-два порядка. У большинства сервисов нет такого рода контрольных сумм, которые были у нас; эти сервисы будут просто молча записывать повреждённые данные в постоянное хранилище и не увидят проблему, пока клиент не начнёт жаловаться.
3. Благодаря развитию аппаратного обеспечения ошибки стали очень редкими
Данных в посте недостаточно для такого утверждения. Обратите внимание, что поскольку использование ОЗУ возрастает и продолжает увеличиваться экспоненциально, отказы ОЗУ должны уменьшаться с большей экспоненциальной скоростью, чтобы фактически уменьшить частоту повреждения данных. Кроме того, поскольку чипы продолжают уменьшаться, элементы становятся меньше, что делает более актуальными проблемы износа, обсуждаемые во втором пункте. Например, при технологии 20 нм конденсатор DRAM может накпливать где-то электронов 50, и это число будет меньше для следующего поколения DRAM при сохранении тенденции уменьшения.
Исследование 2012 года, которое цитирует Этвуд, имеет этот график по исправленным ошибкам (подмножество всех ошибок) на десяти случайно выбранных отказавших узлах (6% узлов имели по крайней мере один отказ):

Рис. 1. Исправленные за месяц ошибки для выбранных случайным образом узлов. Количество ошибок показывает тип сбоя, возникший в каждом узле.
Речь идёт о количестве ошибок от 10 до 10 тыс. для типичного узла, у которого происходит отказ, и это — тщательно отобранное исследование с поста, утверждающего, что вам не нужна память ECC. Обратите внимание, что здесь рассматриваются узлы с ОЗУ только 16 ГБ, что на порядок меньше, чем у современных серверов, и что исследование было проведено на более старом техпроцессе, который был менее уязвим для шума, чем нынешний.
Для тех, кто привык иметь дело с проблемами надёжности и просто хочет знать значение FIT (единица измерения интенсивности отказов): исследование показывает, что значение FIT составляет 0,057-0,071 сбоев на один мегабит (что — в противоположность утверждению Этвуда — не является поразительно низким числом).
Если взять самое оптимистичное значение FIT, равное 0,057, и провести расчёт для сервера не с самой большой оперативной памятью (здесь я использую 128 ГБ, поскольку серверы, которые я вижу в настоящее время, обычно имеют ОЗУ от 128 до 1,5 ТБ), то получим ожидаемое значение 0,057 * 1 000 * 1 000 * 8 760 /1 000 000 000 = 0,5 сбоя в год на каждый сервер. Обратите внимание, что это относится к сбоям, а не к ошибкам. Из графика выше видно, что сбой может легко вызвать сотни или тысячи ошибок в месяц. Ещё нужно отметить, что есть несколько узлов, у которых нет ошибок в начале исследования, но ошибки появляются позже.
Компания Sun/Oracle серьёзно столкнулась с этим несколько десятилетий назад. Транзисторы и конденсаторы DRAM становились всё меньше, как это происходит и сейчас, а использование памяти и кэши росли, так же как и в настоящее время. Столкнувшись, с одной стороны, со всё уменьшающимся транзистором, который был менее стойким к временному нарушению и более сложным в изготовлении, а, с другой стороны, с растущим встроенным кэшем, подавляющее большинство поставщиков серверов ввело ECC в свои кэши. Компания Sun решила сэкономить несколько долларов и не использовать ECC. Прямым результатом было то, что ряд клиентов Sun сообщил о периодических повреждении данных. В результате затем Sun несколько лет занималась разработкой новой архитектуры с кэшем на ECC и заставляла клиентов подписывать NDA для замены чипов.
Конечно, невозможно постоянно скрывать подобные вещи, и когда они всплыли, репутация Sun по созданию надёжных серверов получила сильный удар, во многом похожий на случай, когда Sun пыталась скрыть плохие показатели производительности, введя в свои условия использования запрет на бенчмарки.
Ещё одно замечание: когда вы платите за ECC, вы платите не просто за память ECC — вы платите за детали (процессоры, платы), которые являются более качественными. Такое легко можно видеть с частотой отказа дисков, и я слышал, что многие замечают такое в своих личных наблюдениях.
Если приводить общедоступные исследования: насколько помню, группа Андреа и Ремзи несколько лет назад выпустила документ SIGMETRICS, который показал, что вероятность сбоя при чтении у диска SATA в 4 раза выше, чем у диска SCSI, а вероятность скрытого повреждения данных — в 10 раз выше. Это соотношение сохранялось даже при использовании дисков одного изготовителя. Нет особой причины думать, что интерфейс SCSI должен быть более надёжным, чем интерфейс SATA, но речь идёт не об интерфейсе. Речь идёт о покупке высоконадёжных серверных компонентов по сравнению с клиентскими. Возможно, конкретно надёжность диска вас не интересует, потому что у вас всё на контрольных суммах, и повреждения легко находятся, но есть некоторые виды нарушений, которые обнаружить труднее.
4. Если бы память ECC имела, действительно, важное значение, то её использовали бы везде, а не только в серверах.
Немного перефразируя этот аргумент, можно сказать, что «если бы эта характеристика была, действительно, важна для серверов, то она использовалась бы и в не-серверах». Можно применить этот аргумент к довольно большому количеству аппаратных средств сервера. На самом деле это одна из наиболее неприятных проблем, стоящих перед крупными поставщиками облачных решений.
У них достаточно рычагов воздействия, чтобы получать большинство компонентов по подходящей цене. Но поторговаться получится только там, где есть более одного жизнеспособного поставщика.
Одной из немногих областей, где нет каких-либо жизнеспособных конкурентов, является производство центральных процессоров и видеоускорителей. К счастью для крупных поставщиков, видеоускорители им обычно не нужны, нужны процессоры, много — уже давно так сложилось. Было несколько попыток поставщиков процессоров войти на серверный рынок, но всегда каждая такая попытка с самого начала имела фатальные недостатки, делавшие очевидной её обречённость (а это часто проекты, требующие не менее 5 лет, т.е. необходимо было потратить очень много времени без уверенности в успехе).
Усилия Qualcomm получили много шума, но, когда я общаюсь с моими контактами в Qualcomm, они все говорят мне, что сделанный в данный момент чип предназначен, по существу, для пробы. Так получилось, потому что компании Qualcomm нужно было узнать, как сделать серверный чип, у всех тех специалистов, которых она переманила из IBM, и что следующий чип будет первым, который, можно надеяться, станет конкурентоспособным. Я возлагаю большие надежды на Qualcomm, а также на усилия ARM по созданию хороших серверных компонентов, но эти усилия пока не дают желаемого результата.
Почти полная непригодность текущих вариантов ARM (и POWER) (не считая гипотетических вариантов впечатляющего чипа ARM от Apple) для большинства рабочих нагрузок серверов с точки зрения производительности на доллар совокупной стоимости владения (TCO) — эта тема немного в стороне, поэтому я оставлю её для другой публикации. Но дело в том, что Intel имеет такую позицию на рынке, что может заставить людей платить сверху за серверные функции. И Intel это делает. Кроме того, некоторые функции действительно важнее для серверов, чем для мобильных устройств с несколькими гигабайтами оперативной памяти и энергетическим бюджетом в несколько ватт, мобильных устройств, от которых всё равно ожидают периодические вылеты и перезагрузки.
Заключение
Следует ли покупать ECC-ОЗУ? Это зависит от многого. Для серверов это, вероятно, хороший вариант, учитывая затраты. Хотя на самом деле трудно провести анализ затрат/выгод, потому что довольно сложно определить ущерб от скрытого повреждения данных или затраты на риск потерять полгода времени разработчика на отслеживание перемежающихся сбоев, только чтобы обнаружить, что они вызваны использованием памяти без ECC.
Для настольных компьютеров я тоже сторонник ECC. Но если вы не делаете регулярные бэкапы, то вам полезнее вложиться в регулярные бэкапы, чем в ECC-память. И если у вас есть резервные копии без ECC, то вы можете легко записать повреждённые данные в основное хранилище и реплицировать эти повреждённые данные в резервную копию.
Спасибо Прабхакару Рагде, Тому Мерфи, Джею Вайскопфу, Лии Хансон, Джо Уайлдеру и Ральфу Кордерою за обсуждение / комментарии / исправления. Кроме того, спасибо (или, может быть, не-спасибо) Лии за то, что убедила меня написать этот устный экспромт как пост в блоге. Приносим извинения за любые ошибки, отсутствие ссылок и возвышенную прозу; это, по существу, запись половины обсуждения, и я не объяснил условия, не предоставил ссылки или не проверил факты на том уровне детализации, как я обычно делаю.
1. Одним из забавных примеров является (по крайней мере, для меня) магическая самовосстанавливающаяся плавкая перемычка. Хотя реализаций много, представим себе плавкую перемычку на чипе как некоторый резистор. Если вы пропускаете через неё какой-то ток, то вы должны получить соединение. Если ток слишком большой, то резистор разогреется и, в конце концов, разрушится. Это обычно используется для отключения элементов на микросхемах или для таких действий, как задание тактовой частоты. Основной принцип состоит в том, что после сгорания перемычки нет возможности вернуть её в исходное состояние.
Давным давно жил да был производитель полупроводниковых устройств, который немного поторописля со своим производственным процессом и несколько чрезмерно уменьшил допуски в некотором технологическом поколении. Через несколько месяцев (или лет) соединение между двумя концами подобной перемычки смогло снова появиться и восстановить его. Если вам повезёт, то такая перемычка будет чем-то вроде старшего бита множителя тактовой частоты, который в случае его изменения будет выводить чип из строя. Если не повезёт, то это приведёт к скрытому повреждению данных.
Я слышал от многих людей в разных компаниях о проблемах в этом технологическом поколении этого производителя, так что это не были отдельные случаи. Когда я говорю, что это забавно, я имею в виду, что забавно услышать эту историю в баре. Менее забавно обнаружить через год тестирования, что некоторые из ваших чипов не работают, потому что их установки для перемычек бессмысленны, и необходимо переделать ваш чип и отложить выпуск на 3 месяца. Кстати, эта ситуация с восстановлением плавкой перемычки — ещё один пример класса ошибок, остроту которых можно сгладить с помощью ECC.
Это не проблема Google; я упоминаю об этом только потому, что многие люди, с которыми я общаюсь, удивлены тем, каким образом аппаратное обеспечение может выйти из строя.
2. Если вы не хотите копаться во всей книге, то вот нужный фрагмент:
В системе, которая может выдержать ряд отказов на программном уровне, минимальное требование, предъявляемое к аппаратной части, заключается в том, что сбои этой части всегда обнаруживаются и сообщаются программному обеспечению достаточно своевременно, чтобы позволить программной инфраструктуре ограничить их и принять соответствующие действия по восстановлению. Необязательно, чтобы аппаратное обеспечение явно справлялось со всеми сбоями. Это не означает, что оборудование для таких систем должно быть спроектировано без возможности исправления ошибок. Всякий раз, когда функциональные возможности исправления ошибок могут быть предложены с разумной ценой или сложностью, поддержка их часто окупается. Это означает, что, если аппаратная коррекция ошибок была бы чрезвычайно дорогостоящей, то система могла бы иметь возможность использования более дешёвой версии, которая предоставляла бы возможности только обнаружения. Современные системы DRAM являются хорошим примером ситуации, в которой мощная коррекция ошибок может быть предоставлена при очень низких дополнительных затратах. Однако смягчение требования об обнаружении аппаратных ошибок было бы намного сложнее, поскольку это означало бы, что каждый программный компонент был бы обременён необходимостью проверки его собственного правильного выполнения. На начальном этапе своей истории Google пришлось иметь дело с серверами, на которых у DRAM отсутствовал даже контроль чётности. Создание индекса веб-поиска состоит, по существу, из очень большой операции сортировки/слияния, использующей длительно несколько машин. В 2000 году одно из ежемесячных обновлений веб-индекса Google не прошло предварительную проверку, когда обнаружилось, что некоторое подмножество проверенных запросов возвращает документы, по-видимому, случайным образом. После некоторого исследования в новых индексных файлах была выявлена ситуация, которая соответствовала фиксации бита на нуле в определённом месте в структурах данных, что было негативным побочным эффектом потоковой передачи большого количества данных через неисправный чип DRAM. В структуры данных индекса были добавлены проверки непротиворечивости, чтобы свести к минимуму вероятность повторения этой проблемы, и в дальнейшем проблем такого характера не было. Однако следует отметить, что этот способ не гарантирует 100% обнаружения ошибок в проходе индексации, так как не все позиции памяти проверяются — инструкции, например, остаются без проверки. Это сработало потому, что структуры данных индекса были настолько больше, чем все другие данные, участвующие в вычислении, что наличие этих самоконтролируемых структур данных делало очень вероятным, что машины с дефектным DRAM будут идентифицированы и исключены из кластера. Следующее поколение машин в Google уже содержало обнаружение чётности в памяти, и как только цена памяти с ECC опустилась до конкурентного уровня, все последующие поколения использовали ECC-DRAM.
